游客wkxim4agoo6le

已加入开发者社区717天
勋章

专家博主
专家博主

星级博主
星级博主

技术博主
技术博主

初入江湖
初入江湖



我关注的人
粉丝

技术能力
兴趣领域
擅长领域
技术认证
暂时未有相关云产品技术能力~
暂无个人介绍
暂无精选文章
暂无更多信息
2022年05月
-
05.19 15:04:12
 发表了文章
2022-05-19 15:04:12
发表了文章
2022-05-19 15:04:12
-
05.19 15:00:08发表了文章
2022-05-19 15:00:08
-
05.19 14:52:42发表了文章
2022-05-19 14:52:42
-
05.19 14:48:03发表了文章
2022-05-19 14:48:03
-
05.19 14:24:43发表了文章
2022-05-19 14:24:43
-
05.19 14:16:11发表了文章
2022-05-19 14:16:11
-
05.19 14:14:23发表了文章
2022-05-19 14:14:23
-
05.19 14:09:48发表了文章
2022-05-19 14:09:48
-
05.19 14:06:54发表了文章
2022-05-19 14:06:54
-
05.19 14:04:09发表了文章
2022-05-19 14:04:09
-
05.19 14:01:46发表了文章
2022-05-19 14:01:46
数仓学习|初始数仓
笔记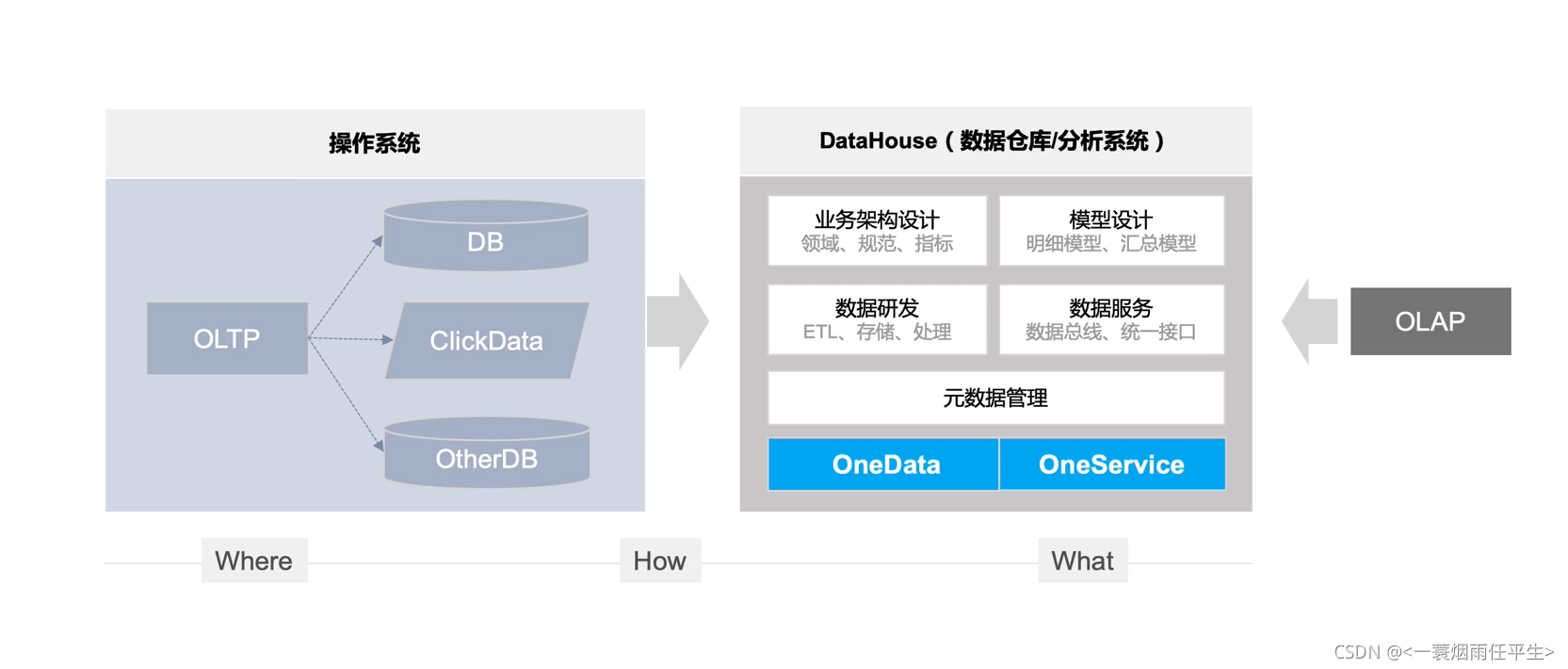
-
05.19 13:55:20发表了文章
2022-05-19 13:55:20
-
05.19 13:51:27发表了文章
2022-05-19 13:51:27
-
05.19 13:36:26发表了文章
2022-05-19 13:36:26
-
05.19 13:32:24发表了文章
2022-05-19 13:32:24
-
05.19 13:24:52发表了文章
2022-05-19 13:24:52
-
05.19 13:16:07发表了文章
2022-05-19 13:16:07
-
05.19 13:13:20发表了文章
