游客3fxpohbdpoqm2

已加入开发者社区796天
勋章

专家博主
专家博主

星级博主
星级博主

技术博主
技术博主

初入江湖
初入江湖



我关注的人
粉丝
tgyd2018
tgyd2018
游客qfuf44o6up5ly
游客qfuf44o6up5ly
游客lm47cg7ncnx74
游客lm47cg7ncnx74
游客emf2xtyc5sqba
游客emf2xtyc5sqba

知行录
知行录
bxhd2n3rw5v2k
bxhd2n3rw5v2k
rszk5ovwu6q2g
rszk5ovwu6q2g
游客s4svehepihpke
游客s4svehepihpke
游客ymxeun55lff7y
游客ymxeun55lff7y
游客3f3o7rnhphcsu
游客3f3o7rnhphcsu
4emtowf52h2b2
4emtowf52h2b2
essay_tech
essay_tech
技术能力
兴趣领域
擅长领域
技术认证
暂时未有相关云产品技术能力~
暂无个人介绍
暂无精选文章
暂无更多信息
2022年04月
-
04.12 14:39:17
 发表了文章
2022-04-12 14:39:17
发表了文章
2022-04-12 14:39:17
又一款神器:半小时带你轻松上手k8s
之前我在自己本地的mac部署k8s的时候都是基于minikube去运行的,今天决定尝试学习一种新的方式去玩k8s,这次选择使用的是Rancher Desktop工具。下边是我入坑的一些记录,希望给有需要的读者能够提供一些帮助。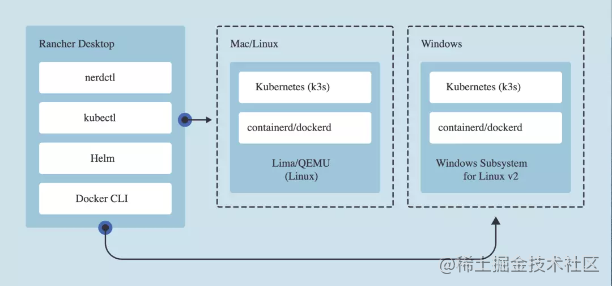
-
04.12 14:11:27发表了文章
2022-04-12 14:11:27
基本功:超全面 IO 流教程,小白也能看懂
