3D视觉Transformer
随着3D采集技术的快速发展,双目/单目图像和LiDAR(Light Detection and Ranging)点云成为3D识别的流行传感数据。与RGB(D)数据不同,点云表示更关注距离、几何图形和形状信息。值得注意的是,由于其稀疏性、无序性和不规则性的特点,这种几何特征非常适合Transformer。随着2D ViT的成功,开发了大量的3D分析方法。本节展示了3D ViT在表示学习、认知映射和特定处理之后的简要回顾。
表示学习
与传统的手工设计的网络相比,ViT更适合于从点云学习语义表示,在点云中,这种不规则和排列不变的性质可以转化为一系列具有位置信息的并行嵌入。鉴于此,Point Transformer[105]和PCT[106]首先证明了ViT对3D表示学习的有效性。前者将hierarchical Transformer[105]与下采样策略[203]合并,并将其先前的vector attention block[25]扩展到3D点云。后者首先聚集相邻点云,然后在全局off-set Transformer上处理这些相邻嵌入,其中来自图卷积网络(GCN)的知识迁移被应用于噪声缓解。值得注意的是,由于点云的固有坐标信息,位置编码(ViT的重要操作)在两种方法中都有所减少。PCT直接处理坐标,无需位置编码,而Point Transformer添加了可学习的相对位置编码以进一步增强。继[105]、[106]之后,Lu等人利用local-global聚合模块3DCTN[107]来实现局部增强和成本效率。给定多步长下采样组,使用具有max-pooling操作的显式图卷积来聚合每个组内的局部信息。将得到的组嵌入级联并馈送到改进的Transformer[105]、[106]中,用于全局聚合。Park等人提出了Fast Point Transformer[108],通过使用voxel-hashing邻域搜索、体素桥接相对位置编码和基于余弦相似性的局部关注来优化模型效率。
为了进行密集预测,Pan等人提出了一种定制的基于点云的Transformer主干(Pointformer)[109],用于在每个层中分别参与局部和全局交互。与以往的局部-全局形式不同,采用局部关注后的坐标细化操作来更新质心点而不是曲面点。局部-全局交叉注意力模型融合了高分辨率特征,然后是全局注意力。Fan等人返回到Single-stride Sparse Transformer(SST)[110],而不是下采样操作,以解决小目标检测的问题。与Swin[35]类似,连续Transformer块中的移位组被用于分别处理每组token,这进一步缓解了计算问题。在基于体素的方法中,Voxel Transformer(VoTr)[111]采用两步voxel Transformer来有效地操作空和非空体素位置,包括通过local attention和dilated attention。VoxSeT[112]进一步将self-attention分解为两个交叉关注层,一组潜在编码将它们链接起来,以在隐藏空间中保存全局特征。
一系列自监督Transformer也被扩展到3D空间,例如Point BERT[113]、Point MAE[114]和MaskPoint[115]。具体而言,Point BERT[113]和Point MAE[114]直接将先前的工作[70]、[71]转移到点云,而MaskPoint[115]通过使用与DINO(2022)[91]类似的对比解码器来改变生成训练方案,以进行自训练。基于大量实验,论文得出结论,这种生成/对比自训练方法使ViT能够在图像或点云中有效。
Cognition Mapping
鉴于丰富的表示特征,如何将实例/语义认知直接映射到目标输出也引起了相当大的兴趣。与2D图像不同,3D场景中的目标是独立的,可以由一系列离散的表面点直观地表示。为了弥补这一差距,一些现有的方法将领域知识转移到2D主流模型中。继[30]之后,3DETR[116]通过最远点采样和傅里叶位置嵌入将端到端模块扩展到3D目标检测,以用于object queries初始化。Group Free 3D DETR[117]应用了比[116]更具体和更强的结构。详细地说,当object queries时,它直接从提取的点云中选择一组候选采样点,并在解码器中逐层迭代地更新它们。Sheng等人提出了一种典型的两阶段方法,该方法利用Channel-wise Transformer3D检测器(CT3D)[118]同时聚合每个提案中的点云特征的proposal-aware嵌入和channel-wise上下文信息。
