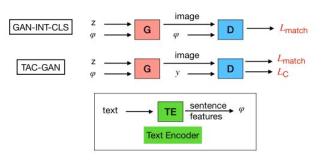
@[TOC](根据输入的食材自动生成菜肴照片 CookGAN: Causality based Text-to-Image Synthesis(基于因果关系的文本图像合成 ))
文章被2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)会议录用。
论文地址:https://ieeexplore.ieee.org/document/9157040/citations#citations
CookGAN旨在解决因果关系效应。食物图像的因果演化隐含在一个连续的网络中。
本博客是精读这篇论文的报告,包含一些个人理解、知识拓展和总结。
一、原文摘要
本文从一个新的角度,即图像生成中的因果链,讨论了文本到图像的合成问题。因果关系是烹饪中常见的现象。菜肴外观的变化取决于烹饪动作和配料。合成的挑战在于,生成的图像应该描述作用在物体上的视觉结果。本文提出了一种新的网络结构CookGAN,它模仿因果链中的视觉效果,保留细粒度细节,并逐步向上采样图像。特别地,提出了一个烹饪模拟器子网络,通过一系列步骤,基于配料和烹饪方法之间的交互,对食物图像进行增量更改。在Recipe1M上的实验验证了CookGAN能够以相当可观的初始分数生成食物图像。此外,图像具有语义可解释性和可操作性。
二、关键词
Image generation、Gallium nitride、Generators、Visualization、Image resolution、Semantics、Feature extraction
三、为什么提出CookGAN?
生成性对抗网络(GAN)自在T2I领域应用以来,在解决照片真实感质量和语义一致性问题方面取得了许多进展。虽然这两个方面都强调图像质量,但忽略了:图像生成中的因果视觉场景。
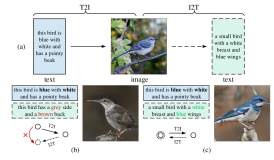
之前的文本都是描述图像中预期的视觉内容的视觉叙事句子,而面对以行动为导向的文本则难以生成,比如:“将鸡肉丁用烤花生搅拌”对应的图像。
 在这里插入图片描述
在这里插入图片描述
CookGAN是研究从菜谱到图像的合成,用烹饪菜谱描述 生成 食物图像,菜谱将食物和配料作为实体,将烹饪步骤作为行动,以文本形式指导菜肴的制作,最后呈现最终准备好的菜肴。CookGAN在因果情景的逐步学习中生动地模仿烹饪过程。
其主要解决了四个问题:
1)允许烹饪步骤和配料之间进行明确的交互
2)学习菜肴在不同步骤上的演变,以便即时修改配料和说明,使菜肴的新颖效果可视化
3)可以模拟成分作用的捆绑效应。例如,鸡蛋的形状取决于一个动作是煮、煎还是蒸
4)了解食材对菜肴的可见性和影响。例如,“糖”可能是看不见的,而“番茄酱”可以显著改变菜肴的外观。
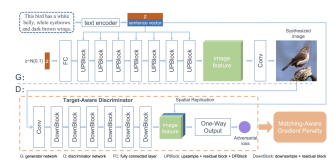
四、模型结构
 在这里插入图片描述
在这里插入图片描述
4.1、结构分析
与StackGAN++有些许相似,CookGAN包括三个生成器和三个判别器,组成堆叠的结构。最初,菜谱文本描述被编码器编码联合噪声后生成菜谱文本特征。将该文本特征输入到上采样块中,转为隐藏层图像特征。之后第一个生成器利用这个图像特征生成64×64的初始图像并联合第一个判别器进行判别。图像特征同时被输入到烹饪模拟器当中,为下一阶段的生成器准备特征。第二个和第三个生成器重复以上过程,最终生成256×256的图像。
4.2、损失函数
整体的损失函数为:

损失主要有两部分:生成器损失项和CA损失项。
 为第i个生成器的损失,
为第i个生成器的损失, 是条件反射增强(CA)的损失, λ是平衡因子。
是条件反射增强(CA)的损失, λ是平衡因子。