Java领域的io模块是一个非常庞大的知识体系,在大家求职面试的过程中通常也是被问到比较多的一个模块,今天我特意整理了一份关于IO知识体系相关的干货和大家分享,希望各位读者们喜欢。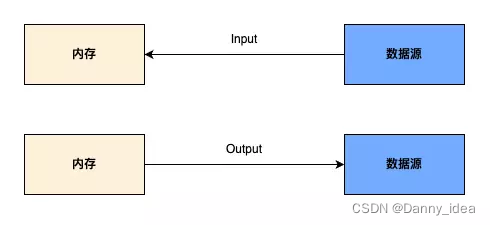
-
04.11 21:14:45发表了文章
2022-04-11 21:14:45
Spring Aop 常见注解和执行顺序
Spring Aop 常见注解和执行顺序
-
04.11 21:08:36发表了文章
2022-04-11 21:08:36
再见丑陋的 Swagger,这个API神器界面更炫酷,逼格更高,体验更好!
再见丑陋的 Swagger,这个API神器界面更炫酷,逼格更高,体验更好!
-
04.11 20:58:23发表了文章
2022-04-11 20:58:23
SpringCloud 微服务架构,适合接私活(附源码)
SpringCloud 微服务架构,适合接私活(附源码)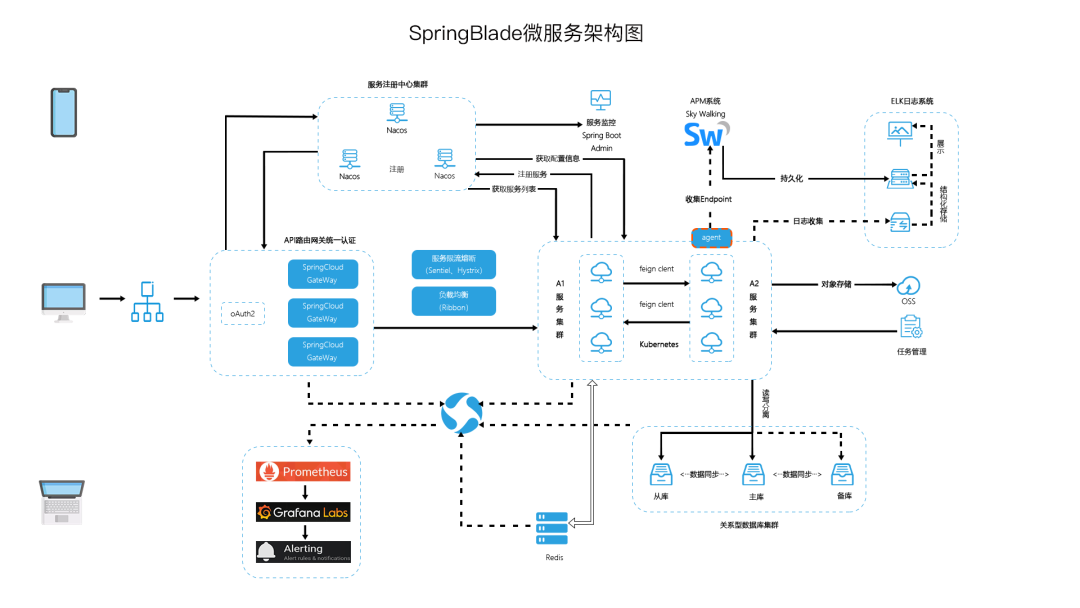
-
04.11 17:54:30发表了文章
2022-04-11 17:54:30
神器 Nginx 的学习手册 ( 建议收藏 )(二)
神器 Nginx 的学习手册 ( 建议收藏 )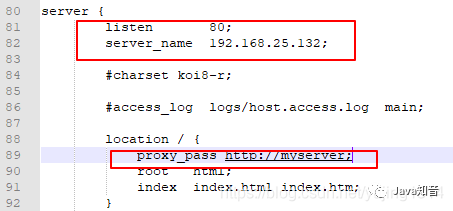
-
04.11 17:45:46发表了文章
2022-04-11 17:45:46
神器 Nginx 的学习手册 ( 建议收藏 )(一)
神器 Nginx 的学习手册 ( 建议收藏 )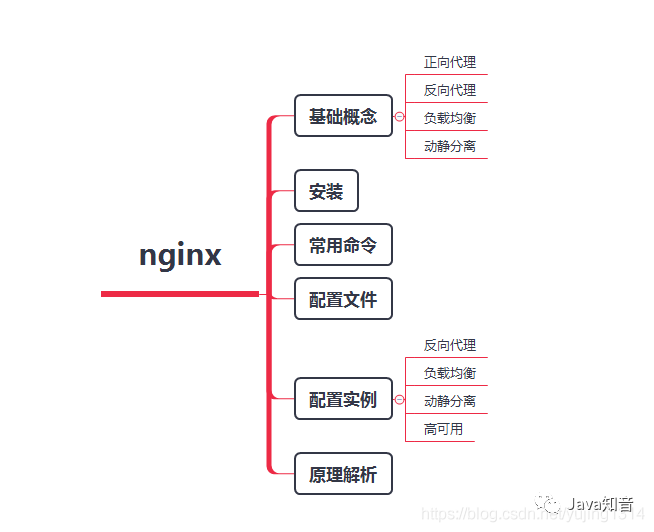
-
04.11 17:32:03发表了文章
2022-04-11 17:32:03
系统架构演变:SOA、微服务架构的区别和联系(下)