对于单目传感器,MonoDTR[119]和MonoDETR[120]在训练过程中使用辅助深度监督来估计伪深度位置编码(DPE)。DETR3D[121]引入了一种多目3D目标检测范式,其中2D图像和3D位置都通过摄像机变换矩阵和一组3D object queries相关联。
TransFusion[122]通过连续通过两个Transformer解码器层与object queries交互,进一步利用了LiDAR点和RGB图像的优点。
Specific Processing
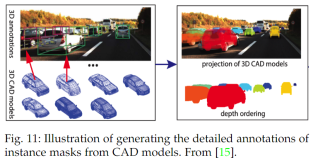
受传感器分辨率和视角的限制,点云在真实场景中存在不完整、噪声和稀疏性问题。为此,PoinTr[123]将原始点云表示为一组局部点云代理,并利用几何感知编码器-解码器Transformer将中心点云代理向不完整点云方向迁移。SnowflakeNet[124]将点云补全的过程公式化为类似雪花的生长,它通过point-wise splitting deconvolution策略从父点云逐步生成子点云。相邻层的skip-Transformer进一步细化父层和子层之间的空间上下文特征,以增强它们的连接区域。Choe等人将各种生成任务(例如降噪、补全和超分辨率)统一为点云重构问题,因此称为PointRecon[125]。基于体素散列,它覆盖了绝对尺度的局部几何结构,并利用PointTransformerlike[105]结构将每个体素(query)与其相邻体素(value-key)进行聚合,以便从离散体素到一组点云集进行细粒度转换。此外,增强的位置编码适用于体素局部attention方案,通过使用L1损失的负指数函数作为朴素位置编码的权重来实现。值得注意的是,与masked生成自训练相比,补全任务直接生成一组完整点云,而不需要不完整点云的显式空间先验。
多传感器数据流Transformer
在现实世界中,多个传感器总是互补使用,而不是单个传感器。为此,最近的工作开始探索不同的融合方法,以有效地协同多传感器数据流。与典型的CNN相比,Transformer自然适合于多流数据融合,因为它的非特定嵌入和动态交互注意机制。本节根据数据流源(同源流和异源流)详细介绍了这些方法。
Homologous Stream
同源流是一组具有相似内在特征的多传感器数据,如多视图、多维和多模态视觉流数据。根据融合机制,它们可以分为两类:交互融合和迁移融合。
交互融合:CNN的经典融合模式采用channel级联操作。然而,来自不同模态的相同位置可能是各向异性的,这不适合CNN的平移不变偏差。相反,Transformer的空间级联操作使不同的模态能够超越局部限制进行交互。
对于局部交互,MVT[126]在空间上连接来自不同视图的patch嵌入,并通过使用模式不可知的Transformer来加强它们的交互。为了减轻多模态特征的冗余信息,MVDeTr[127]将特征图的每个视图投影到地平面上,并将多尺度可变形注意力[76]扩展到多视图设计。其他相关算法TransFuser[128]、COTR[129]可参考论文。
对于全局交互,Wang等人[130]利用共享主干提取不同视图的特征。代替COTR[129]中的逐像素/逐patch级联,提取的逐视图全局特征在空间上进行级联,以在Transformer中进行视图融合。考虑到不同相机视图之间的角度和位置差异,TransformerFusion[132]首先将每个视图特征转换为具有其相机视图的内部和外部的嵌入向量。这些嵌入然后被馈送到global Transformer中,该global Transformer的注意力权重用于帧选择,以便有效地计算。为了在3D检测中统一多传感器数据,FUTR3D[131]将类DETR解码器中的object queries投影到一组3D参考点中云。这些点云及其相关特征随后从不同的模态中采样并在空间上连接以更新object queries。
