
Elasticsearch:
简单介绍一个Elasticsearch?
ElasticSearch是一个基于Lucene的搜索服务器。通过HTTP使用JSON进行数据索引,用于分布式全文检索,解决人们对于搜索的众多要求。
lucene与elasticsearch(solr)有什么区别?
lucene只是一个提供全文搜索功能类库的核心工具包,而真正使用它还需要一个完善的服务框架搭建起来的应用。好比lucene是类似于jdk,而搜索引擎软件就是tomcat 的。elasticsearch和solr,这两款都是基于lucene的搭建的,可以独立部署启动的搜索引擎服务软件。
基本概念:
cluster集群 |
整个elasticsearch 默认就是集群状态,整个集群是一份完整、互备的数据。 |
node节点 |
集群中的一个节点,一般只一个进程就是一个node |
shard分片 |
分片,即使是一个节点中的数据也会通过hash算法,分成多个片存放,默认是5片。 |
index逻辑数据库 |
相当于rdbms的database, 对于用户来说是一个逻辑数据库,虽然物理上会被分多个shard存放,也可能存放在多个node中。 |
type |
类似于rdbms的table,但是与其说像table,其实更像面向对象中的class , 同一Json的格式的数据集合。 |
document |
类似于rdbms的 row、面向对象里的object |
field |
相当于字段、属性 |
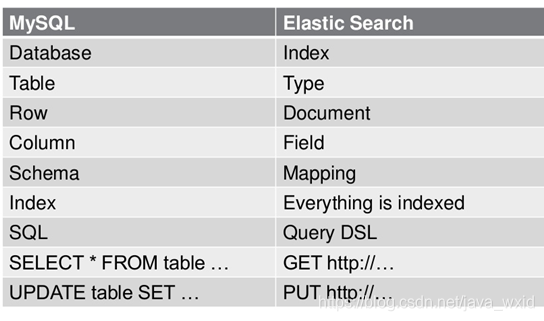
与MySQL对比
利用kibana学习 elasticsearch restful api (DSL)
Kibana 是一个开源分析和可视化平台,可视化操作 Elasticsearch 。Kibana可以用来搜索,查看和与存储在 Elasticsearch 索引中的数据进行交互。可以轻松地进行高级数据分析,并可在各种图表,表格和地图中显示数据。
ES提供了基于JSON的query DSL查询语言
es中保存的数据结构
public class Movie { String id; String name; Double doubanScore; List<Actor> actorList; } public class Actor{ String id; String name; }
这两个对象如果放在关系型数据库保存,会被拆成2张表,但是elasticsearch是用一个json来表示一个document。
所以它保存到es中应该是:
{ “id”:”1”, “name”:”operation red sea”, “doubanScore”:”8.5”, “actorList”:[ {“id”:”1”,”name”:”zhangyi”}, {“id”:”2”,”name”:”haiqing”}, {“id”:”3”,”name”:”zhanghanyu”} ] }
es 的java 客户端的选择
目前市面上有两类客户端
一类是TransportClient 为代表的ES原生客户端,不能执行原生dsl语句必须使用它的Java api方法。
另外一种是以Rest Api为主的missing client,最典型的就是jest。 这种客户端可以直接使用dsl语句拼成的字符串,直接传给服务端,然后返回json字符串再解析。
两种方式各有优劣,但是最近elasticsearch官网,宣布计划在7.0以后的版本中废除TransportClient。以RestClient为主。在官方的RestClient 基础上,进行了简单包装的Jest客户端,就成了首选,而且该客户端也与springboot完美集成。
中文分词
elasticsearch本身自带的中文分词,就是单纯把中文一个字一个字的分开,根本没有词汇的概念。
问题:
1、 es大量的写操作会影响es 性能,因为es需要更新索引,而且es不是内存数据库,会做相应的io操作。
2、而且修改某一个值,在高并发情况下会有冲突,造成更新丢失,需要加锁,而es的乐观锁会恶化性能问题。
解决思路:
用redis做精确计数器,redis是内存数据库读写性能都非常快,利用redis的原子性的自增可以解决并发写操作。
redis每计100次数(可以被100整除)我们就更新一次es ,这样写操作就被稀释了100倍,这个倍数可以根据业务情况灵活设定。
增量同步索引库
推荐使用MQ(RabbitMQ)
原理:使用MQ做增量同步,即当修改数据之后就将此数据发送至MQ,由MQ将此数据同步到ES上
Nginx:
1、请解释一下什么是Nginx?
nginx本是一个web服务器和反向代理服务器,但由于丰富的负载均衡策略,常常被用于客户端可真实的服务器之间,作为负载均衡的实现。用于HTTP、HTTPS、SMTP、POP3和IMAP协议。
2、请列举Nginx的一些特性?
