前言
在前面的几篇文章中,介绍了全链路压测的背景、在企业中的立项流程以及落地的一些技术方案。在开始真正的介绍落地实践过程以及相关案例之前,我想和大家聊聊,我对全链路压测的一些认知,即:全链路压测在技术团队中的定位,以及它的价值是什么。
业务和技术是什么关系?
在聊这个topic之前,先回想下我在第一篇文章中阐述的一个观点:全链路压测创造了什么价值?我当时的观点:
技术角度:降低成本、提升系统SLA、技术练兵&团队协作&快速响应;
业务角度:提升用户体验、更快的发现和验证目标、更好的达成业务运营目标;
现在我要表述的观点依然不变,从更高维度来说,技术和业务的关系可以用下面一句话概括:
技术是为业务达成目标提供支撑和效率工具,业务目标更好的达成会对技术有更高的要求!
技术的目标:支撑业务运营

业务本身的特性主要有如下几点:
- 精细化运营(需要准确的数据);
- 成本和效率(更低的成本和更高的收益);
- 更好的服务用户(需要快速高效的解决用户的痛点问题);
- 新的业务可以快速落地验证(需要高效的技术响应和技术支撑);
而上述几点业务的特性,都对技术提出了很多的要求!
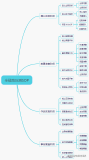
技术如何支撑业务运营增长

从上图可以看出,常见的业务运营流程中,每个阶段每个环节都对技术部门提出了挑战:
- 从需求提出到发布
- 研发成本、研发效率、交付质量;
- 从下单到订单履约
- 提高业务成交履约率(撮合交易/成单匹配/留存转化);
- 业务活动的营销推广
- 活动搭建、抽奖&优惠券&营销短信等方面的快速响应;
- 线上故障的快速发现解决
- 监控告警、问题定位、风险评估、线上服务的SLA;
业务的目标:运营业务增长
前面聊了技术对业务运营的重要支撑作用,这里我们看看常见的业务场景,具备的几种特性:
- 业务可视
- 业务的可视,简单理解就是业务的状态,处在什么阶段,目前的效果可以直观的以可视化的状态来呈现,常见的场景就是业务监控大盘(想想监控大盘需要技术做什么?数据采集/数据存储/数据展示)
- 业务可管
- 最常见的就是一些促销活动的配置,比如活动时间、涉及的商品/优惠券、用户类型以及标签体系(这里又需要技术做什么呢?活动会场搭建工具/优惠信息缓存/活动消息推送)
- 业务可控
- 业务可控也可以通过字面意思理解,即:各个业务维度的运行监控/业务配置发布回滚以及防资损;
- 业务可优
- 这一点,我们现在最常见的有电商的千人千面,短视频的智能推荐、针对不同等级会员的优惠营销体系等;
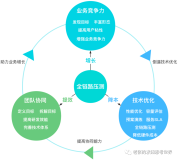
技术支撑业务运营增长案例
上面讲了业务的特性以及技术对业务运营支撑的重要性,这些内容可以用下面这张图概括:

稳定性保障面临的六大挑战
上面第一部分的内容介绍了技术和业务的关系,业务的运营增长目标想要达成,线上系统的稳定性也是至关重要的。那么如何保障线上系统的稳定性呢?稳定性保障面临哪些挑战?我们以电商最典型的大促来举例说明。

