开发者学堂课程【模型社区实战课程:ModelScope pretrained model】学习笔记,与课程紧密联系,让用户快速学习知识.
课程地址:https://developer.aliyun.com/learning/course/1199/detail/18152
ModelScope pretrained model
内容介绍:
一、多模态预训练大模型背景&价值
二、通用统一多模态预训练 M6-OFA
三、中文多模态基础模型 Chinese CLIP
四、大规模中文多模态数据集和评测基准
五、总结&近期发布
一、多模态预训练大模型背景&价值
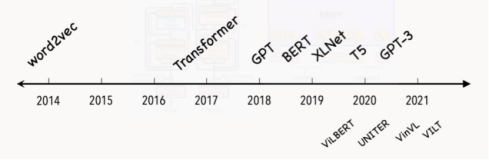
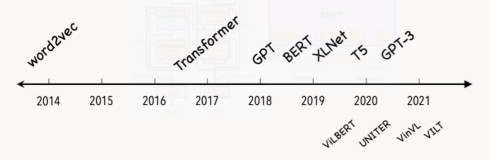
随着2017年的时候,Transformer 这样基于 self attention 的这种特殊的架构提出,使大家可以看到,随着模型规模的持续扩大,可以看到模型效果的持续增长,并且它能够很好的进行数据并行和模型并行,把模型规模以及数据量给它扩上去。

也可以看到预训练逐渐成为 AI 发展的主流,如果朝着需要的人工智能的方向,预训练这种大量的学习无监督数据的这种方式,会是一个非常可行的方案。
当进行微调的时候,只需要在顶上加上一个相应的分类层,就能够把此前学习过的知识,给它调动起来,然后取得一个比较好的下游的微调分类的效果。那么这种非常简单的范式,其实也是替代掉传统的 train well 的范式,从此开始走向了 between 再加下游 function 的这样一种模式。

所以其实类本化也扮演着非常基础模型的角色,这也是今年在做相关的研究,会推出 offer Chinese CLIP 这两个系列的工作的原因,两者是各有其优势。

所以在这相关方面,其实也做了比较多相应的工作。
二、通用统一多模态预训练 M6-OFA
接下来给大家介绍一下这一年多的相关进展,主要首先介绍今年在2022提出的 OFA 的工作,然后这是 M6系列的最新的工作。
1.多模态预训练待解决问题
(1)预训练往往缺少对海量单模态数据的利用
所以这里称为他们的 offer,其实本质上是一个通用统一的多模态域训练模型。那么通用统一其解决的是什么样的问题呢?
2.通用统一模型应当满足的性质
所以在工作当中,其实提出了三个比较重要的性质。如果今天要打造一个通用统一的模型应当满足这三个性质。
3.OFA(One-For-ALL)模型
这其实在LP里面已经有比较多的一些突破了,近期可以看到像 fun、T0以及最新的 national extra me two 把1600个 LP 的任务,都放到一个模型去进行训练,也取得了非常好的效果。
4.OFA 三大统一
这里的工作其实主要就是做了三个方面的统一,这三个方面的统一称为 IO 统一,模态统一以及任务统一,这都是为了解决刚才所说的那个相应的目标。

所以其实核心点还是在于将不同的任务的话都统一到一个形式,这样就能够让多任务去进行训练,当然 OFA 现在其实目前只用了八个任务去做训练。后续的工作其实是想在 OFA 的基础上,再更进一步将其融入更多样的任务中去进行训练,甚至不只是包含图文两种模态,这样模型化才能够去学到更多一些知识,然后实现融会贯通。

5.预训练数据
这里也想看看真正的去学习广泛识别知识的模型能够起到什么样的效果。这里是主要介绍 OFA 模型设计。具体做实践的同学可能会比较关心的细节是 OFA 这个模型化用了哪些预训练的数据,其实做这个工作的初衷是偏学术的工作。
6. 模型规模
那么同时其实除了在数据方面,就是在模型方面,其实做了一些比较细致的多个规模的模型研究,这里相比于此前一些工作,可能只有 base 和 large 规模其实还做了更小的模型,这里包括 tiny 和 medium 的模型,具体的参数其实也都列在这上面。
那么 base 和 large 模型在这里的对标对象其实是像 bird 和 but 这种。
7.效果:多模态理解
这里其实包括以下一系列的任务,首先就是动态理解的任务,这里主要做的两个数据集,一个是经典的 VQA,第二个是 SNLI 和动态结合的数据集,SNLI -VE,那么在 VQA 的数据集上面在推出的时候,其实是达到了 SOTA 的效果,那么不发 huge 在 test step 和 test standard 都达到82.0

