游客ykfym5dqgv3xk_个人页

文章
4
问答
8
视频
0
个人介绍
暂无个人介绍
擅长的技术
- 容器
- 数据库

暂无更多信息
2022年09月
-
09.29 16:43:50
 提交了问题
2022-09-29 16:43:50
提交了问题
2022-09-29 16:43:50
-
09.29 16:35:28提交了问题
2022-09-29 16:35:28
-
09.29 16:27:24提交了问题
2022-09-29 16:27:24
-
09.23 11:57:54提交了问题
2022-09-23 11:57:54
-
09.23 11:56:48提交了问题
2022-09-23 11:56:48
-
09.15 14:31:51提交了问题
2022-09-15 14:31:51
-
09.15 09:52:02提交了问题
2022-09-15 09:52:02
2022年04月
-
04.01 15:48:26
 回答了问题
2022-04-01 15:48:26
回答了问题
2022-04-01 15:48:26
2022年03月
-
03.02 14:59:52
 发表了文章
2022-03-02 14:59:52
发表了文章
2022-03-02 14:59:52
阿里云MaxCompute权限管理和安全配置文档问卷调研
为了提升MaxCompute权限管理和安全配置文档的质量,确保文档能更好地为您服务,本次问卷调研重点收集您对这两个模块文档的意见或建议,问卷填写大概需要花费您5-10分钟。您的反馈对文档改进尤为重要,期待收到您的反馈~
2021年06月
-
06.08 14:28:34发表了文章
2021-06-08 14:28:34
【文档小窍门】填写用户反馈的正确姿势
在使用产品帮助文档过程中,遇到问题了?更加困惑了?莫慌,手把手教你如何摆好填写用户反馈的正确姿势,助力文档更好地为您服务~~~
-
06.08 14:10:14发表了文章
2021-06-08 14:10:14
【文档小窍门】填写用户反馈的正确姿势
在使用产品帮助文档过程中,遇到问题了?更加困惑了?莫慌,手把手教你如何摆好填写用户反馈的正确姿势,助力文档更好地为您服务~~~
2021年03月
-
03.26 17:13:18发表了文章
2021-03-26 17:13:18