从上图可以看到,大促时候的线上系统稳定性保障,面临六大挑战,分别是:
系统容量
大促的典型特点是流量大,对系统的冲击比较高。那么精准的测量线上系统的容量,对处理能力薄弱的节点进行扩容升配,优化性能就是很有必要的。
现在很多的系统都是分布式或微服务架构,这种复杂的技术体系面临大流量冲击时,需要精准的容量评估和容量规划,想要达成这种能力,就需要一种很好的技术手段来不断验证。生产环境全链路压测,就是目前业内的最佳实践。
硬件成本
前面聊到了容量评估和容量规划,这和硬件成本有什么关系呢?可能很多同学都不知道,现在的互联网企业,最大的成本支出都是哪些?成本支出主要是这三方面:人力研发成本、营销成本和云资源成本。
其中,人力研发成本的优化是很复杂的一件事,营销成本是企业最主要的品牌曝光和拉新运营手段。云资源成本,也可以理解为云服务器或者机房的硬件成本。这三部分成本中,云资产/硬件成本是可以通过技术手段来降低的。技术手段,实际上上面已经讲到了,就是精准的容量评估和容量规划。
系统稳定
系统的稳定性,如何衡量?目前业内大多从下面这几个维度来衡量:
- 线上服务可用时长
- 服务可用时长即我们常说的SLA(即服务等级协议,全称:service level agreement)。SLA对互联网公司来说就是网站服务可用性的一个保证。9越多代表全年服务可用时间越长服务更可靠,停机时间越短,反之亦然。服务可用性可以通过下面的例子来理解:
全年拿365天做计算,看看几个9要停机多久时间做能才能达到!
1年 = 365天 = 8760小时
99.9 = 8760 * 0.1% = 8760 * 0.001 = 8.76小时
99.99 = 8760 * 0.0001 = 0.876小时 = 0.876 * 60 = 52.6分钟
99.999 = 8760 * 0.00001 = 0.0876小时 = 0.0876 * 60 = 5.26分钟
- 故障响应解决耗时
- 这一点目前业内有个口号是:1-5-15。什么意思呢,就是:
一分钟发现问题,5分钟定位问题,15分钟解决问题,线上业务恢复正常运营。
要做到上述的指标需要很强的技术能力以及不断的演练才能达到,主要是如下几点:
- 发现问题:强大完善灵敏的监控体系;
- 定位问题:对业务和技术实现的熟悉程度以及高效的定位分析工具;
- 解决问题:故障的自愈能力以及对异常情况的稳定性预案甚至故障演练;
- 故障导致的业务资损
- 这一点很好理解,即线上故障对业务造成的损失。这一点业内在故障定级评估复盘时,大多采用最近一天/一周同时段的业务营收来做对比,当然,其中还可能包括用户的客诉以及赔偿的优惠券等维度。
技术能力
要保障线上服务稳定性,除了容量评估/故障演练/全链路压测外,还需要其他技术手段如:
- 弹性扩缩容能力;
- 监控告警追踪能力;
- 限流降级熔断能力;
- 故障识别响应和技术优化;
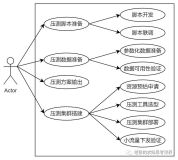
大促效率
我们以电商的大促举例子,要做到保障大促平稳度过,需要很多团队和角色的协调配合才能达成。可以通过下图来看看,大促保障涉及的团队和要做的事情:

这种跨团队的协调配合,往往需要动员很多人力资源,而且特别耗时。
沟通协同
为什么这里要讲到沟通协同呢?看看上一个标题我所描述的内容,相信大家在日常工作也有感触:和不同的角色沟通需求、目标、时间节点,协调资源、风险评估、解决问题,是一件特别费力费脑的事情。
全链路压测对稳定性保障的价值
聊了这么多,回到文章顶部,我所要表达的内容,全链路压测的价值是什么?
在我看来,全链路压测不仅仅是一种很好的性能测试和优化手段,而是在整个稳定性保障中,起到了串联全过程的能力。通过生产全链路压测,可以串联稳定性保障的全流程,解决线上系统稳定性保障面临的种种挑战,它所带来的价值如下:

总结回顾
这篇文章介绍了我对技术和业务关系的理解,线上稳定性保障面临的挑战以及全链路压测在其中的价值,通过前面的几篇文章,从认识全链路压测到项目立项以及技术调研和测试验证,我试图从另一个视角来为大家揭秘全链路压测的另一面。下篇文章,我会为大家介绍,全链路压测落地实践的整体流程。