@[TOC]
前言:
- 博主实力有限,博文有什么错误,请你斧正,非常感谢!
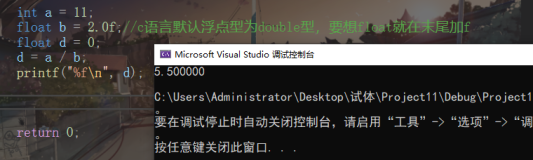
- 博主目前只掌握的c语言,因此本文主要以c语言为背景讨论问题。编译器:VS2019
- 本文是《C陷阱与缺陷》专栏第3章
- 《C陷阱与缺陷》第一章,我们认识了词法“陷阱”,第二章认识了语法“陷阱”
- 第三章让我们了解一下语义”陷阱“(指针与数组底层原理,求值顺序)
《C陷阱与缺陷》
、
语义”陷阱“
- 一句话,哪怕,单词,语法都对,仍然可能存在歧义或者非我们表达希望的意思。
- 同样对于c程序,即使语法正确,编译器对其也可能是我们非希望的运算,因此本博文主要讨论:语义“陷阱“。
指针与数组
指针与数组之间的联系是密不可分,理解数组必然需要理解指针。
- 数组名是不能进行自增,自减运算的,因为数组名是常地址。

- C语言只有
一维数组,而且数组的大小必须在编译期间就作为常数确定下来。
- 为什么说C语言只有一维数组呢?
- 我们知道变量在内存是连续存放的,同样一维数组也是。Exp;arr[m];当我们定义一个一维数组时,内存会为arr开辟大小为:
m*sizeof(arr[0])的字节空间。而对于二维数组,因为内存连续性的原因,内存并不会真真的开辟一个二维空间,而是连续依次存入二维数组的每个数据。之所以有二维数组的说法是为了分析问题方便。Exp: int arr[ 3 ] [3 ] ;
声明 arr是一个数组,该数组有3个元素,每个元素类型是数组大小为3的一维数组。
- 二维数组的实质是一维数组,只是其元素类型是一维数组类型。
- 多维数组同理
- 为什么要在编译期间确定大小
为了给数组开辟内存
- 对于数组我们只要知道2件事:1.数组
大小;2.获得指向数组首元素地址的指针。对于数组的运算就没问题了
- 为什么说知道数组首元素地址就可以了
1.指针的运算是根据其指向
数据类型来进行计算。int main() { int arr1[4] = { 5,6,8,4}; int* p1 = arr1;//数组名是一维数组arr1首元素地址,而首元素是int 类型,因此p类型为int printf("%d\n", *arr1); printf("%d\n", *p1); printf("%d\n", *(arr1+1)); printf("%d\n", *(p1+1));//p的类型是int,因此加一,跳过int 字节内存。 //二维数组 printf("\n"); int arr2[3][2] = {45,4,5,6,78,75 }; int(*p2)[2] = arr2;//数组名是二维数组首元素地址,而首元素的,类型是 int [2](含有2个元素的一维数组) //因此p在定义的类型为:int [2]; printf("%d\n", arr2[0][0]); printf("%d\n", **p2);//*p后的地址类型为int,而%d需要int型数据,因此再*; printf("%d\n", arr2[1][0]); printf("%d\n", *(*(p2 + 1)+0)); return 0; }
2.以数组下标的形式进行数组的运算很正常,但是实质底层原理是指针的运算(编译器在遇到数组都将其转化为
同类型的指针)。任何一个数组元素的下标都可以通过指针找到。因此我们完全可以依据指针进行数组的运算。
- 许多程序设计语言中都内建有索引运算,在C语言中索引运算是以指针算术的形式定义的。
int *p=arr; //数组下标为0的元素是arr[0] //实质是*(p+0); //数组下标为1的元素是arr[1] //实质是 *(p+1) int arr[2][3]={0}; int (*p)[3]=arr; //数组下标为0的元素是arr[0],但是其类型int*即int的地址,因此二维数组下标 (0,0)的arr[0][0] //其实质:*(*(p+0)+0) //数组下标为1的元素是arr[1],但是其类型int*即int的地址,因此二维数组下标 (1,0)的arr[1][0] //其实质:*(*(p+1)+0)


操作符:sizeof()
- sizeof()是
操作符,不是函数
- sizeof()用于只用于求
数据在内存中所占内存的大小单位字节,在()里面不产生的任何影响
- sizeof对
数组的一些运算,有特殊规定C中数组名代表其数组首元素地址。但是对于sizeof()来说,其代表整个数组。而&arr代表取数组的地址,因此对地址求其大小,在32位系统4字节大小64位系统下8字节大小。


指针
- 任何指针都是指向某种类型的变量,类型决定了指针运算跳过的字节大小。
- 只有
同类型的指针之间,才能进行有效运算int 型指针与int型指针间进行运算,数组型指针与数组型指针间进行运算。等。。。
- 同类型指针间的运算是有意义的
- 比如同时指向数组的2个指针,其相减就可以得到2个指针间的元素个数

