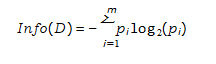基于压缩近邻法练的分类问题
压缩近邻法的做法是:
- 对初始训练集R,将其划分为两个部分A和B,初始A样本集合为空。
- 从R中随机选择一个样本放入A中,其它样本放入B中,用其对B中的每一个样本进行分类。若样本i能够被正确分类,则将其放回到B中;否则将其加入到A中;
- 重复上述过程,直到B中所有样本都能正确分类为止。
# -*- coding: utf-8 -*- """ Created on Thu Mar 19 22:27:40 2020 @author: lihuanyu """ #%%数据预处理 import numpy as np from gain_xy import gain_xy from sklearn.metrics import accuracy_score import csv X_train,y_train,X_test1,y_test1,X_test2,y_test2 = gain_xy() #%% import numpy as np from math import sqrt from collections import Counter class KNNClassifier: #定义K近邻的值必须大于1 def __init__(self,k): self.k = k self.x_train_fit = None self.y_train_fit = None def fit(self,x_train,y_train): self.x_train_fit = x_train self.y_train_fit = y_train return self #算出每个点与其他训练集的距离 def _predict(self,x): distance = [] for x_train in self.x_train_fit: distance.append(sqrt(np.sum((x_train - x) ** 2))) nearst = np.argsort(distance) topk_y = [] for j in nearst[:self.k]: topk_y.append(self.y_train_fit[j]) votes = Counter(topk_y) result = votes.most_common(1)[0][0] return result #批量预测 def predict(self,X_test,y_test): y_predict = [self._predict(i) for i in X_test] print("准确率为",accuracy_score(np.array(y_predict),y_test)) #%%KNN预测 knn = KNNClassifier(k=5) knn.fit(X_train,y_train) knn.predict(X_test1,y_test1) knn.predict(X_test2,y_test2) #%%压缩处理 k=1 Store = [X_train[0]] #新样本集 Store_y = [y_train[0]] Grabbag = [i for i in X_train[1:]] Grabbag_y = [i for i in y_train[1:]] for x_t,y_t in zip(Grabbag,Grabbag_y): distance = [] for x,y in zip(Store,Store_y): #print(x,y) distance.append(sqrt(np.sum((x - x_t) ** 2))) nearst = np.argsort(distance) topk_y = [Store_y[t] for t in nearst[:k]] votes = Counter(topk_y) result = votes.most_common(1)[0][0] if result == y: Store.append(x_t) Store_y.append(y_t) print(len(Store),len(Store_y)) #%%结果 X_train1 = np.array([i for i in Store]) y_train1 = np.array([i for i in Store_y]) import matplotlib.pyplot as plt plt.scatter(X_train1[y_train1==0,0],X_train1[y_train1==0,1],color='red') plt.scatter(X_train1[y_train1==1,0],X_train1[y_train1==1,1],color='blue') knn = KNNClassifier(k=5) knn.fit(X_train1,y_train1) knn.predict(X_test1,y_test1) knn.predict(X_test2,y_test2)
结果
test1K近邻准确率为 0.9032258064516129 test2K近邻准确率为 0.8444444444444444 test1压缩近邻准确率为 0.8548387096774194 test压缩近邻准确率为 0.8
压缩之后样本点分布如下图所示: