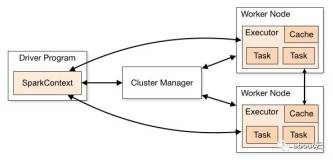
为何出现SparkSession
对于spark1.x的版本,我们最常用的是rdd,如果我们想使用DataFrame,则需要通过rdd转换。随着dataframe和dataset使用的越来越多,所以spark就寻找了新的切入点--SparkSession。如果rdd使用SparkContext,DateFrame和DataSet使用SparkSession,然后还有SQLContext和HiveContext,想必太麻烦了。所以官网用SparkSession封装了SQLContext和HiveContext。然而在2.2版本中,StreamingContext还是单独存在的。所以我们在使用SparkStreaming,还必须使用StreamingContext来作为入口。
SparkSession如何创建RDD
这里如果你思考的话,可能会想,spark2是否还支持rdd。当然还是支持的。
这里以下面为例:
我们进入spark-shell,通过SparkSession获取sparkContext
val sc=spark.sparkContext

sc.makeRDD(List(1,2,3,4,5))
val rddlist=sc.makeRDD(List(1,2,3,4,5))
val rl=rddlist.map(x=>x*x)
println(rl.collect.mkString(",")) 1,4,9,16,25

SparkSession如何实例化
通过静态类Builder来实例化。
Builder又有很多方法,包括:
1.appName函数
1.appName(String name)用来设置应用程序名字,会显示在Spark web UI中
值类型:SparkSession.Builder
2.config函数
这里有很多重载函数。其实从这里我们可以看出重载函数,是针对不同的情况,使用不同的函数,但是他们的功能都是用来设置配置项的。
1.config(SparkConf conf)
根据给定的SparkConf设置配置选项列表。
2.config(String key, boolean value)
设置配置项,针对值为boolean的
3.config(String key, double value)
设置配置项,针对值为double的
4.config(String key, long value)
设置配置项,针对值为long 的
5.config(String key, String value)设置配置项,针对值为String 的
值类型:SparkSession.Builder
3.enableHiveSupport函数
表示支持Hive,包括 链接持久化Hive metastore, 支持Hive serdes, 和Hive用户自定义函数
值类型:SparkSession.Builder
4.getOrCreate函数
getOrCreate()
获取已经得到的 SparkSession,或则如果不存在则创建一个新的基于builder选项的SparkSession
值类型:SparkSession
5.master函数
master(String master)
设置Spark master URL 连接,比如"local" 设置本地运行,"local[4]"本地运行4cores,或则"spark://master:7077"运行在spark standalone 集群。
值类型:SparkSession.Builder
6.withExtensions函数
withExtensions(scala.Function1<SparkSessionExtensions,scala.runtime.BoxedUnit> f)这允许用户添加Analyzer rules, Optimizer rules, Planning Strategies 或则customized parser.这一函数我们是不常见的。
值类型:SparkSession.Builder
了解了上面函数,对于官网提供的SparkSession的实例化,我们则更加容易理解
SparkSession.builder .master("local") .appName("Word Count") .config("spark.some.config.option", "some-value") .getOrCreate()