系统架构演变:SOA、微服务架构的区别和联系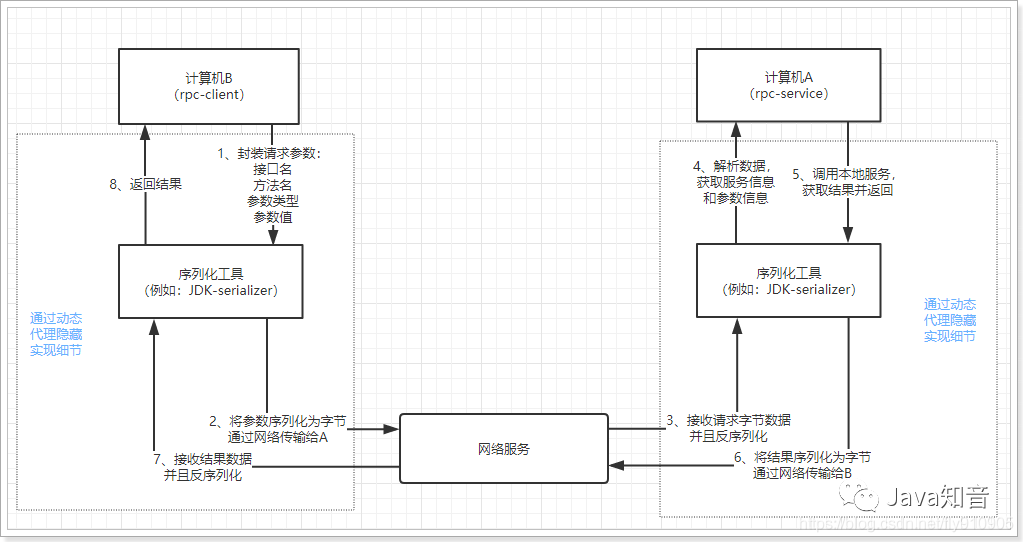
-
04.11 17:27:58发表了文章
2022-04-11 17:27:58
系统架构演变:SOA、微服务架构的区别和联系(上)
系统架构演变:SOA、微服务架构的区别和联系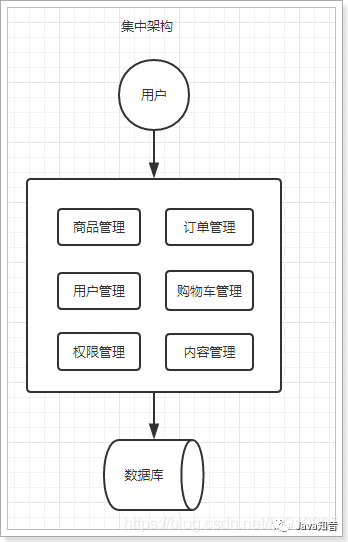
-
04.11 17:16:26发表了文章
2022-04-11 17:16:26
这几行代码,真的骚!
这几行代码,真的骚!
2022年02月
-
02.21 17:04:25发表了文章
2022-02-21 17:04:25
实战干货:基于Redis6.2 部署迷你版本消息队列(下)
实战干货:基于Redis6.2 部署迷你版本消息队列(下)
-
02.21 17:02:50发表了文章
2022-02-21 17:02:50
实战干货:基于Redis6.0 部署迷你版本消息队列(中)
实战干货:基于Redis6.0部署迷你版本消息队列(中) -
02.21 17:00:36发表了文章
2022-02-21 17:00:36
实战干货:基于Redis6.0 部署迷你版本消息队列(上)
实战干货:基于Redis6.0 部署迷你版本消息队列(上)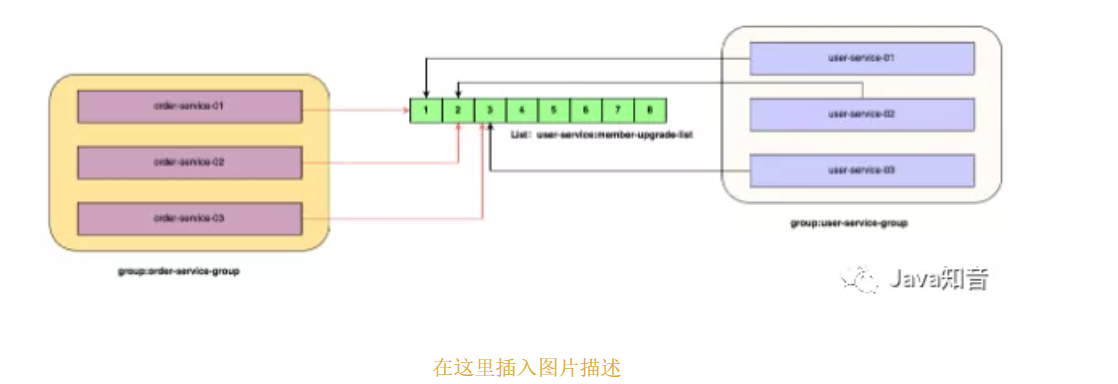
-
02.21 16:58:24发表了文章
2022-02-21 16:58:24
GitLab 配置 OAuth2 实现第三方登录,简直太方便了!
GitLab 配置 OAuth2 实现第三方登录,简直太方便了!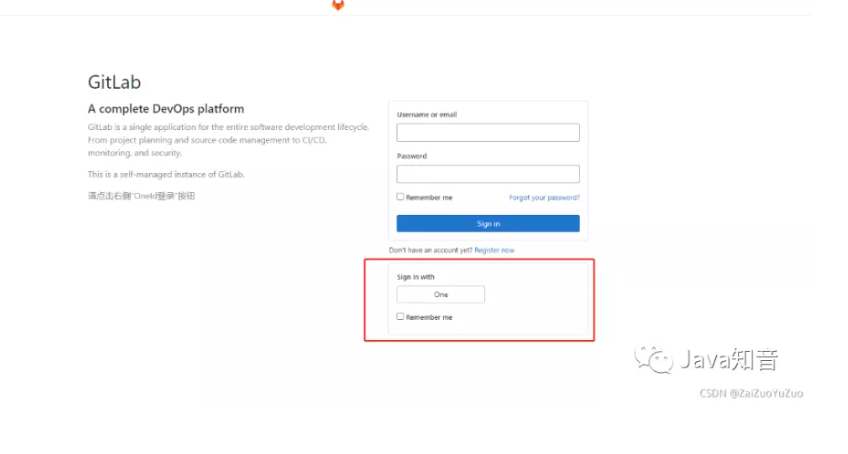
-
02.21 16:56:39发表了文章