2022-05-19 13:13:20
-
05.19 13:07:45发表了文章
2022-05-19 13:07:45
-
05.19 13:06:09发表了文章
2022-05-19 13:06:09
-
05.19 13:03:50发表了文章
2022-05-19 13:03:50
-
05.19 13:01:55发表了文章
2022-05-19 13:01:55
数据仓库之命名规则
笔记 -
05.19 13:01:01发表了文章
2022-05-19 13:01:01
数据仓库之理论概述
笔记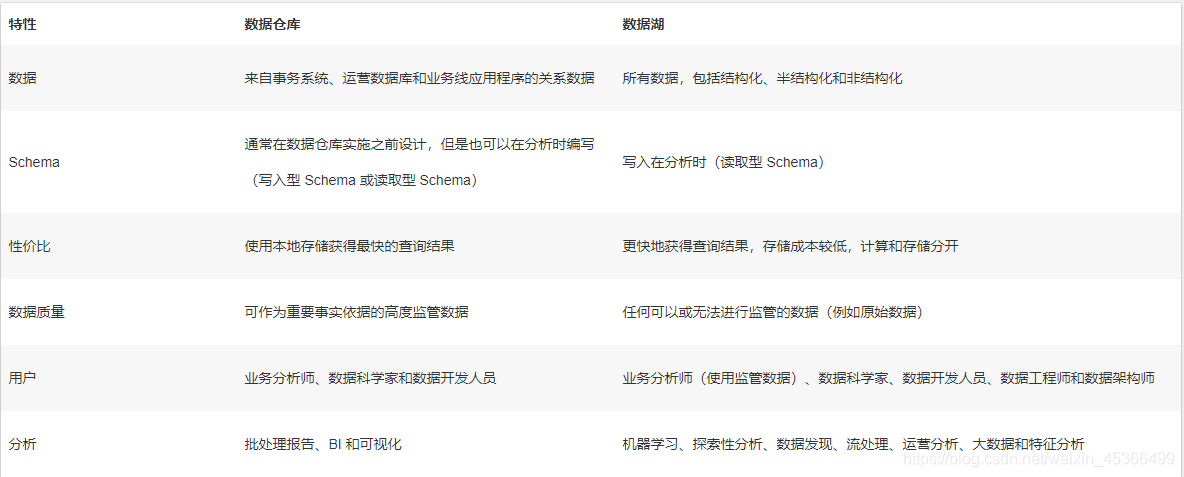
-
05.19 12:54:58发表了文章
2022-05-19 12:54:58
-
05.19 12:52:34发表了文章
2022-05-19 12:52:34
-
05.19 12:50:22发表了文章
2022-05-19 12:50:22
-
05.19 12:28:51发表了文章
2022-05-19 12:28:51
-
