前言
Pandas常用作数据分析工具库以及利用其自带的DataFrame数据类型做一些灵活的数据转换、计算、运算等复杂操作,但都是建立在我们获取数据源的数据之后。因此作为读取数据源信息的接口函数必然拥有其强大且方便的能力,在读取不同类源或是不同类数据时都有其对应的read函数可进行先一步处理,这会减少我们相当大的一部分数据处理操作。每一个read()函数,作为一名数据分析师我个人认为都应该掌握且熟悉它对应的参数,相对应的read()函数博主已有两篇文章详细解读了read_json和read_excel:
一、基础语法与功能
pandas.read_sql( sql, con, index_col=None, coerce_float=True, params=None, parse_dates=None, columns=None, chunksize=None)
共有8个可选参数:sql,con,index_col,coerce_float,params,parse_date,columns,chunksize。
该函数基础功能为将SQL查询或数据库表读入DataFrame。此函数是read_sql_table和read_sql_query(向后兼容性)两个函数功能结合。它将根据提供的输入参数传入给特定功能。一个SQL查询将传入到read_sql_query查询,而数据库表名称将路由到read_sql_table表。特定功能为SQL引擎驱动进行查询获取数据库内的数据。
二、参数说明和代码演示
sql : string or SQLAlchemy Selectable (select or text object) SQL query to be executed or a table name. con : SQLAlchemy connectable (engine/connection) or database string URI or DBAPI2 connection (fallback mode) Using SQLAlchemy makes it possible to use any DB supported by that library. If a DBAPI2 object, only sqlite3 is supported. index_col : string or list of strings, optional, default: None Column(s) to set as index(MultiIndex). coerce_float : boolean, default True Attempts to convert values of non-string, non-numeric objects (like decimal.Decimal) to floating point, useful for SQL result sets. params : list, tuple or dict, optional, default: None List of parameters to pass to execute method. The syntax used to pass parameters is database driver dependent. Check your database driver documentation for which of the five syntax styles, described in PEP 249’s paramstyle, is supported. Eg. for psycopg2, uses %(name)s so use params={‘name’ : ‘value’} parse_dates : list or dict, default: None List of column names to parse as dates. Dict of {column_name: format string} where format string is strftime compatible in case of parsing string times, or is one of (D, s, ns, ms, us) in case of parsing integer timestamps. Dict of {column_name: arg dict}, where the arg dict corresponds to the keyword arguments of pandas.to_datetime() Especially useful with databases without native Datetime support, such as SQLite. columns : list, default: None List of column names to select from SQL table (only used when reading a table). chunksize : int, default None If specified, return an iterator where chunksize is the number of rows to include in each chunk.
上述为官网文档参数说明:Pandas.read_sql()
首先我们将逐个了解每个参数的功能和作用,在了解参数意义后再进行实例使用。
要进行参数测试要先连接数据库,这里用本地环境进行测试:
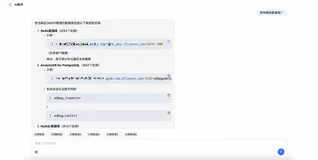
首先打开mysql,要以管理员方式进入命令提示符:

进入Jupyter,需要再引入pymysql库:
import pymysql
该库想要详细了解可以去博主的另一篇博文: ython-pymysql库使用一文详解+实例代码
此库为连接mysql的接口函数:
# 打开数据库连接 conn = pymysql.connect(host='localhost',# 连接的数据库服务器主机名 port=3306,# 数据库端口号 user='root',# 数据库登录用户名 passwd='xxxx',#数据库密码 db='mysql', # 数据库名称 charset = 'utf8' 连接编码 )
还需引入SQLalchemy库的创建引擎函数:
from sqlalchemy import create_engine
创建引擎:
engine=create_engine('mysql+pymysql://root:xxxx@localhost/mysql?charset=utf8')
1.sql
接受类型:{str or SQLAlchemy Selectable (select or text object)}
这个SQLAlchemy Selectable就是SQL查询语法,该参数可以为执行的SQL查询或获取指定表名的数据。
展示:需求要读取metric_value这张sql数据表:

