
1.实验目的
(1)掌握分支限界法的处理思路与算法框架。
(2)掌握应用分支限界法解决具体问题的方法。
(3)掌握分支限界法的广泛应用。
2.实验内容
(1)问题描述

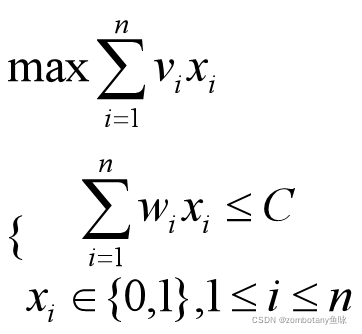
要求使用分支限界法解决该问题。
(2)输入
输入包含3行。

(3)输出

3.问题实例分析


堆(优先队列)是大根堆,“优先级”即判断函数为价值上界。
此时大根堆堆顶为(“拿1,上界14.33”)。对其进行扩展,以是否拿2作为区分的依据。拿2时,价值上界为14.33。不拿2时,价值上界为14。将这两个结点都加入堆(优先队列)。
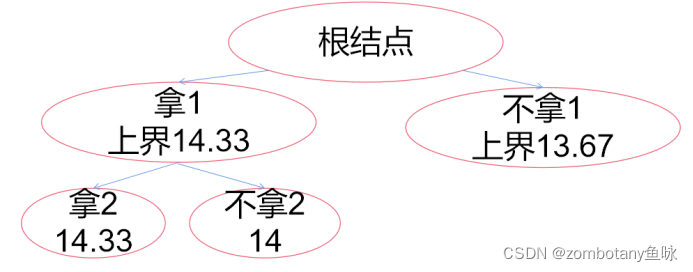
此时大根堆堆顶为“拿2,上界14.33”。对其进行扩展,以是否拿3作为区分依据。拿3时,价值上界为14.33。不拿3时,价值上界为14。将这两个结点都加入堆(优先队列)。
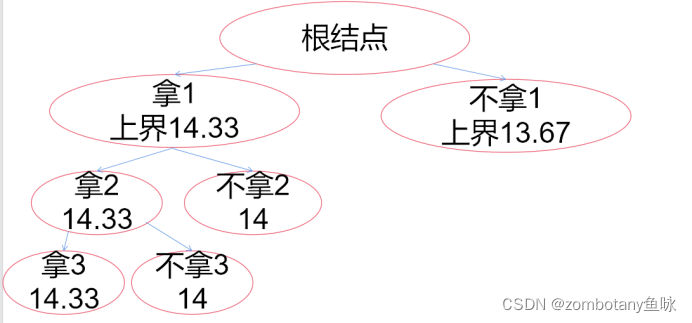
此时大根堆堆顶为“拿3,上界14.33”。对其进行扩展,以是否拿4作为区分依据。拿4时,背包此时体积超过上限,不可行。不拿4时,价值上界为14.25。将可行的右结点加入堆(优先队列)。

此时大根堆堆顶为“不拿4,上界14.25”。对其进行扩展,以是否拿5作为区分依据。拿5时,背包此时体积超过上限,不可行。不拿5时,价值上界为13。将可行的右结点加入堆(优先队列)。
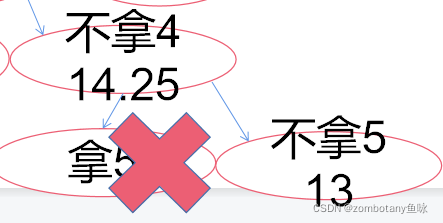
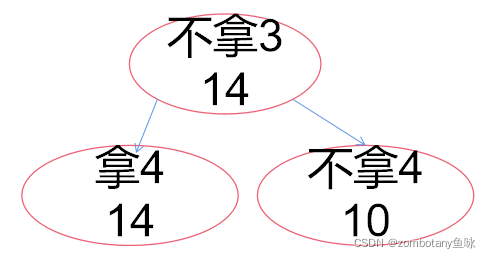
此时大根堆堆顶为“不拿3,上界14”。对其进行扩展,以是否拿4作为区分依据。拿4时,价值上界为14。不拿4时,价值上界为10。这两个结点都可行,都加入堆(优先队列)。
此时大根堆堆顶为“拿4,上界14”。对其进行扩展,以是否拿5作为区分依据。拿5时,价值上界为14。不拿5时,价值上界为9。这两个结点都可行,都加入堆(优先队列)。