05.19 11:07:32发表了文章
2022-05-19 11:07:32
Spark作业调度中stage的划分
Spark在接收到提交的作业后,会进行RDD依赖分析并划分成多个stage,以stage为单位生成taskset并提交调度。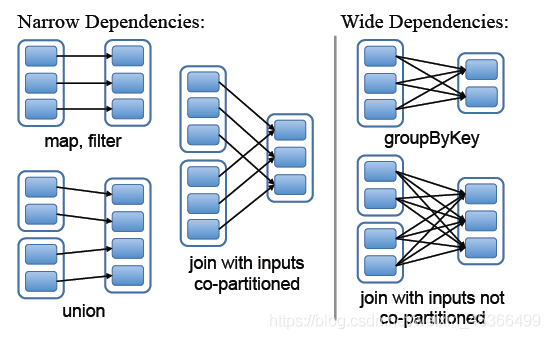
-
05.19 11:05:48发表了文章
2022-05-19 11:05:48
-
05.19 11:03:49发表了文章
2022-05-19 11:03:49
-
05.19 10:46:45发表了文章
2022-05-19 10:46:45
-
05.19 10:34:30发表了文章
2022-05-19 10:34:30
MySQL之子查询
笔记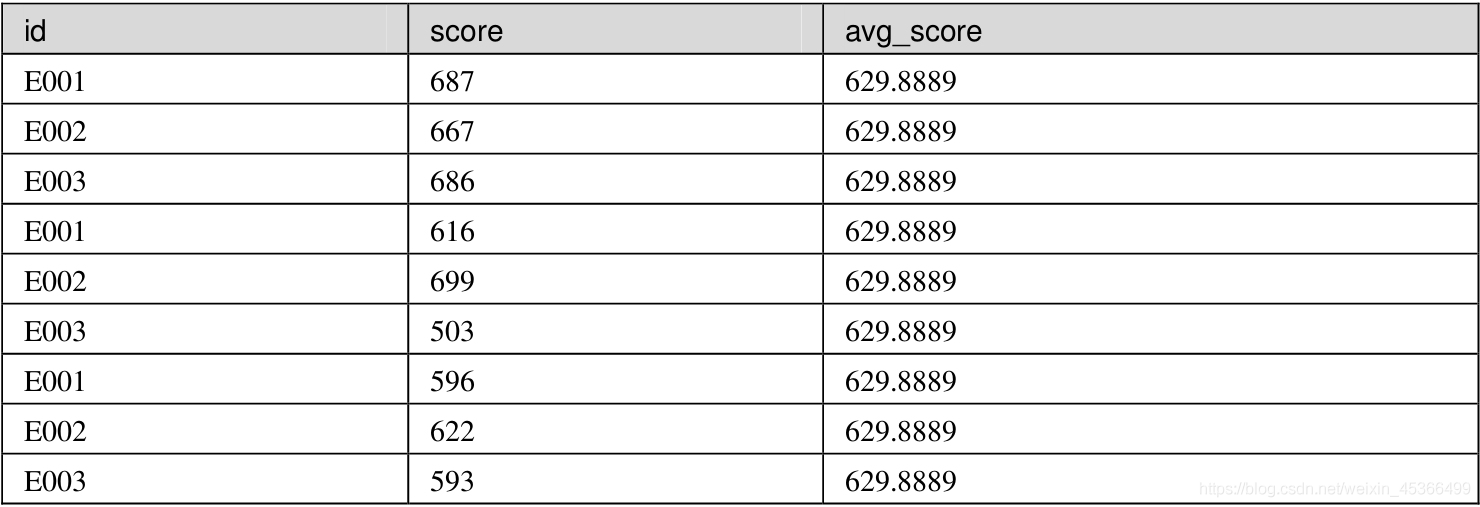
-
05.19 10:27:24发表了文章
2022-05-19 10:27:24
MySQL之多表连接
笔记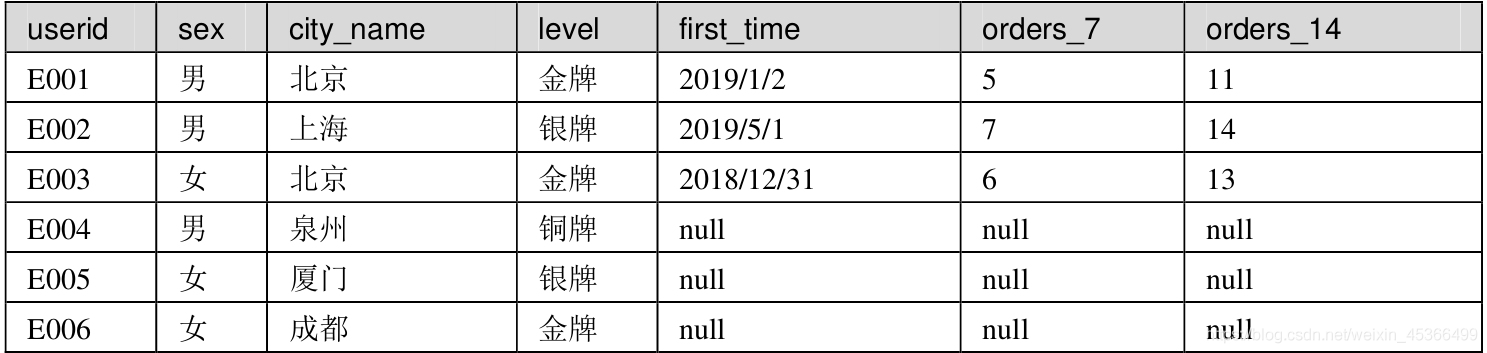
-