迁移融合:与Transformer编码器通过self-attention实现的交互式融合不同,另一种融合形式更像是通过交叉关注机制从源数据到目标数据的迁移学习。例如,Tulder等人[133]在中间主干特征中插入了两个协作的交叉注意力Transformer,用于桥接未配准的多视图医学图像。代替pixel-wise 注意力形式,进一步开发了token-pixel交叉注意力,以减轻繁重的计算。Long等人[134]提出了一种用于多视图图像深度估计的对极时空Transformer。给定包含一系列静态多视点帧的单个视频,首先将相邻帧连接起来,然后将对极线扭曲到中心相机空间中。最终得到的帧volume作为源数据,通过交叉注意力与中心帧进行融合。对于空间对齐的数据流,DRT[135]首先通过使用卷积层显式地建模不同数据流之间的关系图。随后将生成的map输入到双路径交叉注意力中,以并行构建局部和全局关系,从而可以收集更多的区域信息用于青光眼诊断。
Heterologous Stream
ViT在异源数据融合方面也表现出色,尤其是在视觉语言表示学习方面。尽管不同的任务可能采用不同的训练方案,例如监督/自监督学习或紧凑/大规模数据集,但论文仅根据其认知形式将其分为两类:1)视觉语言-预训练,包括视觉-语言预训练(VLP)[204]和对比语言-图像预训练(CLIP)[146];2)Visual Grounding如Phrase Grounding(PG)、参考表达理解(REC)。更多比较见表五。
视觉-语言预训练:由于有限的标注数据,早期的VLP方法通常依赖于现成的目标检测器[204]和文本编码器[5]来提取数据特定的特征以进行联合分布学习。给定图像-文本对,在视觉基因组(VG)上预先训练的目标检测器[205]首先从图像中提取一组以目标为中心的RoI特征。然后将用作视觉标记的RoI特征与用于预定义任务预训练的文本嵌入合并。基本上,这些方法分为双流和单流融合。双流方法包括ViLBERT[137]、LXMERT[138]。单流方法包括VideoBERT[136]、VisualBERT[139]、VL-BERT[140]、UNITER[141]、Oscar[142]、Unified VLP[143]。然而,这些方法严重依赖于视觉提取器或其预定义的视觉词汇表,导致了降低VLP表达能力上限的瓶颈。一些算法如VinVL[145]、ViLT[144]、UniT[149]、SimVLM[150]尝试解决这个问题。除了传统的带有多任务监督的预训练方案外,另一条最新的对比学习路线已经开发出来。相关算法有CLIP[146]、ALIGN[148]、Data2Vec[151]。
Visual Grounding:与VLP相比,Visual Grounding具有更具体的目标信号监督,其目标是根据目标对象的相应描述来定位目标对象。在图像空间中,Modulated DETR(MDETR)[152]将其先前的工作[30]扩展到phrase grounding预训练,该训练在一个描述中定位并将边界框分配给每个instance phrase。其他相关算法Referring Transformer[155]、VGTR[154]、TransVG[153]、LanguageRefer[157]、TransRefer3D[158]、MVT 2022[159]、TubeDETR[160]可以参考具体论文。

讨论和结论
近期改进总结
- 对于分类,深度分层Transformer主干对于降低计算复杂度[41]和避免深层中的过平滑特征[37]、[42]、[66]、[67]是有效的。同时,早期卷积[39]足以捕获低层特征,这可以显著增强鲁棒性并降低浅层的计算复杂性。此外,卷积投影[54]、[55]和局部注意力机制[35]、[44]都可以改善ViT的局部性。前者[56]、[57]也可能是替代位置编码的新方法;
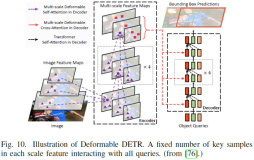
- 对于检测,Transformer neck从编码器-解码器结构中受益,其计算量比仅编码器Transformer 检测器少[87]。因此,解码器是必要的,但由于其收敛较慢,因此需要更多的空间先验[76],[80]–[85]。此外,前景采样的稀疏注意力[76]和评分网络[78]、[79]有助于降低计算成本并加速ViT的收敛;