1)反向代理/L7负载均衡器
2)嵌入式Perl解释器
3)动态二进制升级
4)可用于重新编写URL,具有非常好的PCRE支持
3、nginx和apache的区别?
1)轻量级,同样起web 服务,比apache 占用更少的内存及资源
2)抗并发,nginx 处理请求是异步非阻塞的,而apache 则是阻塞型的,在高并发下nginx 能保持低资源低消耗高性能
3)高度模块化的设计,编写模块相对简单
4)最核心的区别在于apache是同步多进程模型,一个连接对应一个进程;nginx是异步的,多个连接(万级别)可以对应一个进程
4.nginx是如何实现高并发的?
一个主进程,多个工作进程,每个工作进程可以处理多个请求,每进来一个request,会有一个worker进程去处理。但不是全程的处理,处理到可能发生阻塞的地方,比如向上游(后端)服务器转发request,并等待请求返回。那么,这个处理的worker继续处理其他请求,而一旦上游服务器返回了,就会触发这个事件,worker才会来接手,这个request才会接着往下走。由于web server的工作性质决定了每个request的大部份生命都是在网络传输中,实际上花费在server机器上的时间片不多。这是几个进程就解决高并发的秘密所在。即@skoo所说的webserver刚好属于网络io密集型应用,不算是计算密集型。
5、请解释Nginx如何处理HTTP请求?
Nginx使用反应器模式。主事件循环等待操作系统发出准备事件的信号,这样数据就可以从套接字读取,在该实例中读取到缓冲区并进行处理。单个线程可以提供数万个并发连接。
6、在Nginx中,如何使用未定义的服务器名称来阻止处理请求?
只需将请求删除的服务器就可以定义为:Server {listen 80; server_name “ “ ;return 444;}这里,服务器名被保留为一个空字符串,它将在没有“主机”头字段的情况下匹配请求,而一个特殊的Nginx的非标准代码444被返回,从而终止连接。7、 使用“反向代理服务器”的优点是什么?答:反向代理服务器可以隐藏源服务器的存在和特征。它充当互联网云和web服务器之间的中间层。这对于安全方面来说是很好的,特别是当您使用web托管服务时。
8、请列举Nginx服务器的最佳用途?
Nginx服务器的最佳用法是在网络上部署动态HTTP内容,使用SCGI、WSGI应用程序服务器、用于脚本的FastCGI处理程序。它还可以作为负载均衡器。
9、请解释Nginx服务器上的Master和Worker进程分别是什么?
Master进程:读取及评估配置和维持Worker进程:处理请求
10、请解释你如何通过不同于80的端口开启Nginx?
为了通过一个不同的端口开启Nginx,你必须进入/etc/Nginx/sites-enabled/,如果这是默认文件,那么你必须打开名为“default”的文件。编辑文件,并放置在你想要的端口:Like server {listen 81;}
11、请解释是否有可能将Nginx的错误替换为502错误、503?
502 =错误网关 503 =服务器超载 有可能,但是您可以确保fastcgi_intercept_errors被设置为ON,并使用错误页面指令。Location / { fastcgi_pass 127.0.01:9001; fastcgi_intercept_errors on; error_page 502 =503/error_page.html; #… }
12、在Nginx中,解释如何在URL中保留双斜线?答:要在URL中保留双斜线,就必须使用merge_slashes_off;语法:merge_slashes [on/off]默认值: merge_slashes on环境: http,server
13、请解释ngx_http_upstream_module的作用是什么?
ngx_http_upstream_module用于定义可通过fastcgi传递、proxy传递、uwsgi传递、memcached传递和scgi传递指令来引用的服务器组。
14、请解释什么是C10K问题?C10K问题是指无法同时处理大量客户端(10,000)的网络套接字。
15、请陈述stub_status和sub_filter指令的作用是什么?
1)Stub_status指令:该指令用于了解Nginx当前状态的当前状态,如当前的活动连接,接受和处理当前读/写/等待连接的总数 2)Sub_filter指令:它用于搜索和替换响应中的内容,并快速修复陈旧的数据
16、解释Nginx是否支持将请求压缩到上游?
