本文是 serverless 入门与实践 的第33篇
学习<华为 Serverless 核心技术与实践>, 计划: 1篇前言 + 10篇/章 + 1篇总结
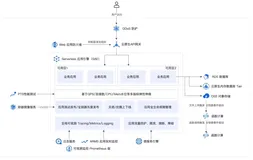
翻译服务的Serverless架构设计
经过前面几章的学习,我们以华为元戎为例帮助读者理解Serverless的架构原理、关键技术和相关后端服务,接下来本章进入实战篇,通过华为终端云服务平台AppGallery Connect基于Serverless技术构建的翻译服务案例,掌握如何在商业项目中进行架构选型并综合运用云函数、云数据库、云存储和云托管来提高研发效率和降低成本。本章的内容包括对AppGallery Connect的Serverless平台服务和翻译服务进行功能简介,根据翻译服务的特点开展技术架构选型,具体设计介绍翻译服务的Serverless架构。
Serverless平台与翻译服务
AppGallery Connect的应用构建类服务为应用开发者提供了全栈的Serverless平台解决方案,其主要包括:
- 认证服务
- 云函数
- 云数据库
- 云存储
- 云托管服务
Serverless全栈服务提供了跨端支持,以云函数为例,客户端SDK支持Android、iOS、Web和快应用等
云函数
云函数特点:
- 多语言:支持Java、Node.js等多种运行时,支持用户自定义运行时,因此对于用户使用何种语言编写函数无限制,用户可以使用自己熟悉的语言编写、部署函数。
- 自动化管理:为用户管理函数部署、运行所需的所有资源,保证用户代码在高可用基础设施上运行。
- 弹性伸缩:按需调用用户代码,并能自动扩展以适配流量的变化,保证高性能,无须用户进行人工操作。
- 异构基础设施:为函数提供完备的软硬件运行环境,可部署在包括虚拟机、Docker容器等在内的多种底层基础设施之上。
- 函数编排:提供函数编排能力,允许北向服务将多个独立的原子函数编排为复合型函数,对外提供接口。
云数据库
云数据库主要功能:
- 灵活的同步模式,支持缓存和本地两种数据同步模式。在缓存模式下,端侧数据是云侧数据的子集,如果允许持久化,查询的结果将会自动缓存至端侧;在本地模式下,数据只存储在本地,不和云侧数据进行同步。
- 多种模式查询能力,支持丰富的谓词查询,可以包含多个链式过滤条件,可以将过滤和排序或限定返回结果集的对象数量功能结合使用。在缓存模式下,可以指定从云侧存储区或本地存储区查询数据;在本地模式下,直接从本地存储区查询数据。
- 实时更新,在缓存模式下,可以通过对需要关注的数据进行侦听,并利用云数据库的数据同步功能,将发生变化的数据在端云、多设备间进行实时更新。
- 离线支持,在缓存模式下,如果允许缓存持久化,当设备离线时,应用对云端数据库的查询会默认转为从本地查询。当设备恢复在线状态时,云数据库会将所有本地写入的数据自动同步至云端数据库。
- 安全性高,支持端云全程加密数据管理,App、用户和服务三重认证,基于角色的权限管理等,全方位保障数据安全。
- 伸缩性高,底层采用了分布式数据库,采用计算和存储分离设计,支持从万级到万亿级的数据迁移和自动弹性扩容,迁移不中断业务,业务不需要进行分库分表。
云存储
云存储工作原理

相比于传统的对象存储服务,云存储服务的优势:
- 声明式安全语言,简化用户授权和验证请求的工作,降低开发复杂性。
- 协同开发,通过配置触发器,在文件发生变化时触发对应的函数执行,实现与函数的协同。
- 弹性伸缩,通过对租户项目的存储空间进行实时监控,利用跨机房调度策略和弹性伸缩平台,实现单租户EB级的数据存储。
云托管服务
云托管服务功能:
- 自定义域名,数据存储地在中国,开发者只需提供申请的域名,无须关注CDN加速和SSL配置,通过控制台一键发布版本即可向全球用户分发托管的内容。
- 系统分配域名,数据存储地在德国、俄罗斯、新加坡站点,服务于海外开发者用户时,开发者可以使用华为分配的域名,例如,fly.dra.agchosting.link、fly.drru.agchosting.link或fly.dre.agchosting.link,其中四级域名(fly)可以由开发者自己定义。
- 版本管理,云托管能够将静态内容自动执行上下线的部署,同时可以对历史版本进行管理,例如,执行回退版本、删除版本等操作。