- 对于分割,编码器-解码器Transformer模型可以通过一组可学习的mask embedding[31]、[103]、[202]将三个分割子任务统一为mask预测问题。这种box-free方法在多个基准测试中实现了最新的SOTA性能[202]。此外,特定的混合任务与基于框的ViT[100]级联,该模型在实例分割方面表现出了更高的性能;
- 对于3D视觉,具有评分网络的局部分层Transformer可以有效地从点云数据中提取特征。全局建模能力使Transformer能够轻松聚合曲面点,而不是复杂的局部设计。此外,ViT可以处理3D视觉识别中的多传感器数据,如多视图和多维数据;
- 视觉-语言预训练的主流方法已经逐渐放弃了预训练的检测器[144],并专注于基于大规模噪声数据集[148]的潜在空间中不同数据流之间的对齐[146]或相似性[151]。另一个问题是使下游视觉任务适应预训练方案,以进行zero-shot迁移[146];
- 最近流行的多传感器数据融合架构是单流方法,它在空间上连接不同的数据流并同时执行交互。基于单流模型,最近的许多工作致力于寻找一个潜在空间,使不同的数据流语义一致。
ViT的讨论
尽管ViT模型有了很大的发展,但“基本”理解仍然不够。因此,论文将重点审查一些关键问题,以获得深入和全面的理解。
Transformer如何弥合语言和视觉之间的鸿沟
Transformer最初是为机器翻译任务设计的[1],其中句子的每个单词都被视为表示高级语义信息的基本单元。这些词可以嵌入到低维向量空间中的表示中。对于视觉任务,图像的每个像素都不能携带语义信息,这与传统NLP任务中的特征嵌入不匹配。因此,将这种特征嵌入(即单词嵌入)转移到CV任务中的关键是构建图像到向量的转换并有效地保持图像的特征。例如,ViT[29]在强松弛条件下将图像转换为具有多个低层信息的patch嵌入。
Transformer、Self-Attention与CNN的关系
从CNN的角度来看,其inductive bias主要表现为局部性、平移不变性、权重共享和稀疏连接。这种简单的卷积内核可以在低级语义处理中高效地进行模板匹配,但由于过度的偏差,其上限低于Transformers。
从self-attention机制的角度来看,当采用足够数量的head时,它们理论上可以表示任何卷积层[28]。这种完全注意力操作可以结合局部和全局注意力,并根据特征关系动态生成注意力权重。尽管如此,它的实用性仍然不如SOTA CNN,因为精度更低,计算成本更高。
从Transformer的角度来看,Dong等人证明,当在没有short connection或FFN的深层上训练self-attention层时,self-attention表现出对“token uniformity”的强烈感应偏差[167]。可以得出结论,Transformer由两个关键组件组成:self-attention聚合token的关系,以及按位置的FFN从输入中提取特征。尽管ViT具有强大的全局建模能力,CNN可以有效地处理低级特征[39]、[58],增强ViT的局部性[53]、[81],并通过填充[56]、[57]、[172]附加位置特征。
不同视觉任务的可学习嵌入
各种可学习的嵌入被设计用于进行不同的视觉任务。从目标任务的角度来看,这些嵌入可以分为class token、object query和mask embedding。从结构上看,这些ViT主要采用两种不同的模式,编码器和编码器-解码器。如图15所示,每个结构由三个嵌入级别组成。在位置级别上,编码器Transformer中可学习嵌入的应用被分解为initial token[29]、[87]和later token[42]、[103],而可学习位置编码[30]、[81]、,[202]和可学习的解码器输入嵌入[76]被应用于编码器-解码器结构。在数量层面上,编码器仅设计应用不同数量的token。例如,ViT[29]、[40]家族和YOLOS[87]将不同数量的token添加到初始层中,而CaiT[42]和Segmenter[103]利用这些token来表示不同任务中最后几层的特征。在编码器-解码器结构中,解码器的可学习位置编码(object query[30]、[81]或mask embedding[202])被显式地加入到解码器输入[30],[202]或隐式地加入到解码器输入[80],[81]。与恒定输入不同,Deformable DETR[76]采用可学习嵌入作为输入,并关注编码器输出。