文档搜索So easy
本文为您介绍如何通过阿里云官网提供的搜索入口快速检索产品帮助文档。
-
发表了文章
2022-03-02
阿里云MaxCompute权限管理和安全配置文档问卷调研
-
发表了文章
2021-06-08
【文档小窍门】填写用户反馈的正确姿势
-
发表了文章
2021-06-08
【文档小窍门】填写用户反馈的正确姿势
-
发表了文章
2021-03-26
文档搜索So easy
滑动查看更多
-
回答了问题
2022-12-23
请问如果想用Windows进行深度学习计算时,选择哪种服务比较合适?谢谢
赞0 踩0 评论1 -
回答了问题
2022-12-19
maxcompute sql自定义函数执行报错correlated to columns out of function def is not allowed
看起来似乎是自定义的SQL函数和调用的时候,列不一致。。你可以把自定义SQL函数和调用自定义SQL全部代码贴一下。
另外,自定义函数的指导文档可以参考一下,先把文档里面的代码跑通知道个大概流程先:指导文档。
赞0 踩0 评论1 -
回答了问题
2022-12-07
天任务依赖当天所有的小时实例,是否其中有一个小时实例运行失败,天任务就无法运行
天任务默认依赖小时任务当天所有实例,挂上依赖的任务需要全都成功,下游才会执行,所以如果天任务依赖了小时任务,小时任务运行失败的话,会导致天任务无法执行
赞0 踩0 评论0 -
回答了问题
2022-11-22
-
回答了问题
2022-11-17
dataworks计算
这个细节计算逻辑估计得看详细日志对比才行,建议直接工单找MaxCompute售后同学确认一下。
赞0 踩0 评论0 -
回答了问题
2022-11-11
dataworks数据集成用josn调度
用DataWorks的数据集成的同步解决方案功能吧,可以参考一下文档:https://help.aliyun.com/document_detail/302449.htm
 赞0 踩0 评论0
赞0 踩0 评论0 -
回答了问题
2022-11-09
黑窗口运行odps命名,一直报connect timed out