05.19 10:21:06发表了文章
2022-05-19 10:21:06
-
05.19 10:19:01发表了文章
2022-05-19 10:19:01
MySQL之窗口函数
笔记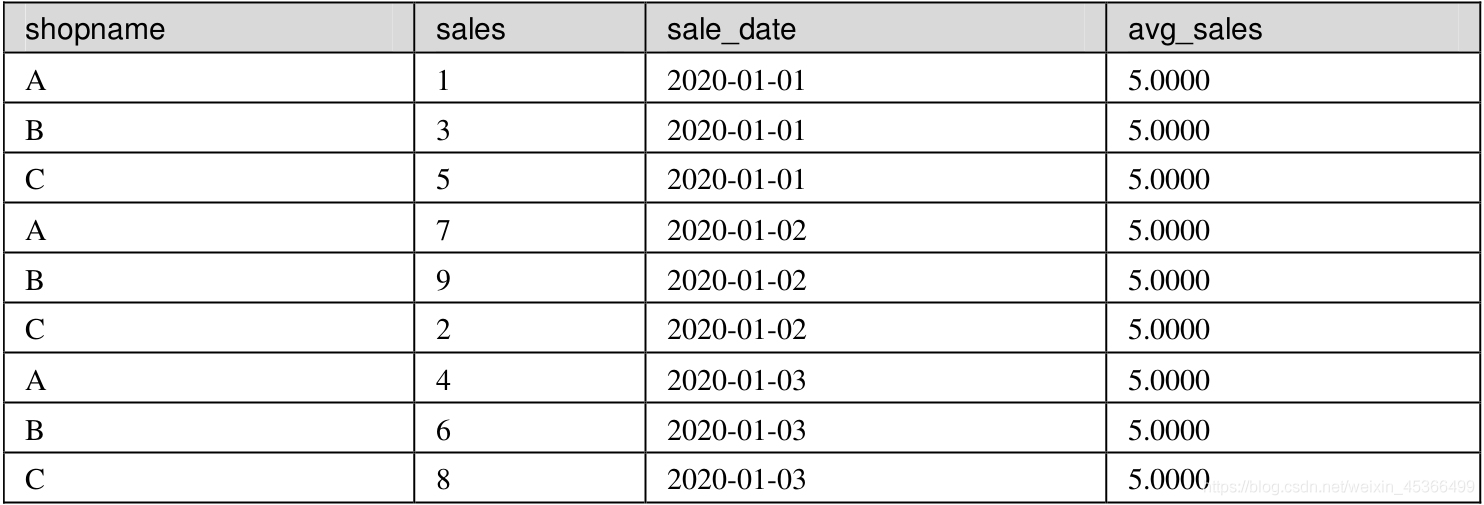
-
05.19 10:10:13发表了文章
2022-05-19 10:10:13
-
05.19 10:04:10发表了文章
2022-05-19 10:04:10
-
05.19 10:00:09发表了文章
2022-05-19 10:00:09
MySQL之控制函数
笔记 -
05.18 23:41:57发表了文章
2022-05-18 23:41:57
MySQL之数据运算
笔记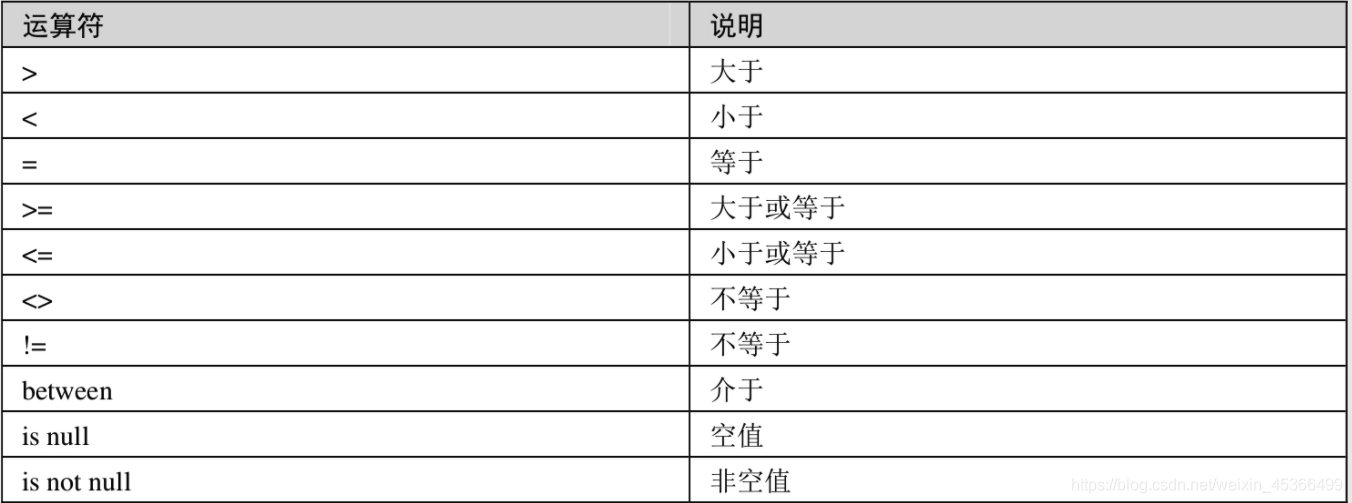
-
05.18 22:07:13发表了文章
2022-05-18 22:07:13
MySQL之数据预处理
笔记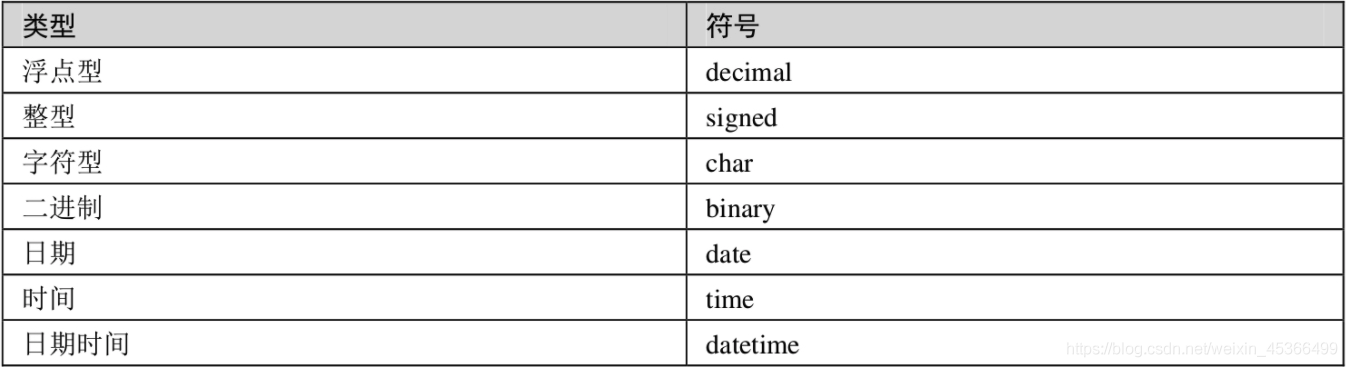
-
05.18 22:03:39发表了文章