生成器损失与以往的模型相似,由无条件损失项和条件损失项组成,无条件损失项鉴别真假图像,条件损失项鉴别图像是否符合文本描述,生成器损失为:

其中的判别器损失为:
{\varphi_{r} \sim p_{r}, z \sim p_{z}}\left[\log \left(1-D_{i}\left(G_{i}\left(\varphi_{r}, z\right)\right)\right)\right]} {\text {unconditional loss }}+ \ \underbrace{\mathbb{E}{\varphi_{r} \sim p_{r}, z \sim p_{z}}\left[\log \left(1-D_{i}\left(G_{i}\left(\varphi_{r}, z\right), \varphi_{r}\right)\right)\right]}_{\text {conditional loss }}) \end{array} unconditional loss E φ r ∼ p r , z ∼ p z [ log ( 1 − D i ( G i ( φ r , z ) ) ) ] + conditional loss E φ r ∼ p r , z ∼ p z [ log ( 1 − D i ( G i ( φ r , z ) , φ r ) ) ] )网络异常,图片无法展示|

其中 是从真实食物图像分布的第i个尺度 抽样的样本,第i个判别器仅在
是从真实食物图像分布的第i个尺度 抽样的样本,第i个判别器仅在 和第i个生成器生成的图像做判别。
和第i个生成器生成的图像做判别。
与StackGAN相同,CA损失是避免过度拟合的正则化器,并加入了文本流形插值,CA损失函数如下:

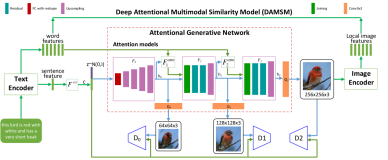
五、烹饪模拟模块
烹饪模拟模块是这篇论文里最主要的创新,烹饪模拟模块主要是模拟真实的烹饪场景,其将不同的切割方式和烹饪手段逐渐施加在食材上面。例如,“胡萝卜”被切成薄片,“意大利面”在与“鱿鱼酱”一起炒时变成黑色。
 在这里插入图片描述
在这里插入图片描述
如上图所示:
1) 表示食材特征,其中
表示食材特征,其中 表示的是第m个食材的第
表示的是第m个食材的第 维向量。
维向量。
2) 表示的是第i尺度的图像特征(上一阶段所提供的),其中C是通道深度,L=W×H是特征图的分辨率。
表示的是第i尺度的图像特征(上一阶段所提供的),其中C是通道深度,L=W×H是特征图的分辨率。
3) 是将食材特征与图像特征相结合而成的image attended ingredient features,姑且我叫它参入食材因子的图像特征,
是将食材特征与图像特征相结合而成的image attended ingredient features,姑且我叫它参入食材因子的图像特征, ,其中f()是1×1的卷积核,它将食材特征映射到与第i尺度隐藏图像特征Vi相同的维度,而σ(·) 是softmax函数,它输出一个大小为L的注意力图
,其中f()是1×1的卷积核,它将食材特征映射到与第i尺度隐藏图像特征Vi相同的维度,而σ(·) 是softmax函数,它输出一个大小为L的注意力图 ,带有概率值,以指示成分的空间分布。 softmax函数生成的注意力图与相应的成分
,带有概率值,以指示成分的空间分布。 softmax函数生成的注意力图与相应的成分 相乘确定成分的空间位置 ,最后每个维度求和,形成第j通道图像成分特征图 。
相乘确定成分的空间位置 ,最后每个维度求和,形成第j通道图像成分特征图 。
4)之后进入通过Gated Recurrent Unit单元 (一种循环神经网络,以下简称GRU):
 为顺序编码后的烹饪步骤,其中
为顺序编码后的烹饪步骤,其中 ,其中
,其中 是第n条烹饪步骤的第
是第n条烹饪步骤的第 维向量。