将一段sql查询语句作为参数传入,可获得sql查询的表转化的dataframe:
sql_cmd ='SELECT * FROM metric_value' df_sql=pd.read_sql(sql_cmd,engine) df_sql
可以见到是和原sql表一样的内容:

也可以将sql内的表名作为参数传入,可以获得该表的全部内容:
sql_table ='metric_value' df_sql=pd.read_sql(sql_table,engine) df_sql

2.con
接受类型:{SQLAlchemy connectable, str, or sqlite3 connection}
使用SQLAlchemy可以使用该库支持的任何DB。如果是DBAPI2对象,则仅支持sqlite3。用户负责SQLAlchemy connectable的引擎处理和连接关闭;str连接将自动关闭。
con为python连接sql的sqlalchemy.engine,该参数也为必须输入的参数,可以使用SQLAlchemy数据库支持的连接引擎。上文已经创建这里不再进行操作
3.index_col
接受类型:{str or list of str, optional, default: None}
可指定参数为要设置为索引的列(多索引)。
sql_table ='metric_value' df_sql=pd.read_sql(sql_table,engine,index_col='id') df_sql

也可以设定多个索引,当然转化为dataframe之后用set_index也可以达到一样的效果,大家要是忘了如何操作dataframe的索引的话可以去博主的:一文速学-Pandas索引设置操作各类方法详解+代码展示 在看一遍就好了。
sql_table ='metric_value' df_sql=pd.read_sql(sql_table,engine,index_col=['id','time']) df_sql

4.coerce_float
接受类型:{bool, default True}
尽力函数:将非字符串、非数字对象(如decimal.Decimal)的值转换为浮点,这对SQL结果集很有用。相当于将一些数据类型转换为浮点数据类型,True开着就行了。
5.params
接受类型:{list, tuple or dict, optional, default: None}列表,元组,指定,默认为None。
可传入参数为要传递给execute方法的参数列表。用于传递参数的语法依赖于数据库驱动程序。查看数据库驱动程序文档,了解支持PEP 249的paramstyle中描述的五种语法样式中的哪一种。例如,对于psycopg2,指定需要使用%(name)s,所以使用params={'name':'value'}。
也就是可以以一个sql对于一个输出以这样的形式输出。
6.parse_dates
接受类型:{list or dict, default: None}
要分析为日期的列名列表。
{column_name:format string}Dict,其中format string在解析字符串时间时与strftime兼容,或者在解析整数时间戳时是(D、s、ns、ms、us)之一。
{column_name: arg Dict}Dict,其中arg Dict对应于pandas的关键字参数。to_datetime()对于不支持本机datetime的数据库(如SQLite)特别有用。
原转化的DataFrame各个字段数据类型为:

现在我们将time也转化为datetime形式:
sql_table ='metric_value' df_sql=pd.read_sql(sql_table,engine,parse_dates=['time']) df_sql.dtypes
可见time转化为了datetime类型:

这是使用了to_datetime()函数来达成该功能 ,导致直接使用unix从1970-0-0 00:00开始计算,不了解原理可以去看这篇:Pandas中to_datetime()转换时间序列函数一文详解
我们在后面加个format就能转换为我们想要的类型:
sql_table ='metric_value' df_sql=pd.read_sql(sql_table,engine,parse_dates={'time' :{"format": "%Y%m%d"}}) df_sql

7.columns
接受类型:{list, default: None}
从SQL表中选择的列名列表(仅在读取表时使用)。
sql_table ='metric_value' df_sql=pd.read_sql(sql_table,engine,columns=['time','code','value']) df_sql

8.chunksize
接受类型:{int, default None}
如果指定,则返回一个迭代器,其中chunksize是每个块中要包含的行数。
sql_table ='metric_value' df_sql=pd.read_sql(sql_table,engine,columns=['time','code','value'],chunksize=int) df_sql
得到一个SQLtable迭代类型:
三、返回参数
DataFrame or Iterator[DataFrame]
返回DataFrame或是SQL的迭代器。