2022-05-18 22:03:39
MySQL之数据的获取
笔记 -
05.18 21:58:34发表了文章
2022-05-18 21:58:34
-
05.18 21:54:58发表了文章
2022-05-18 21:54:58
-
05.18 21:50:05发表了文章
2022-05-18 21:50:05
-
05.18 21:39:02发表了文章
2022-05-18 21:39:02
-
05.18 21:29:10发表了文章
2022-05-18 21:29:10
-
05.18 21:13:19发表了文章
2022-05-18 21:13:19
-
05.18 21:10:55发表了文章
2022-05-18 21:10:55
-
05.18 21:06:41发表了文章
2022-05-18 21:06:41



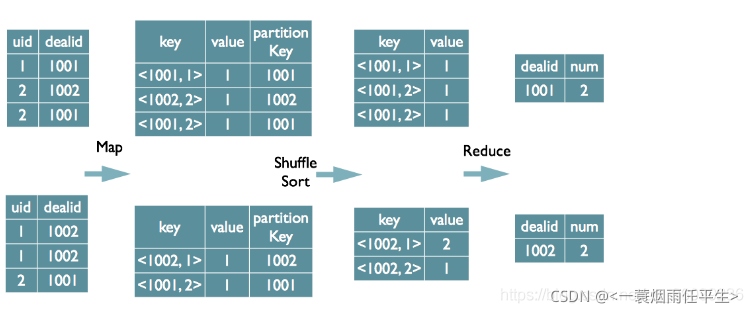
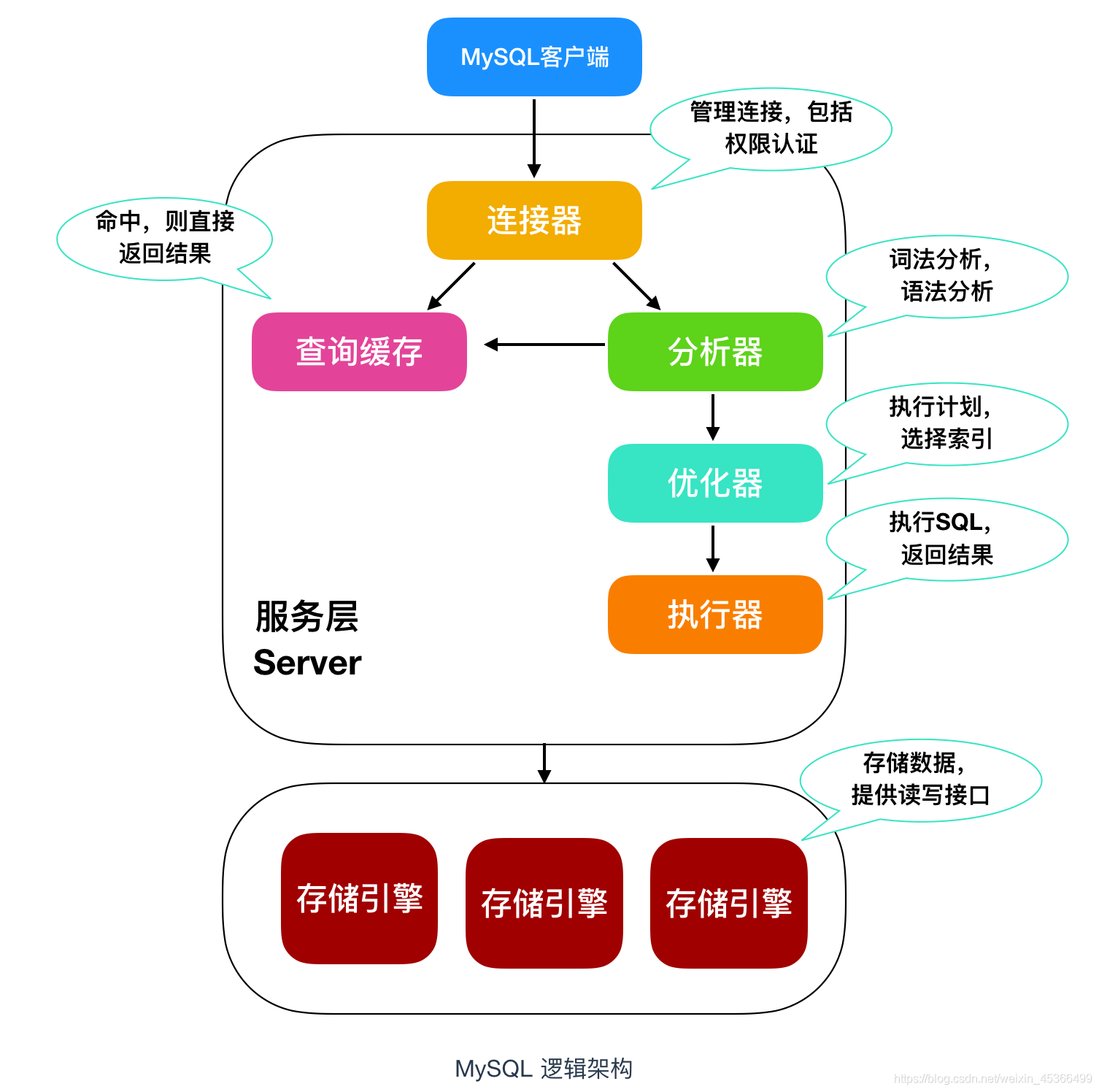


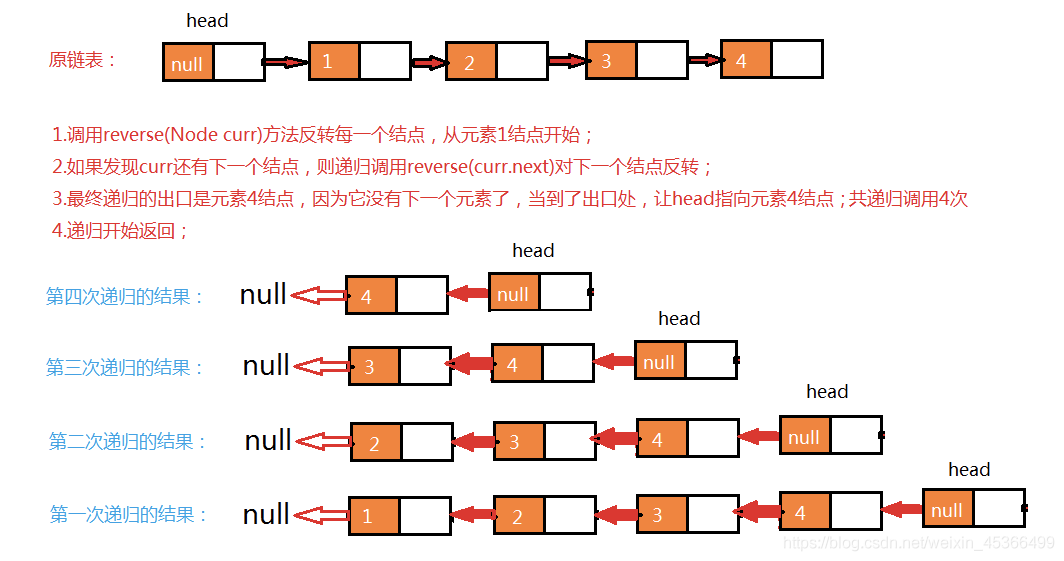