cmd连接MaxCompute失败了,可以参考文档检查一下连接的配置文件里的参数是不是都配置对了:https://help.aliyun.com/document_detail/27971.html#section-vd2-4me-7uu
赞0 踩0 评论0 -
回答了问题
2022-11-09
想问下在查看角色权限的时候发现了表权限下有个read权限,在表权限列表中并没有这个权限,是什么情况
这个read角色不是MaxCompute的内置角色,是DataWorks创建的,MaxCompute绑定到了DataWorks的工作空间后就会显示这些角色。
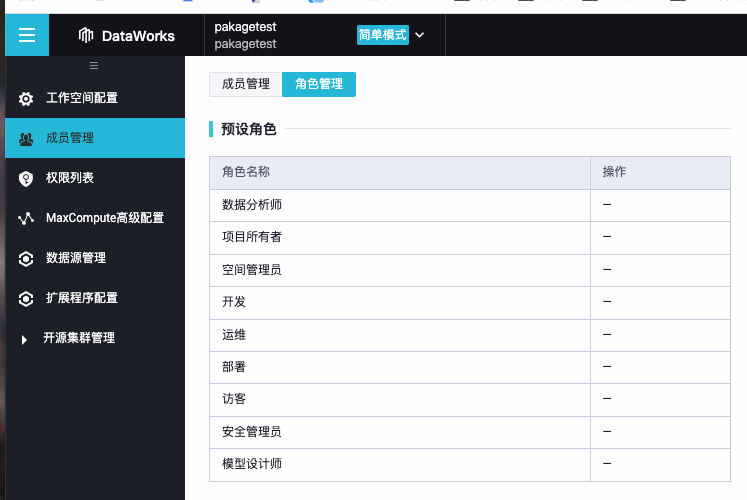
所以当前这个table的read权限应该主要是给DataWorks这边用的。
赞0 踩0 评论0 -
回答了问题
2022-11-09
odps无法获取id
cmd连接MaxCompute失败了,可以参考文档检查一下连接的配置文件里的参数是不是都配置对了:https://help.aliyun.com/document_detail/27971.html#section-vd2-4me-7uu
赞0 踩0 评论0 -
回答了问题
2022-11-08
DataWorks和ODPS能查看对应的版本号吗
DataWorks可以直接在控制台的“概述”页面就能看到各个地域下面开通的是什么版本的DataWorks,可以看到是开通的标准版还是企业版还是其他什么版本。
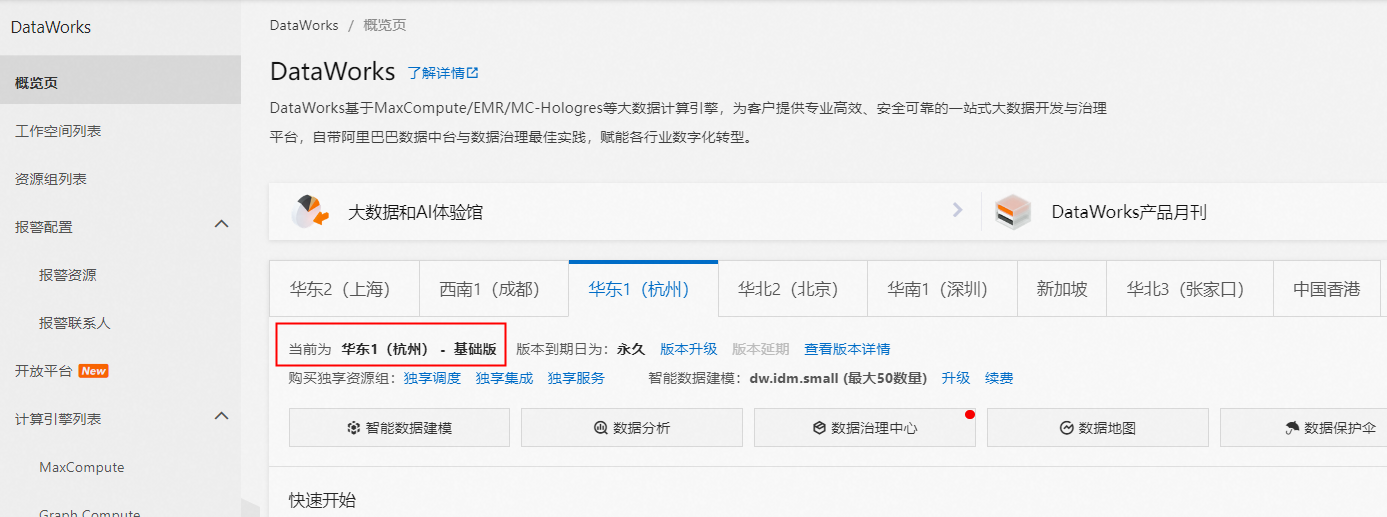
不太清楚MaxCompute版本号是指的什么,如果是想看MaxCompute是包年包月还是按量计费的话,也是直接登录MaxCompute的控制台就能看到了。
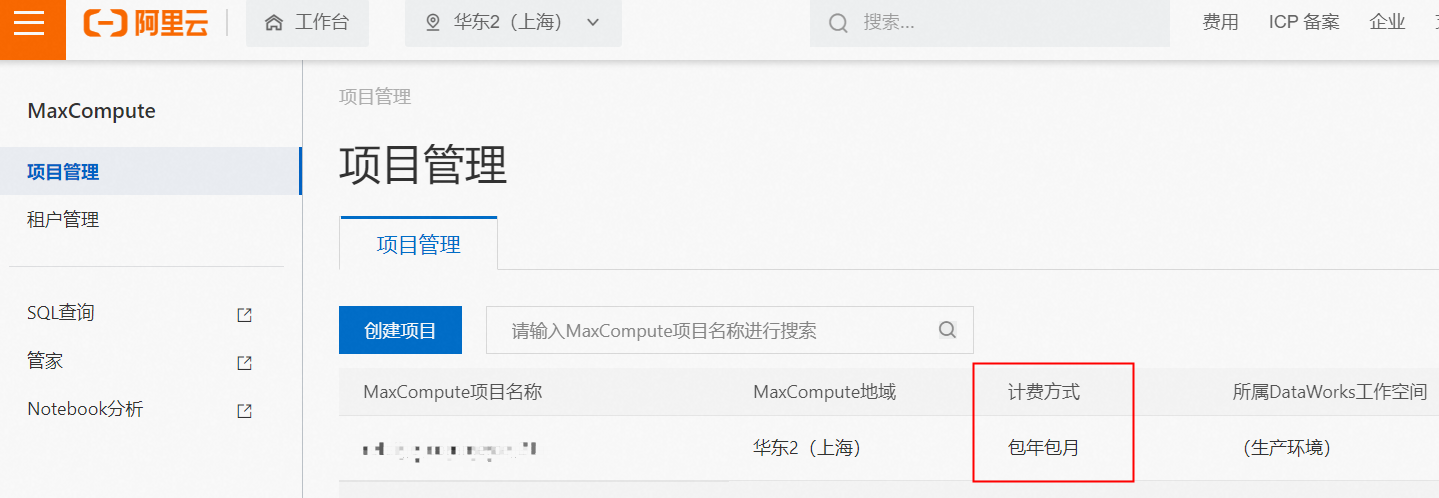 赞0 踩0 评论0
赞0 踩0 评论0 -
回答了问题
2022-11-07
Maxcompute的Sql查询所有权限内的project元数据
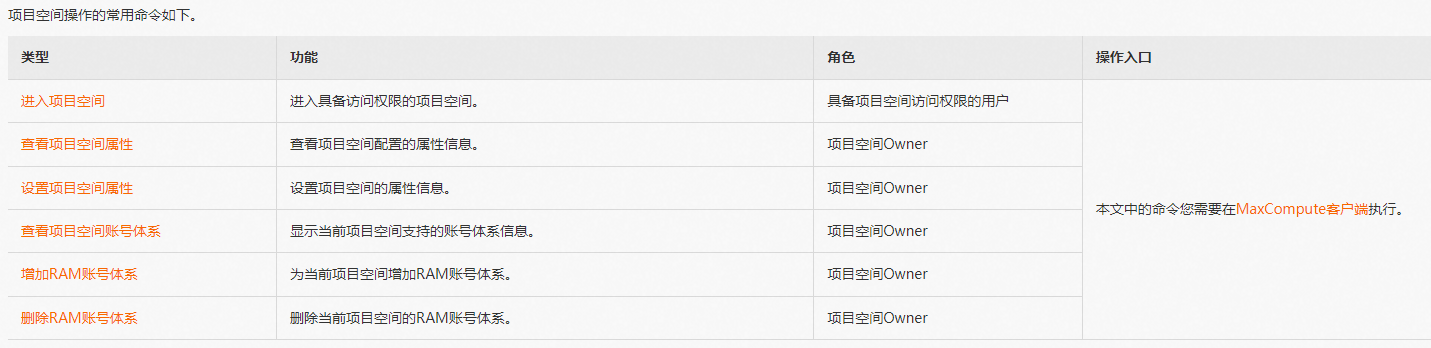
不确定你要查什么信息呢,一般项目的主要信息都可以通过查项目空间属性的命令来查,也就是setproject命令。
项目相关的命令都可以参考项目命令汇总的文档:https://help.aliyun.com/document_detail/27828.html
 赞0 踩0 评论0