维向量。 为参入食材因子的图像特征(image attended ingredient features),一个步骤中烹饪的结果,即GRU的隐藏状态,被送入下一个GRU单元进行后续烹饪操作 。
为参入食材因子的图像特征(image attended ingredient features),一个步骤中烹饪的结果,即GRU的隐藏状态,被送入下一个GRU单元进行后续烹饪操作 。
 表示的是第i个尺度第j个通道的被烹饪的食物特征。
表示的是第i个尺度第j个通道的被烹饪的食物特征。
5)最后,将三组特征映射Vi(图像特征)、 (参入食材因子的图像特征)、
(参入食材因子的图像特征)、 (进过烹饪模拟后的食物特征)连接起来,并馈送到剩余块中。变换后的特征映射将成为下一轮图像上采样的输入。
(进过烹饪模拟后的食物特征)连接起来,并馈送到剩余块中。变换后的特征映射将成为下一轮图像上采样的输入。
ps:烹饪模拟器可处理多达10个烹饪步骤。考虑到计算时间,超过十步的指令会被截断。
六、实验
6.1、编码器
食材编码器(ingredient encoder),使用了word2vec嵌入,其将单词转换成高阶向量(300维),
烹饪步骤编码器(ingredient encoder),使用了skip-thoughts 技术,其将步骤形式的句子转化成固定高阶向量(1024维), 。
。
6.2、数据集
Recipe1M:包含成对的食谱和图像。该数据集提供340922对配方图像
下载:http://im2recipe.csail.mit.edu/
6.3、评价指标
Inception score (IS):IS值越高,表示视觉多样性和质量越好。
median rank (MedR):MedR值越低,检索能力越好
 在这里插入图片描述
在这里插入图片描述
6.4、实验效果
 在这里插入图片描述
在这里插入图片描述
6.5语义解释
作者认为,生成的图像不仅应该在视觉上有吸引力,而且在语义上可以解释。文章设计了三个任务来测量生成图像的可解释性:食材识别(Ingredient recognition)、图像到食谱的回溯(Image-to-recipe retrieval)、图像到图像的回溯(Image-to-image retrieval )
1)食物识别:就是在生成的食品图像中对配料进行多重标记,然后与食谱中用到的真实食材进行对比,下图列出了CookGAN生成的两个样本图像的识别成分。可以看出不仅可以识别可见的成分,还可以识别不可见的成分,但也有很多错误识别(蓝色为错误)的部分。
 在这里插入图片描述
在这里插入图片描述
2)图像到食谱的回溯(Image-to-recipe retrieval),是一种逆向任务,由生成的图像反向查询检索对应的食谱。
3)图像(生成)到图像(真实)的回溯(Image-to-image retrieval ):也是一种逆向任务,使用生成的图像检索真实的食物图像。
6.6、对菜谱的动态修改
CookGAN的一个优点是,可以通过对菜谱或者配方的增量操作(例如,通过语义变化的配料列表)动态生成图像。如下图:
 在这里插入图片描述
在这里插入图片描述
更有趣的事情是,CookGAN能够学习到菜肴中食材的可见度,如下图,当加入糖时,食物图片的外观基本不变,但当加入番茄酱时,颜色显著改变。
 在这里插入图片描述
在这里插入图片描述
而烹饪方法的改变也会使食物展现出来的外观不同,下图是鸡蛋在不同烹饪方法下,生成的食物图片的状态:
 在这里插入图片描述
在这里插入图片描述
7、小结
实验结果表明,CookGAN能够合成真实的视觉场景来描述烹饪行为的因果关系。与StackGAN++相比,CookGAN能够通过烹饪行为模拟出合适的颜色、形状和成分。
此外,CookGAN展示出了对烹饪常识的一些理解,包括处理食材的可见度(糖和番茄酱的例子)和食材与烹饪手段的捆绑效应(鸡蛋的不同做法)。图像具有语义可解释性和可操作性。