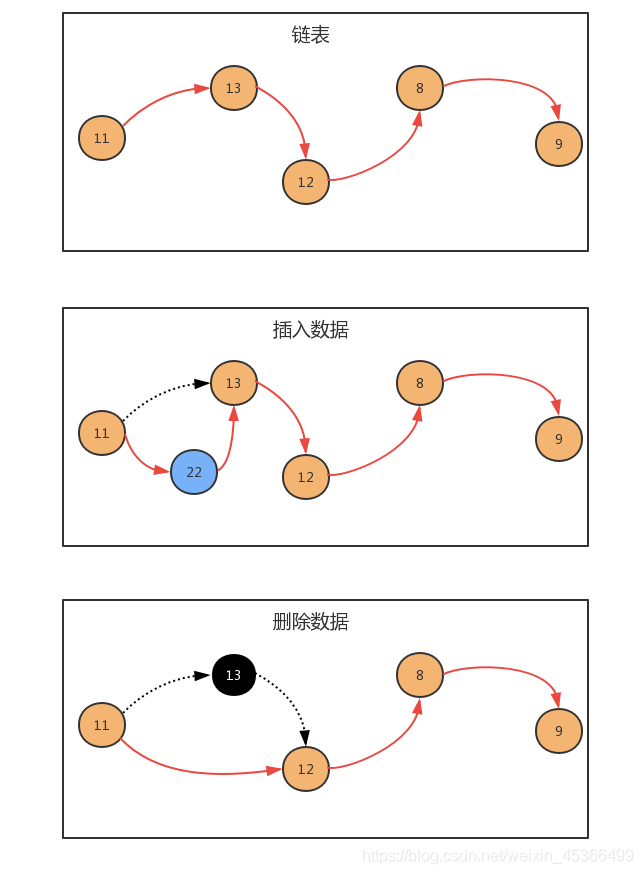





-
发表了文章
2022-05-19
一篇文章搞懂数据埋点与数据同步
-
发表了文章
2022-05-19
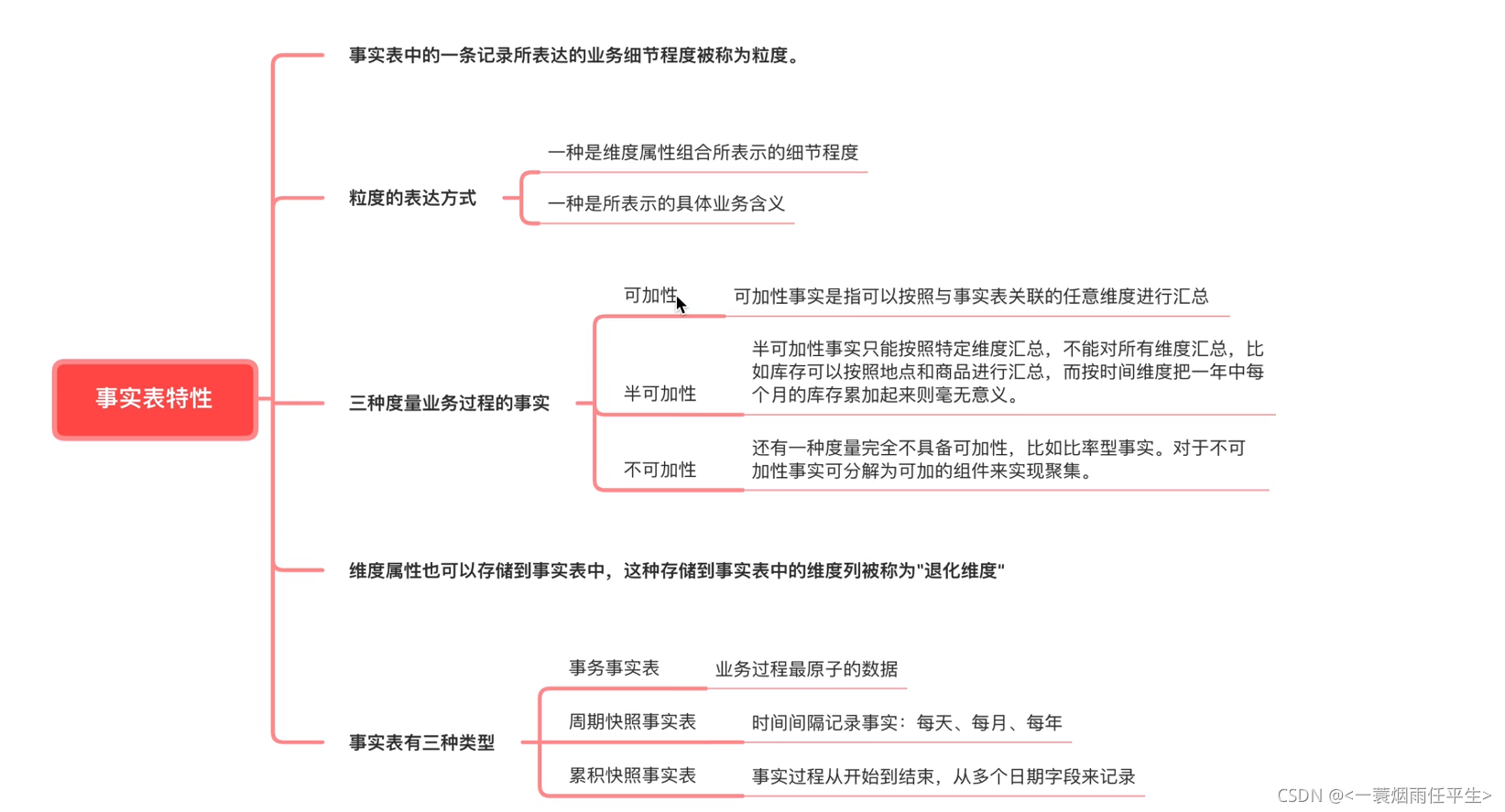
大数据开发工程师需要了解的【数仓中事实表的设计】
-
发表了文章
2022-05-19
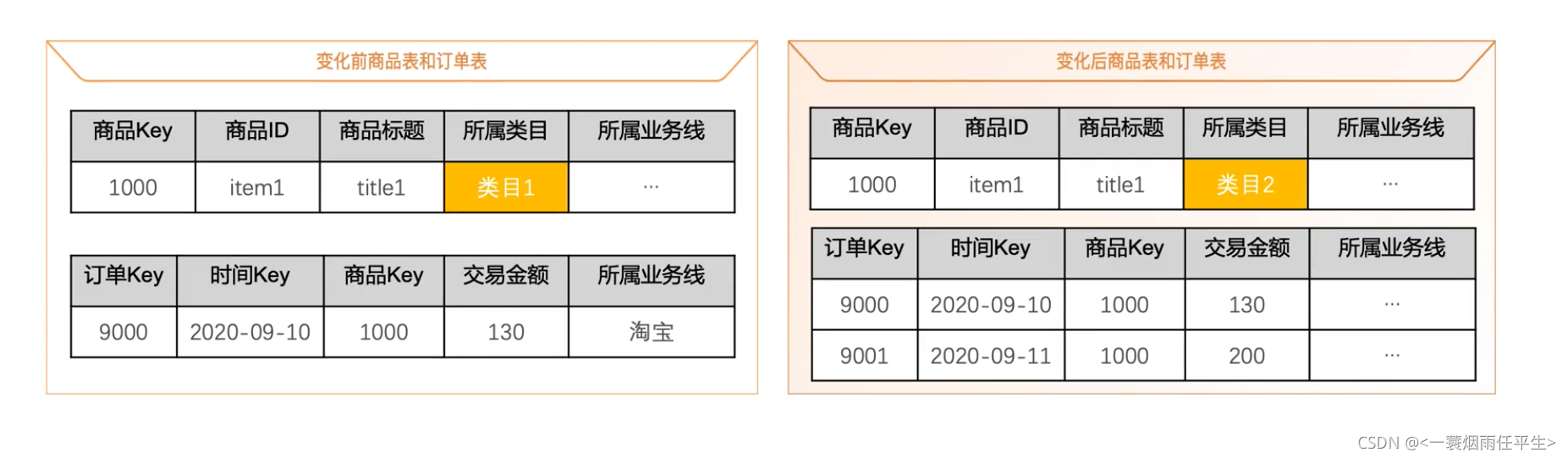
大数据开发工程师需要了解的【数仓中的维度设计】(二)
-
发表了文章
2022-05-19
大数据开发工程师需要了解的【数仓中的维度设计】(一)
-
发表了文章
2022-05-19
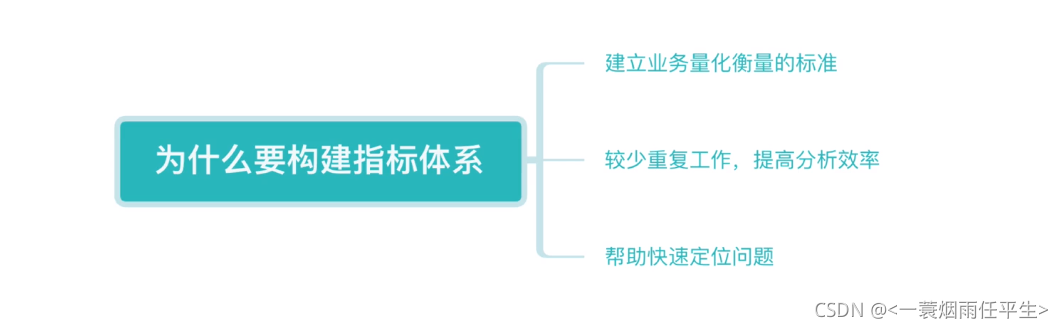
大数据开发工程师需要了解的【数仓中的指标体系】
-
发表了文章
2022-05-19
Hive中collect_list()排序问题详解
-
发表了文章
2022-05-19
一篇文章讲清楚数据仓库模型设计!
