
本文作者 夏俊伟 阿里云智能高级产品专家
MaxCompute产品与生态架构
MaxCompute是一个具有先进架构的Serverless云数据仓库,自从商业化后,使用的用户涉及各个行业的头部客户。在生态上需要支持主流的开源产品以及阿里云云产品。其主要包括以下几个方面:
- 数据接入生态。目前官方提供多种数据接入方式,可以接入绝大多数的数据库,NOSQL库,消息队列,日志等业务系统。
- 数据引擎生态。MaxCompute除了自身支持SQL引擎,Spark,mars,Graph等,还支持第三方引擎平台接入,例如实现底层直读Hologres引擎,PAI人工智能平台,智能搜索,智能推荐等。
- 数据开发管理工具生态。MaxCompute除了官方推出的Dataworks以外,还支持开源的Kettle,Airflow以及Azkaban平台,对数据进行开发治理调度等操作。
- 数据湖生态。MaxCompute除了可以计算自身存储数据,还可以联合mysql等关系型数据库,Hbase,TableStore,Lindorm等NoSQL数据库,DLF+OSS对象存储,HDFS和HUDI等大数据文件系统做联合计算。
- 数据应用生态。目前除了可以直接接入QuickBI官方数据BI平台,同时也支持市面主流的开源和商业化BI数据分析工具,例如Superset和Tableau等。
MaxCompute产品生态架构
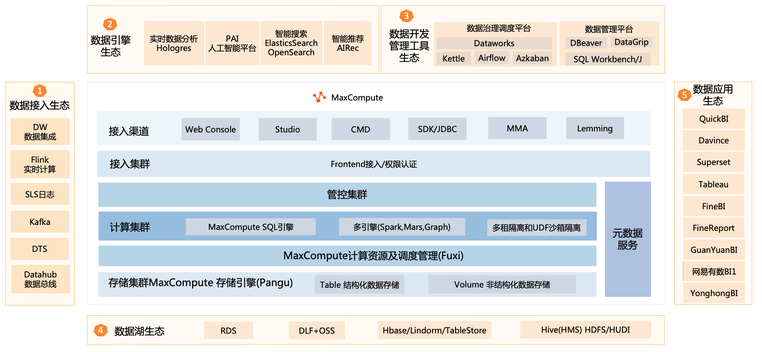
MaxCompute产品生态

数据接入生态
MaxCompute官方提供DataWorks数据集成,可以支持几十种数据集成接入或者数据导出。同时也支持主流的时实Kafka,Datahub数据直接写入;也支持SLS日志直接写入。
DataWorks数据集成
提供数据读取(Reader)和写入插件(Writer)实现对数据源的读写操作,您可以根据要同步的来源与去向数据源,并结合离线同步支持的数据源情况,进行同步任务的配置。离线同步支持单表的增量与全量数据读写、分库分表的增量与全量数据读。也可以支持您将多种输入及输出数据源搭配组成同步链路进行单表或整库数据的实时增量同步,还可以支持多种数据源之间进行不同数据同步场景(整库离线同步、全增量实时同步)的同步解决方案。
数据集成为MaxCompute提供丰富的数据通道,方便用户直接接入数据或者导出数据。详细操作请点击。
DataHub
DataHub是流式数据(Streaming Data)的处理平台,提供对流式数据的发布 (Publish),订阅(Subscribe)和分发功能,让您可以轻松构建基于流式数据的分析和应用。数据总线 DataHub服务可以对各种移动设备,应用软件,网站服务,传感器等产生的大量流式数据进行持续不断的采集,存储和处理。用户可以编写应用程序或者使用流计算引擎来处理写入到数据总线 DataHub的流式数据比如实时Web访问日志、应用日志、各种事件等,官方已经深度集成DataHub数据写入MaxCompute。详细操作请点击。
消息队列Kafka版
消息队列Kafka版是阿里云提供的分布式、高吞吐、可扩展的消息队列服务。消息队列Kafka版广泛用于日志收集、监控数据聚合、流式数据处理、在线和离线分析等大数据领域,已成为MaxCompute大数据生态中不可或缺的部分,用户可以方便的通过Kafka把数据写入MaxCompute。详细操作请点击。
日志服务SLS
日志服务SLS是云原生观测与分析平台,为Log、Metric、Trace等数据提供大规模、低成本、实时的平台化服务。日志服务一站式提供数据采集、加工、查询与分析、可视化、告警、消费与投递等功能,全面提升您在研发、运维、运营、安全等场景的数字化能力。用户可以方便快捷的把数据从SLS写入MaxCompute。详细操作请点击。
DTS