赞0 踩0 评论0 -
回答了问题
2022-11-03
ES 基础监控,无数据
集群写入QPS指标展示了集群每秒写入文档的数量;集群查询QPS指标展示了集群每秒执行的查询QPS数量,如果您没有在集群上执行过查询和写入操作,是看不到监控数据的,请尝试写入或查询后再查看,对应指标的详细信息请参见查看集群监控。
赞0 踩0 评论0 -
回答了问题
2022-11-03
DATAWORKS调度
你这边是希望能把多张表同步到MaxCompute吗?不知道你的多表同步的场景是啥,DataWorks有不同的同步解决方案的:https://help.aliyun.com/document_detail/442340.html
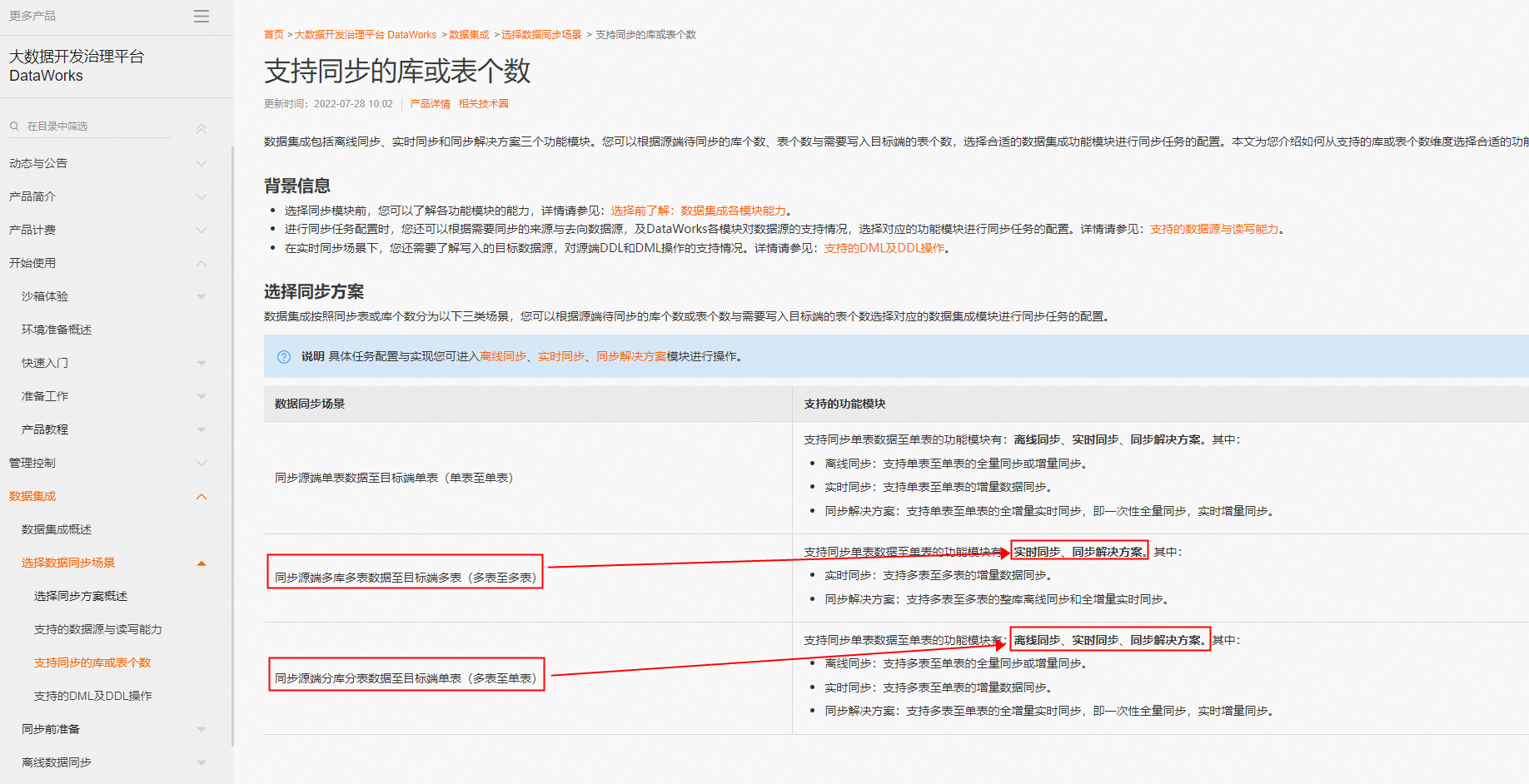
看你上面的截图,似乎是要做离线整库同步,如果是离线整库同步到MaxCompute的话,可以用DataWorks的数据集成的同步解决方案功能吧,可以参考一下文档:https://help.aliyun.com/document_detail/302449.htm
赞0 踩0 评论0 -
回答了问题
2022-10-31
自建ES迁移报错
这个问题是由于您使用的elasticsearch-repository-oss的版本不对,可在Github上下载对应版本的插件。如果Github上没有对应版本的插件包,建议您下载对应大版本的相近小版本的插件包,然后修改plugin-descriptor.properties文件中的参数值,重新打包再安装。可参考通过OSS将自建Elasticsearch数据迁移至阿里云的常见问题章节。
赞0 踩0 评论0 -
回答了问题
2022-10-28
MaxCompute odps天任务依赖小时任务
要保障小时任务全部运行完再运行天任务的话,可以在小时任务节点和天任务节点中间再加一个节点,这个节点就用来检测小时任务是否已经全部运行完成,或者24个小时任务也可以直接用循环节点来实现,这样就可以保证一定是循环完所有小时节点才会触发天任务的节点。循环节点的文档可以参考:https://help.aliyun.com/document_detail/297383.html
赞0 踩0 评论1 -
回答了问题
2022-10-25
dataworks数据集成