4.算法描述及说明
正如第3节问题实例分析所述,算法的整体流程如下:
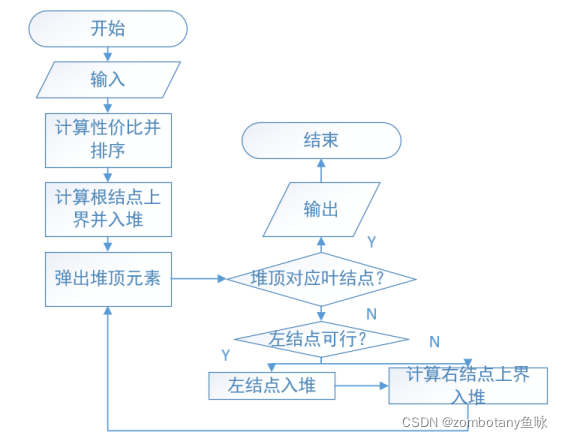
1.输入数据,并对每个物品进行编号。
2.计算每个物品的单位价值,并将物品按单位价值排序。
3.计算根结点上界,并将根结点加入大根堆。
4.取出堆顶元素。若堆顶结点为解空间树的叶结点,则算法直接结束,叶结点的物品选取信息和价值为所求的最大价值。
5.若堆顶元素不是叶结点,则尝试扩展左结点。若左结点可行(选取该物品背包体积没有被超出),则对左结点计算上界后入堆。扩展右结点,不选取物品,对右结点计算上界后入堆。
5.算法正确性分析
算法会正确地结束:在利用优先队列遍历解空间后,找到了使总价值最大的解,算法会停止。
分支限界的正确性分析:开始时,根结点是解空间树唯一的活结点,也是当前的扩展结点。算法会不断扩展结点,直到子集树的一个叶结点成为扩展结点时为止。此时优先队列中所有活结点的价值上界不超过该叶结点的价值。因此,该叶结点对应的解为问题最优解。
因此,利用分支限界法会系统地查找背包问题的所有可行解,利用限界函数剪去了不可行的分支,保留了可行并能产生最大解的分支。
从而,该算法是正确的。
6.算法时间复杂性分析

7.运行结果展示及其说明



8.心得体会
9.程序源代码
#include<iostream> #include<algorithm> #include<queue> using namespace std; double cw;//当前重量 double cp;//当前价值 double bestp;//当前最优价值 int n;//物品数量 double c;//背包容量 const int N = 105; struct Bag { double w, v; int id, x; }; int bestx[N]; Bag bag[N]; struct BBnode { BBnode *parent; bool leftChild; BBnode(BBnode* par, bool ch) { parent = par; leftChild = ch; } }; struct heapnode { BBnode* livenode; double upperprofit;//价值上界 double profit;//结点价值 double weight;//结点重量 int level;//层序号 bool operator<(const heapnode& b) const { return this->upperprofit < b.upperprofit; } heapnode(BBnode *node,double up, double pp, double ww, int lev) { livenode = node; upperprofit = up; profit = pp; weight = ww; level = lev; } }; bool cmp(Bag a, Bag b) { return (a.v / a.w) > (b.v / b.w); } bool cmpbound(heapnode a, heapnode b) { return a.upperprofit < b.upperprofit; } priority_queue<heapnode, vector<heapnode>,less<heapnode> > q; void addlivenode(double up, double pp, double ww, int lev, BBnode* par, bool ch) { BBnode* b = new BBnode(par, ch); heapnode node(b, up, pp, ww, lev); q.push(node); } double bound(int i) { double cleft = c - cw; double bd = cp; while (i <= n && bag[i].w <= cleft) { cleft -= bag[i].w; bd += bag[i].v; i++; } if (i <= n) bd += bag[i].v * cleft / bag[i].w; return bd; } void bfs() { BBnode *enode = NULL; int i = 1; bestp = 0; double up = bound(1); while (i != n + 1) { double wt = cw + bag[i].w; if (wt <= c) { if (cp + bag[i].v > bestp) bestp = cp + bag[i].v; addlivenode(up, cp + bag[i].v, cw + bag[i].w, i + 1, enode, true); } up = bound(i + 1); if (up > bestp) addlivenode(up, cp, cw, i + 1, enode, false); heapnode node = q.top(); q.pop(); enode = node.livenode; cw = node.weight; cp = node.profit; up = node.upperprofit; i = node.level; } for (int j = n; j > 0; j--) { bag[j].x = (enode->leftChild!=NULL) ? 1 : 0; enode = enode->parent; } for (int i = 1; i <= n; i++) bestx[bag[i].id] = bag[i].x; return; } int main() { cin >> n >> c; for (int i = 1; i <= n; i++) cin >> bag[i].w; for (int i = 1; i <= n; i++) cin >> bag[i].v; for (int i = 1; i <= n; i++) bag[i].id = i; sort(bag + 1, bag + 1 + n, cmp); bfs(); cout << bestp << endl; for (int i = 1; i <= n; i++) cout << bestx[i] << " "; return 0; }