数据传输服务DTS(Data Transmission Service)是阿里云提供的实时数据流服务,支持RDBMS、NoSQL、OLAP等,集数据迁移/订阅/同步于一体,为您提供稳定安全的传输链路。详细操作请点击。
数据引擎生态
MaxCompute自研SQL引擎,兼容hive语法,同时也支持开源Spark引擎,集成了Mars,Graph图计算引擎。用户还可以通过MaxCompute CUPID自主接入Presto,kylin等开源引擎进行数据分析计算。同时用户可以适配不同业务场景,引入不同计算引擎,其中就包括:
Hologres
用户在做实时报表,实时数据看板,在线数据服务等高可用,高响应的场景,需要引入Hologres做实时数仓分析服务。为用户提供快速响应的在线数据分析服务。目前MaxCompute跟Hologres已经完成底层数据打通,可以直接进行读写。更进一步提升数据服务效率。详细操作请点击。
PAI人工智能平台
用户在营销场景,金融交易风控场景,已经智能决策,智能语音客服等场景都需要智能化算法模型支持,PAI可以提供一站式的机器学习解决方案。同时PAI也跟MaxCompute深度集成,PAI可以利用MaxCompue强大的分布式计算能力,为PAI进行模型训练,数据计算。详细操作请点击。
智能搜索引擎
用户在文字、图片等搜索场景需要强大的搜索引擎,MaxComput可以为搜索和推荐引擎提供海量的数据存储和计算能力。
- OpenSearch
OpenSearch是大规模分布式搜索引擎搭建的一站式智能搜索业务开发平台,通过内置各行业的查询语义理解、机器学习排序算法等能力,提供充分开放的引擎能力,助力开发者快速搭建智能搜索服务。同时跟MaxCompute深度集成,MaxCompute为OpenSearch提供海量数据存储与数据计算能力。详细操作请点击。
- Elasticsearch
Elasticsearch致力于打造基于开源生态的、低成本、场景化的云上Elasticsearch解决方案,源于开源,又不止于开源。基于云上超强的计算和存储能力,以及在集群安全和运维领域积累的技术经验,阿里云Elasticsearch不仅支持集群一键部署、弹性伸缩、智能运维和各类内核引擎优化,还提供了迁移、容灾、备份和监控等全套解决方案。MaxCompute为Elasticsearch提供海量数据存储与数据计算能力。详细操作请点击。
智能推荐
智能推荐AIRec(Artificial Intelligence Recommendation,简称AIRec)基于阿里巴巴大数据和人工智能技术,结合在电商、内容、新闻资讯、视频直播和社交等多个行业领域的积累,MaxCompute为AIRec提供海量数据存储与数据计算能力。详细操作请点击。
数据开发管理工具生态
数据管理
目前MaxCompute支持以下几种开源数据仓库管理工具对接MaxCompute,对MaxCompute的项目进行管理。
DBeaver
DBeaver是一款免费的多平台数据库工具,适用于开发人员、数据库管理员、分析师和所有需要使用数据库的人员。更多DBeaver信息,请参见DBeaver。对接MaxCompute后,可以通过DBeaver对MaxCompute的项目进行管理,可以直接查看MaxCompute的表,表结构,以及表数据等操作。详细操作请点击。
DataGrip
DataGrip是面向开发人员的数据库管理环境,为查询、创建和管理数据库提供便利。数据库可以在本地、服务器或云中工作。更多DataGrip信息,请参见DataGrip。对接MaxCompute后,可以通过DataGrip对MaxCompute的项目进行管理,可以直接查看MaxCompute的表,表结构,以及表数据等操作。详细操作请点击。
SQL Workbench/J