通过脚本方式连接DataWorks和达梦数据库的操作流程可以参考文档:https://help.aliyun.com/document_detail/137717.htm
上面的代码示例是从达梦数据库抽取数据到stream数据库的插件配置示例:
{
"stepType": "dm",
"parameter": {},
"name": "Reader",
"category": "reader"
},
是定义了一个dm类型的reader。
{
"stepType": "stream",
"parameter": {
"print": false,
"fieldDelimiter": ","
},
"name": "Writer",
"category": "writer"
}
是定义了一个stream类型的writer。
"order": {
"hops": [
{
"from": "Reader",
"to": "Writer"
}
]
}
是说明了数据传输是从reader到writer,也就是把数据从dm抽取然后写入stream。
你可以根据你的数据传输场景修改对应的代码。不同的数据库的配置方式可以从文档里面链接过去参考看看:https://help.aliyun.com/document_detail/137670.html
赞0 踩0 评论0 -
回答了问题
2022-10-21
使用PAI创建工作流,工作流数据存储(建议设置)提示“您还未创建 Bucket”但已经有bucket
可以查看一下创建的bucket的地域和创建的工作流地域是不是在同一个地域,不在同一个地域的话应该是识别不到的,会提示未创建bucket。
赞0 踩0 评论0 -
回答了问题
2022-10-12
Logstash JDBC数据mysql同步es的延迟时间大概有多少
具体延迟时间需要你实际数据场景测试,目前只能说logstash方案适用的场景是能接受延迟秒级别的;若对实时性要求高推荐参考 同步方案选取指南:https://help.aliyun.com/document_detail/170426.html 中 DTS的方式实现数据同步
赞0 踩0 评论0 -
提交了问题
2022-09-29
如何查看Elasticsearch集群的shard分配情况,不符合预期时如何调整?
滑动查看更多
暂无更多信息