8.效果:图像描述生产
第二个是图像描述生成,在图像描述生成的榜单 MSCOCO 的官方榜单上大概是维持了两个多月的第一名的水平。
9.效果:图像生成产出高质量图片
另外一方面还做了比较有挑战性的任务,任务其实不是 OFA 主要做的任务,而是去 transport 场景去看看其是否同样能够给它做好,因为核心理念是在于模型有一个预训练任务叫做 image in feeling,也就是说抠掉一些 patch,让它去还原这些 patch,还原方式就是生成它对应的 liquid 的 code。

这里也希望追求更好的效果,所以在这个基础上进一步的去在更大的数据上去进行,发现其实在一些绘画方面会展现出比较好的效果。可以看到 OFA 生成出来这些图片整体的质量还是比较高的。

10.多模态模型同样能在单模态任务取得突出效果
另一方面还会去评估 OFA 的能力,其实就是它单模态任务的能力,因为相比于此前的一些模型主要是在图文 pair 的数据上去做预训练。那预训练其实在图文 pair 基础上还加入了大量的单模态的数据
11.零成本任务&领域迁移
这是 OFA 在单模态领域取得的一些表现,还有一个点是会去考虑 OFA 这样的多任务的模型在零样本的场景中的表现如何,以及说迁移到一些新的领域上是否也能够取得比较好的表现。在这里零样本方面,除了 benchmark 的分数以外。
12.零成本任务&领域迁移
这里看到其一定的迁移到新任务的能力。另一方面也去观察模型迁移到新领域方面的一些能力。
后面其实还会再持续的去扩增这个数据规模以及任务规模,让它能够产生出更强的迁移和泛化的这种能力。
13.OFA 持续升级:轻量化调优
除此之外在 OFA 的基础上,其实也是不断的在做持续的升级。那么升级包括几个方面,第一个方面就是轻量化调优的方面,因为 OFA 的模型化,比如像 large 模型,甚至是 huge 模型,其实它的规模化对于很多用户来说是不小的,这么大的规模如果想让其动起来,其实在一些多模态这些数据集上面成本其实是不小的,所以其实是开发了相应的 fortune 的这种方法,核心其实就是把大模型的参数化冻住,让其不要进行调优。

14.OFA 持续升级:OFA增加中文版
同时 OFA 的升级包括 OFA 不仅仅在英文的公开数据集上去做,因为OFA 有很多用户都是国内的用户,所以其实也增加中文版。因为去年其实做 M6这个系列,在中文的大规模训练方面,有了非常多的积累,包括数据的积累,以及模型训练的积累。所以把这些经验迁移到 OFA 上面,也是一个比较自然的事情,用比较大规模的数据去对 OFA 进行训练,得到 BASE和 large 的规模和模型。那么在 benchmark 上面,一个是此前推出的牧歌的系列 action 上取得分数上的很好的效果。
15.OFA Github 开源以及 Demo 建设
这里的把相关的一些链接,包括 paper、code、ModelScope、Demo、Colab、checkpoint等等可以直接下载这个链接都在这里做相应的提供。
Paper: http:/axri.org/abs/2202.03052Code: https://github.com/0OFA-Sys/OFAModelScope: https://www.modelscope.cn/modelsDemo: https://huggingface.co/ofa-sysColab: https://github.com/OFA-Sys/OFA/blob/main/colab.mdCheckpoints: https://github.com/QFA-Sys/OFA/blob/main/checkpoints.mdPaper: http:/axri.org/abs/2202.03052Code: https://github.com/0OFA-Sys/OFAModelScope: https://www.modelscope.cn/modelsDemo: https://huggingface.co/ofa-sysColab: https://github.com/OFA-Sys/OFA/blob/main/colab.mdCheckpoints: https://github.com/QFA-Sys/OFA/blob/main/checkpoints.md