SQL Workbench/J是一个免费的、独立于DBMS(Database Management System)的、跨平台的SQL查询工具。SQL Workbench/J采用Java语言编写,可以在任何提供Java运行环境的操作系统上运行。更多SQL Workbench/J信息,请参见SQL Workbench/J。对接MaxCompute后,可以通过SQL Workbench/J对MaxCompute的项目进行管理,可以直接查看MaxCompute的表,表结构,以及表数据等操作。详细操作请点击。
数据开发调度平台
MaxCompute除了可以用官方推出的DataWorks做数据集成,数据开发任务调度,任务运维,数据分析以及数据服务等,同时也支持主流开元数据开发管理工具。
官方平台
DataWorks
DataWorks基于MaxCompute大数据引擎,为数据仓库、数据湖、湖仓一体等解决方案提供统一的全链路大数据开发治理平台。详细操作请点击。
开源工具
目前MaxCompute支持以下开源数据开发调度工具对接MaxCompute,可以在这些平台上开发数据任务作业,作业调度等。
- Kettle
MaxCompute支持您通过ETL工具Kettle实现MaxCompute作业调度。您可以通过拖拽控件的方式,方便地定义数据传输的拓扑结构。详细操作请点击。
- Airflow
MaxCompute支持您使用Apache Airflow通过Python接口实现作业调度。详细操作请点击。
- Azkaban
MaxCompute支持您通过Azkaban实现作业调度,帮助您高效地完成高频数据分析工作。详细操作请点击。
数据湖生态
MaxCompute不仅可以对自身存储的数据进行高效快捷的进行计算,同时也可以通过外表,湖仓一体(External Schema+Foriegn Server)的方式进行数据联合计算。
外部表
目前MaxCompute支持RDS,OSS,TableStore,Hbase/Lindorm以外表的方式进行联合计算。用户可以不加载数据进MaxCompute,也可以方便的用MaxCompute进行数据联合计算。详细操作请点击。
湖仓一体
目前MaxCompute湖仓一体,可以支持DLF+OSS/HDFS/HUDI等多种数据源,进行湖仓一体联合计算。用户可以在MaxCompute建立外围数据源,通过External Schema对外围数据源进行元数据统一管理,做联合计算。详细操作请点击。
数据应用生态
目前MaxCompute已经对接市场上主流的BI智能分析工具,可以让用户方便的在BI智能分析工具上对MaxCompute的数据进行分析以及展现。主要对接的商业智能分析工具有阿里云产品Quick BI,同时也支持主流的开源和商业化BI产品,例如开源BI分析工具superset商业BI分析工具Tableau等。
Quick BI
智能分析套件Quick BI是一个专为云上用户量身打造的新一代智能BI服务平台。Quick BI可以提供海量数据实时在线分析服务,支持拖拽式操作和丰富的可视化效果,帮助您轻松自如地完成数据分析、业务数据探查、报表制作等工作。MaxCompute深度集成Quick Bi,方便用户在Quick BI做数据分析展现。详细操作请点击。
Tableau
MaxCompute支持您将MaxCompute项目数据接入Tableau进行可视化分析,您可以利用Tableau简便的拖放式界面,自定义视图、布局、形状、颜色等,帮助您展现自己的数据视角。详细操作请点击。
FineBI
MaxCompute支持您将MaxCompute项目数据接入FineBI,帮助企业的业务人员和数据分析师开展以问题为导向的探索式分析工作。连接FineBI和MaxCompute项目,并进行可视化数据分析。详细操作请点击。
FineReport
MaxCompute支持您将MaxCompute项目数据接入FineReport,您通过简单拖拽式操作便可制作中国式复杂报表。连接FineReport和MaxCompute项目,并进行报表分析。详细操作请点击。
观远BI