您可以使用Nginx模块gunzip将请求压缩到上游。gunzip模块是一个过滤器,它可以对不支持“gzip”编码方法的客户机或服务器使用“内容编码:gzip”来解压缩响应。
17、解释如何在Nginx中获得当前的时间?要获得Nginx的当前时间,必须使用SSI模块、$date_gmt和$date_local的变量。Proxy_set_header THE-TIME $date_gmt;
18、用Nginx服务器解释-s的目的是什么?用于运行Nginx -s参数的可执行文件。
19、解释如何在Nginx服务器上添加模块?在编译过程中,必须选择Nginx模块,因为Nginx不支持模块的运行时间选择。
20、什么是反向代理和正向代理?
正向代理:被代理的是客户端,比如通过XX代理访问国外的某些网站,实际上客户端没有权限访问国外的网站,客户端请求XX代理服务器,XX代理服务器访问国外网站,将国外网站返回的内容传给真正的用户。用户对于服务器是隐藏的,服务器并不知道真实的用户。
反向代理:被代理的是服务器,也就是客户端访问了一个所谓的服务器,服务器会将请求转发给后台真实的服务器,真实的服务器做出响应,通过代理服务器将结果返给客户端。服务器对于用户来说是隐藏的,用户不知道真实的服务器是哪个。
关于正向代理和反向代理,听起来比较绕,仔细理解,体会也不难明白到底是什么意思。
用nginx做实现服务的高可用,nginx本身可能成为单点,遇见的两种解决方案,一种是公司搭建自己的DNS,将请求解析到不同的NGINX,另一只是配合keepalive实现服务的存活检测。
Fastdfs:
简单介绍一下FastDFS?
1.开源的分布式文件系统,主要对文件进行存储、同步、上传、下载,有自己的容灾备份、负载均衡、线性扩容机制;
2.FastDFS架构主要包含Tracker(跟踪) server和Storage(组,卷) server。客户端请求Tracker server进行文件上传、下载的时候,通过Tracker server调度最终由Storage server完成文件上传和下载。
3.Tracker server:跟踪器或者调度器,主要起负载均衡和调度作用。通过Tracker server在文件上传时可以根据一些策略找到Storage server提供文件上传服务。
Storage server:存储服务器,作用主要是文件存储,完成文件管理的所有功能。客户端上传的文件主要保存在Storage server上,Storage server没有实现自己的文件系统而是利用操作系统的文件系统去管理文件。
存储服务器采用了分组/分卷的组织方式。
整个系统由一个组或者多个组组成;
组与组之间的文件是相互独立的;
所有组的文件容量累加就是整个存储系统的文件容量;
一个组可以由多台存储服务器组成,一个组下的存储服务器中的文件都是相同的,组中的多台存储服务器起到了冗余备份和负载均衡的作用;
在组内增加服务器时,如果需要同步数据,则由系统本身完成,同步完成之后,系统自动将新增的服务器切换到线上提供使用;
当存储空间不足或者耗尽时,可以动态的添加组。只需要增加一台服务器,并为他们配置一个新的组,即扩大了存储系统的容量。
我们在项目中主要使用fastdfs来存储整个项目的图片。
为什么要使用FastDFS作为你们的图片服务器?
首先基于fastDFS的特点:存储空间可扩展、提供了统一的访问方式、访问效率高、容灾性好 等特点,再结合我们项目中图片的容量大、并发大等特点,因此我们选择了FastDFS作为我们的图片服务器;
Nginx也可以作为一台图片服务器来使用,因为nginx可以作为一台http服务器来使用,作为网页静态服务器,通过location标签配置;在公司中有的时候也用ftp作为图片服务器来使用。
FastDFS中文件上传下载的具体流程?