- 一旦定义指针,就
必须指定其指向,或者对指针赋值NULL- 对于一维数组arr[i]与* (p+i)意义一样,但是[ ]的形式更容易理解,尤其是二维数组。
- 因为(p+i)== (i+p),即p[i]=i[p],但是
强烈不推荐这种i[p]这种形式
非数组的指针
- 字符串
C语言的字符串常量存放在常量区,其代表一块包括字符串中所有字符以及字符串`结束标志‘\0'组成 的内存区域的首地址.因此对于字符型指针,其不是指向整个字符串,而指向的是字符串的
首地址。另外不同的指针,指向相同字符串,不同指针指向同一地址的字符串
- 字符串的实质是地址,但是因为其是常量,因此不能修改其值
char *str="hello"; *str='G';//在C语言在是违法,禁止的
- 打印字符串%s的规则
其打印的
地址必须是字符串类型
- 打印结束标志是
‘\0’;

作为参数的数组声明
Exp:
int fun(int arr[]) //编译器自动转换数组名 int fun(int *p)
避免”举隅法“
- ”举隅法“是一种文学修辞上的手段,类似以微笑代替喜悦,赞许之情。而对于C语言中,指针是指向某个数据,但是并不意味这指针就是该数据,指针存的是该数据的地址。即不要混淆
指针与指针所指向的数据
空指针并非空字符串
C语言的
强制转换操作符,可以将一个整数X强制转换为指针(即x将变成对应16进制内存编号的地址),但是对于常数0这个特殊情况,编译器保证由0转换的指针不等于任何有效的指针。当0转换为指针时,绝对不可以对其
解引用(*)if(p==(char*)0) {}//合法 if(strcmp(p,(char *)0)) {}//非法,库函数strcmp中有对指针的``解引用``
边界计算与不对称边界
边界计算:
对一个数组有10个元素,那么数组下标的范围是什么呢?
- 对于Fortran,Pl/I,Snobol4等程序语言,下标从1开始,而且这些语言允许自定义数组下标的起始地址。
- 对于Algol,Pascal,编程必须
显示的指定数组下标上界与下界- 在Basic中声明一个10个元素的数组,实际编译器分配11个元素的空间,下标从0到10
不对称边界:
问题:修建一个100米的护栏,护栏间的距离是10米,问需要多少栏杆?答案: 11
这是典型的”栏杆错误“,也被称谓”差一错误“
针对这种错误有一种好的方法:
- 首先考虑最简单情况下的特例,然后推广
- 仔细计算边界。
而在C语言编程时如何更好的避免差一错误呢?
这就需要“不对称边界”:
- 用第一个入界点和最后一个出界点来表示数值范围
- 取值范围大小是出界点与入界点差
- 上界永远不小于下界
Exp1:
Exp2:


数组边界”溢界“问题
int i =0; int arr[10]={0}; for(i =0;i<=12;i++) { arr[i]=0; printf("%d\n",arr[i]) } //这种用法在C中是允许的,因为底层是指针。 //程序是个死循环,下面解释 //在Vs2019中,编译器会在变量与数组之间放2个空内内存,目的就是防止"溢界"问题 //内存的利用是先高地址,后低地址。 //正是因为这个规则和变量与数组的定义顺序,当arr[12]即是i //此时i又重新赋值为0,因此进入死循环
求值顺序
- 运算符的优先级并不决定求值顺序。
int a=b c+d e+f * g;//编译器只知道*比+先计算,但是不知道开始的顺序是怎样的。
即a=(bc+d e)+f * g;
或者a=bc+(d e+f * g);
- 但是C语言在规定了4个运算符的求值顺序
四个运算符是:&&;|| ; ?: ; ‘,’ ;
- &&和||首先对左侧操作数求值,具有改变运算顺序的性质即(左侧为真,右侧就不需要求值)
- a?b:c 先算a,后根据a算b,c;
- ,首先对左侧操作数求值,然后丢弃该值,再对下一个操作数求值。
- 分隔函数参数的‘’逗号‘’不是“逗号运算符”。
- 所有赋值运算都不决定求值顺序
int i=0; while(i<n) { y[i]=x[i++] } //因为赋值"="的性质,无法确定y,x中的i是哪个值,另外不同编译器会有自己的赋值运算符求值顺序。为避免这个有争议的”垃圾代码“我们可以 while(i<n) { y[i]=x[i]; i++; }
整数“溢出”
C中的每种数据类型都有其取值范围。如signed char -128~127
int (-2^31) ~(2^31-1)
等...
- C语言中存在2种整数算术运算,有符号和无符号
- 在无符号运算中,无”溢出“一说
- 在无符号与有符号运算中,有符号会转化为无符号型,进行运算,不在有“”溢出“一说
在有符号运算中,存在”溢出“一说。另外“溢出”的结果是
未定义的,当发生“溢出”,任何的运算都是不安全的。假设a和b是2个非负整形变量,我们检验是否会“溢出”,溢出后就会成为”负数“。
if(a+b<0) { .. }更改为:
//方法一 if((unsingned)a+(unsigned)b>INT_MAX) {} //INT_MAX是整形数据的最大取值,定义在<limits.h>库中 //方法二 if(a>INT_MAX-b) {}
为main函数提供返回值
- 函数为说明返回值的类型时,默认为int,main也同理
- 对于大多数C语言都是通过main的返回值来告诉操作系统该函数执行是成功还是失败。
- 返回0代表成功,非0代表失败
- 因此return具有结束函数执行的效果,在循环中合理运用会产生奇妙的效果