-
发表了文章
2022-05-19
数仓学习|几种常见的数据同步方式
-
发表了文章
2022-05-19
Hive Distinct 的实现原理
-
发表了文章
2022-05-19
Hive之count(distinct xxx)优化写法
-
发表了文章
2022-05-19
数仓学习|初始数仓
-
发表了文章
2022-05-19
MySQL常见面试题汇总(建议收藏!!!)(二)
-
发表了文章
2022-05-19
MySQL常见面试题汇总(建议收藏!!!)(一)
-
发表了文章
2022-05-19
MySQL聚簇索引和非聚簇索引的区别
-
发表了文章
2022-05-19
Java数据结构线性表之链表(二)
-
发表了文章
2022-05-19
Java数据结构线性表之链表(一)
-
发表了文章
2022-05-19
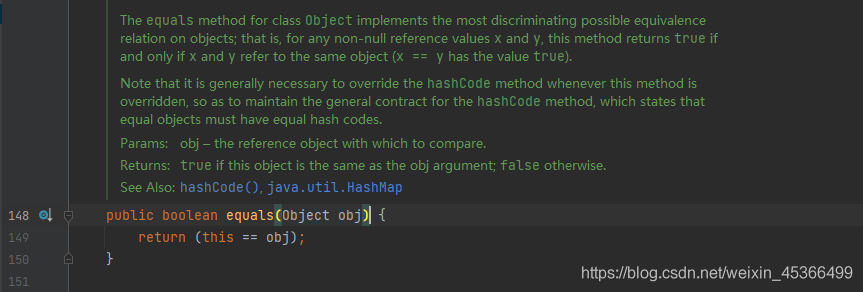
Day11-Java中String的equals方法如何实现
-
发表了文章
2022-05-19
Day10-Java中HashMap几种遍历方式与性能分析
-
发表了文章
2022-05-19
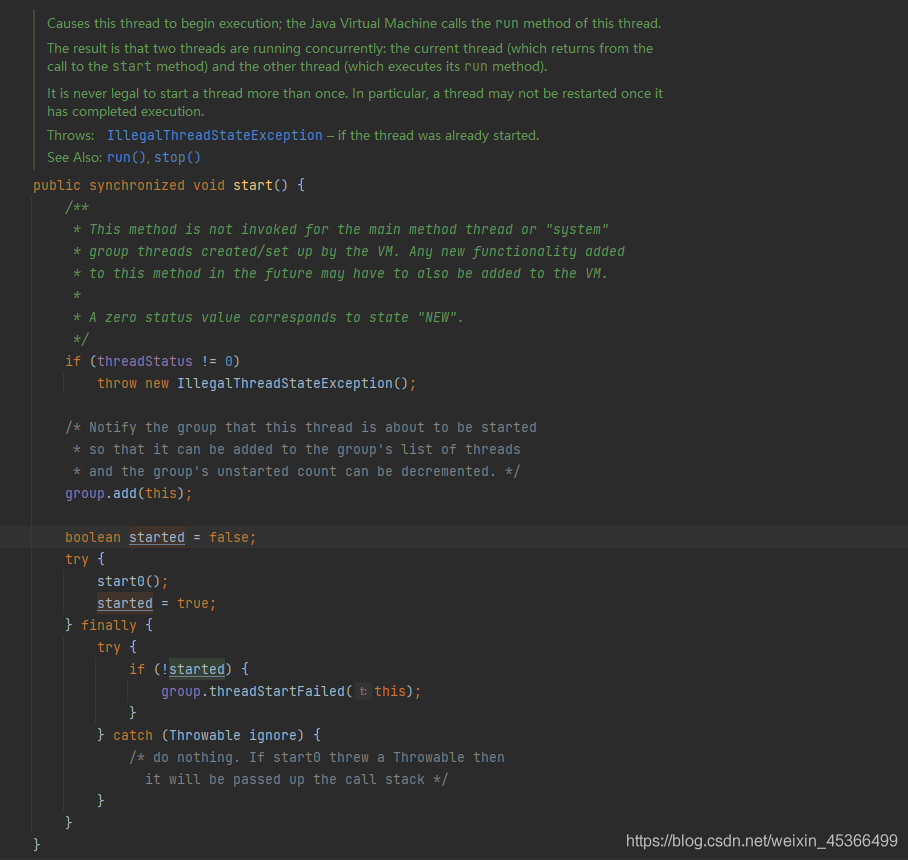
Day9-Java线程中run方法和start方法的区别
-
发表了文章
2022-05-19
Day8-Java线程中join方法的使用
滑动查看更多
暂无更多信息
暂无更多信息