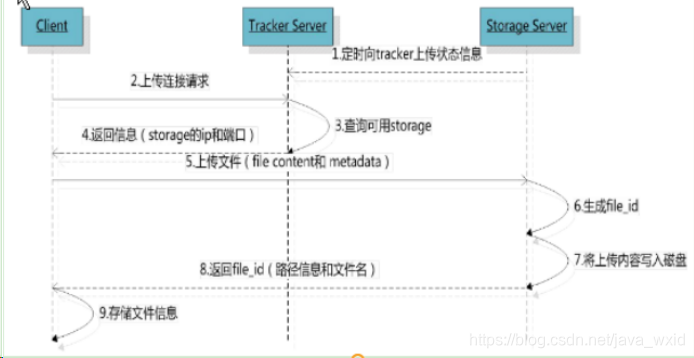
客户端上传文件后生成一个file_id,返回给客户端,客户端利用这个file_id结合ip地址,生成一个完成图片的url,保存在数据库中。生成的那个file_id用于以后访问该文件的索引信息。
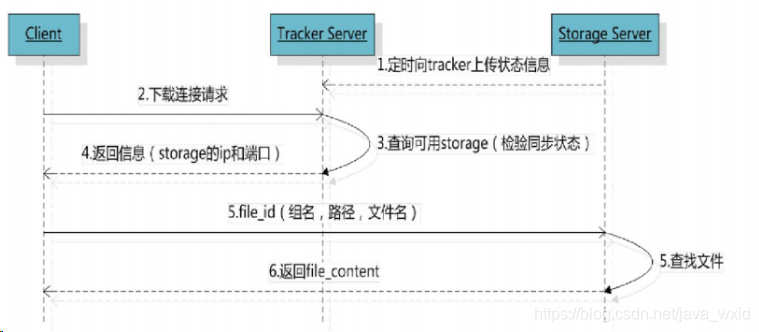
FastDFS文件下载的流程
ActiveMQ:
什么是activemq
activeMQ是一种开源的,面向消息的中间件,用来系统之间进行通信的
activemq的原理
原理就是生产者生产消息, 把消息发送给activemq。 Activemq 接收到消息, 然后查看有多少个消费者, 然后把消息转发给消费者, 此过程中生产者无需参与。 消费者接收到消息后做相应的处理和生产者没有任何关系
对比RabbitMQ
RabbitMQ的协议是AMQP,而ActiveMQ使用的是JMS协议。顾名思义JMS是针对Java体系的传输协议,队列两端必须有JVM,所以如果开发环境都是java的话推荐使用ActiveMQ,可以用Java的一些对象进行传递比如Map、Blob(二进制大数据)、Stream等。而AMQP通用行较强,非java环境经常使用,传输内容就是标准字符串。
另外一点就是RabbitMQ用Erlang开发,安装前要装Erlang环境,比较麻烦。ActiveMQ解压即可用不用任何安装。
对比KafKa
Kafka性能超过ActiveMQ等传统MQ工具,集群扩展性好。
弊端是:
在传输过程中可能会出现消息重复的情况,
不保证发送顺序
一些传统MQ的功能没有,比如消息的事务功能。
所以通常用Kafka处理大数据日志。
对比Redis
其实Redis本身利用List可以实现消息队列的功能,但是功能很少,而且队列体积较大时性能会急剧下降。对于数据量不大、业务简单的场景可以使用。
如何解决消息重复问题
所谓消息重复,就是消费者接收到了重复的消息,一般来说我们对于这个问题的处理要把握下面几点,
①.消息不丢失(上面已经处理了)
②.消息不重复执行
一般来说我们可以在业务段加一张表,用来存放消息是否执行成功,每次业务事物commit之后,告知服务端,已经处理过该消息,
这样即使你消息重发了,也不会导致重复处理
大致流程如下:
业务端的表记录已经处理消息的id,每次一个消息进来之前先判断该消息是否执行过,如果执行过就放弃,如果没有执行就开始执行消息,消息执行完成之后存入这个消息的id
关于事务控制
获取session链接的时候 设置参数 默认不开启
producer提交时的事务 |
事务开启 |
只执行send并不会提交到队列中,只有当执行session.commit()时,消息才被真正的提交到队列中。 |
事务不开启 |
只要执行send,就进入到队列中。 |
consumer 接收时的事务 |
事务开启,签收必须写 Session.SESSION_TRANSACTED
|
收到消息后,消息并没有真正的被消费。消息只是被锁住。一旦出现该线程死掉、抛异常,或者程序执行了session.rollback()那么消息会释放,重新回到队列中被别的消费端再次消费。 |
事务不开启,签收方式选择 Session.AUTO_ACKNOWLEDGE |
只要调用comsumer.receive方法 ,自动确认。 |
|
事务不开启,签收方式选择 Session.CLIENT_ACKNOWLEDGE |
需要客户端执行 message.acknowledge(),否则视为未提交状态,线程结束后,其他线程还可以接收到。 这种方式跟事务模式很像,区别是不能手动回滚,而且可以单独确认某个消息。 手动签收 |
|
事务不开启,签收方式选择 Session.DUPS_OK_ACKNOWLEDGE |
在Topic模式下做批量签收时用的,可以提高性能。但是某些情况消息可能会被重复提交,使用这种模式的consumer要可以处理重复提交的问题。 |
持久化与非持久化
通过producer.setDeliveryMode(DeliveryMode.PERSISTENT) 进行设置
持久化的好处就是当activemq宕机的话,消息队列中的消息不会丢失。非持久化会丢失。但是会消耗一定的性能。