在多头注意力机制的启发下,使用多个初始token的策略有望进一步提高分类性能。然而,DeiT[40]指出,这些额外的token将朝着相同的结果收敛,并且不会对ViT有利。从另一个角度来看,YOLOS[87]提供了一种范例,通过使用多个初始token来统一分类和检测任务,但这种编码器的设计只会导致更高的计算复杂度。根据CaiT[42]的观察,较后的class token可以略微降低Transformer的FLOPs并提高性能(从79.9%提高到80.5%)。Segmenter[103]也展示了分割任务的策略效率。
与具有多个后期token的仅编码器Transformer不同,编码器-解码器结构减少了计算成本。它通过使用一小组object query(mask embedding)在检测[30]和分割[202]领域标准化了ViT。通过组合后期token和object query(mask embedding),像Deformable DETR[76]这样的结构,它将object query和可学习解码器嵌入(相当于后期token)作为输入,可以将不同任务的可学习嵌入统一到Transformer编码器解码器中。
未来研究方向
ViT已经取得了重大进展,并取得了令人鼓舞的结果,在多个基准上接近甚至超过了SOTA CNN方法。然而,ViT的一些关键技术仍然不足以应对CV领域的复杂挑战。基于上述分析,论文指出了未来研究的一些有前景的研究方向。
集合预测:由于损失函数的相同梯度,多类token将一致收敛[40]。具有二分损失函数的集合预测策略已广泛应用于ViT,用于许多密集预测任务[30],[202]。因此,自然要考虑分类任务的集合预测设计,例如,多类token Transformer通过集合预测预测混合patch中的图像,这与LV-ViT中的数据增强策略类似[43]。此外,集合预测策略中的一对一标签分配导致早期过程中的训练不稳定,这可能会降低最终结果的准确性。使用其他标签分配和损失改进集合预测可能有助于新的检测框架。
自监督学习:Transformer的自监督预训练使NLP领域标准化,并在各种应用中取得巨大成功[2],[5]。由于自监督范式在CV领域的流行,卷积孪生网络使用对比学习来实现自监督预训练,这与NLP领域中使用的masked自动编码器不同。最近,一些研究试图设计自监督的ViT,以弥合视觉和语言之间的预训练方法的差异。它们中的大多数继承了NLP领域中的masked自动编码器或CV领域中的对比学习方案。ViT没有特定的监督方法,但它彻底改变了GPT-3等NLP任务。如前文所述,编码器-解码器结构可以通过联合学习解码器嵌入和位置编码来统一视觉任务。因此,值得进一步研究用于自监督学习的编码器-编码器Transformer。
结论
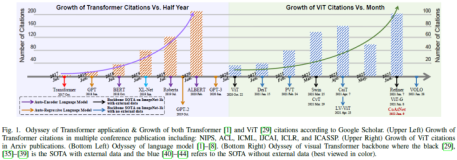
自从ViT证明了其在CV任务中的有效性之后,ViT受到了相当大的关注,并削弱了CNN在CV领域的主导地位。本文全面回顾了100多个ViT模型,这些模型相继应用于各种视觉任务(即分类、检测和分割)和数据流(如图像、点云、图像文本对和其他多个数据流)。对于每个视觉任务和数据流,提出了一种特定的分类法来组织最近开发的ViT,并在各种主流基准上进一步评估其性能。通过对所有这些现有方法的综合分析和系统比较,本文总结了显著的性能改进,还讨论了ViT的三个基本问题,并进一步提出了未来投资的几个潜在研究方向。我们希望这篇综述文章能帮助读者在决定进行深入探索之前更好地理解各种视觉Transformer。
参考
[1] A Survey of Visual Transformers
原文首发微信公众号【自动驾驶之心】:一个专注自动驾驶与AI的社区(https://mp.weixin.qq.com/s/NK-0tfm_5KxmOfFHpK5mBA)