MaxCompute支持您将MaxCompute项目数据接入观远BI,帮助企业的业务人员和数据分析师开展以问题为导向的探索式分析工作以及制作数据卡片和数据看板。连接观远BI和MaxCompute项目,并进行可视化数据分析。详细操作请点击。
网易有数BI
MaxCompute支持您将MaxCompute项目数据接入网易有数BI,帮助您轻松完成数据分析和数据可视化工作。使用网易有数BI连接MaxCompute项目,并进行可视化数据分析具体详细操作请点击。
Yonghong BI
MaxCompute支持您将MaxCompute项目数据接入Yonghong BI,帮助您轻松完成数据分析和数据可视化工作。详细操作请点击。
Superset
MaxCompute支持您将MaxCompute项目数据接入Superset,帮助您快速、轻量、直观地探索和可视化分析数据。详细操作请点击。
Davinci
MaxCompute支持您将MaxCompute项目数据接入Davinci,您只需在可视化UI界面上简单配置即可服务多种数据可视化应用。详细操作请点击。
MaxCompute架构与开放性
MaxCompute为了让用户更好的用好产品,对外提供了开放连接集成能力。MaxCompute团队聚焦做好核心存储与计算能力。目前可以通过以下几种对接方式与MaxCompute做集成。
MaxCompute开放架构

SDK
目前MaxCompute支持Java和Python版本的SDK提供给外围系统进行集成管理。用户也可以通过SDK对MaxCompute的实例,资源,项目,表等进行管理,同时可以通过SDK提交SQL Task进行数据计算,如果用户需要自定义函数,可以通过java/python开发UDF,UDAF跟UDTF,开发自己的业务逻辑,然后上传并注册。在SQL作业中直接使用。详细操作请点击。
JDBC
为了方便用户使用,MaxCompute还提供了JDBC驱动,用户可以通过JDBC接入,可以通过标准的JDBC接口基于MaxCompute执行海量数据的分布式计算查询,目前用户主要用JDBC对MaxCompute的数据进行查询,例如BI智能分析平台,采用的都是JDBC方式连接进行数据分析查询。详细操作请点击。
Tunnel
用户可以通过Tunnel upload命令把指定目标地址上数据上传到MaxCompute,支持表,分区级别的数据上传。可以通过download的命令把MaxCompute的数据下载到指定目标地址或者本地,可以支持下载某个表或者某个分区的数据,同时也支持下载某个SQL instance计算好的结果数据。为了避免网络因素导致数据上传下载中断的情况,MaxCompute tunnel还支持断点续传功能。详细操作请点击。
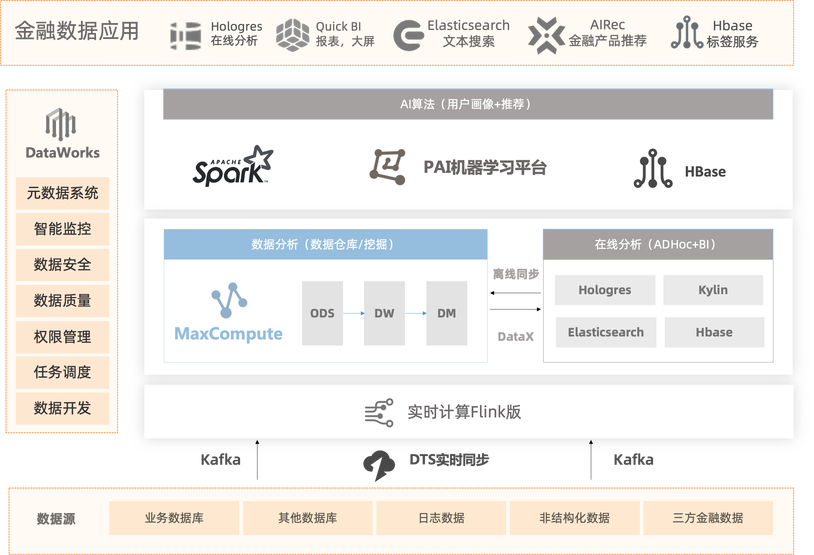
开放性与生态场景实践
某金融互联网公司,全业务上了阿里云后,大数据选择了MaxCompute作为核心计算引擎,搭建了大数据平台,相比之前自建的模式,计算速度提升了10倍,成本节省了三成。
- 数据源的数据通过kafka,DTS实时同步。
- 接入Flink后做实时数据计算,计算完后的数据实时写入MaxCompute做离线分析,数据仓库搭建。
- 集成Dataworks数据开发调度平台,对数据进行加工开发调度,数据管理,包括数据安全,数据质量,权限等。
- 数据同步到Hologres,kylin,ES,Hbase做实时数据业务场景应用,包括在线分析,标签服务,报表看板,搜索,推荐等。
产品架构
总结
MaxCompute的生态在不断完善中,为企业带来更丰富的组件,为用户提供更好服务。在开放性上,MaxCompute会开放更多能力,跟大数据生态产品做集成。在资源调度上会基于K8s推出fuxi调度引擎统一调度版,在平台管理上会逐渐开发标准restful API接口,更方便用户做集成。在开放更多能力的同时,会推出明确的产品限制项和能力边界,提供有保障的高质量服务。