2022-02-21 16:56:39
Mybatis 一连串提问,被面试官吊打了!
Mybatis 一连串提问,被面试官吊打了!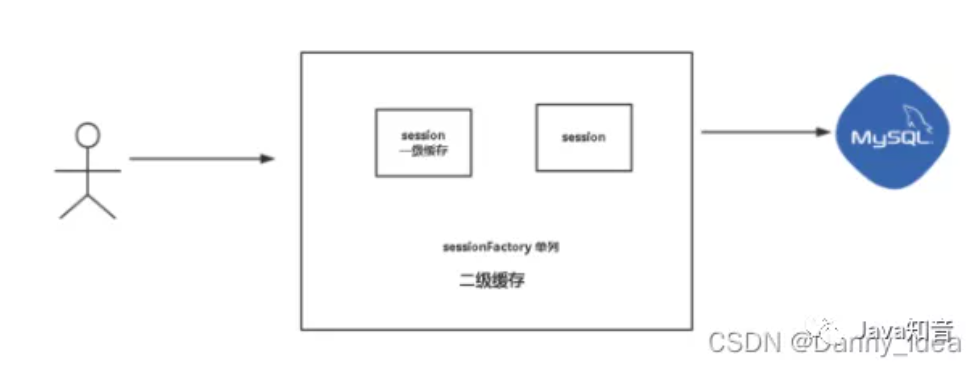
-
02.21 16:51:51发表了文章
2022-02-21 16:51:51
中招了,重写TreeMap的比较器引发的问题...(下)
中招了,重写TreeMap的比较器引发的问题...(下)
-
02.21 16:50:03发表了文章
2022-02-21 16:50:03
中招了,重写TreeMap的比较器引发的问题...(上)
中招了,重写TreeMap的比较器引发的问题...(上)
-
02.21 16:48:15发表了文章
2022-02-21 16:48:15
通俗讲解分布式锁:场景和使用方法
通俗讲解分布式锁:场景和使用方法 -
02.21 16:45:54发表了文章
2022-02-21 16:45:54
重磅发布:Redis 对象映射框架来了,操作大大简化!
重磅发布:Redis 对象映射框架来了,操作大大简化! -
02.21 16:44:36发表了文章
2022-02-21 16:44:36
频频曝出程序员被抓,我们该如何避免面向监狱编程?
频频曝出程序员被抓,我们该如何避免面向监狱编程?
-
02.21 16:42:34发表了文章
2022-02-21 16:42:34
SpringBoot 2.6.0发布:禁止循环依赖,还有哪些实用的更新?
SpringBoot 2.6.0发布:禁止循环依赖,还有哪些实用的更新? -
02.21 16:41:02发表了文章
2022-02-21 16:41:02
项目开发中,真的有必要定义VO,BO,PO,DO,DTO这些吗?
项目开发中,真的有必要定义VO,BO,PO,DO,DTO这些吗?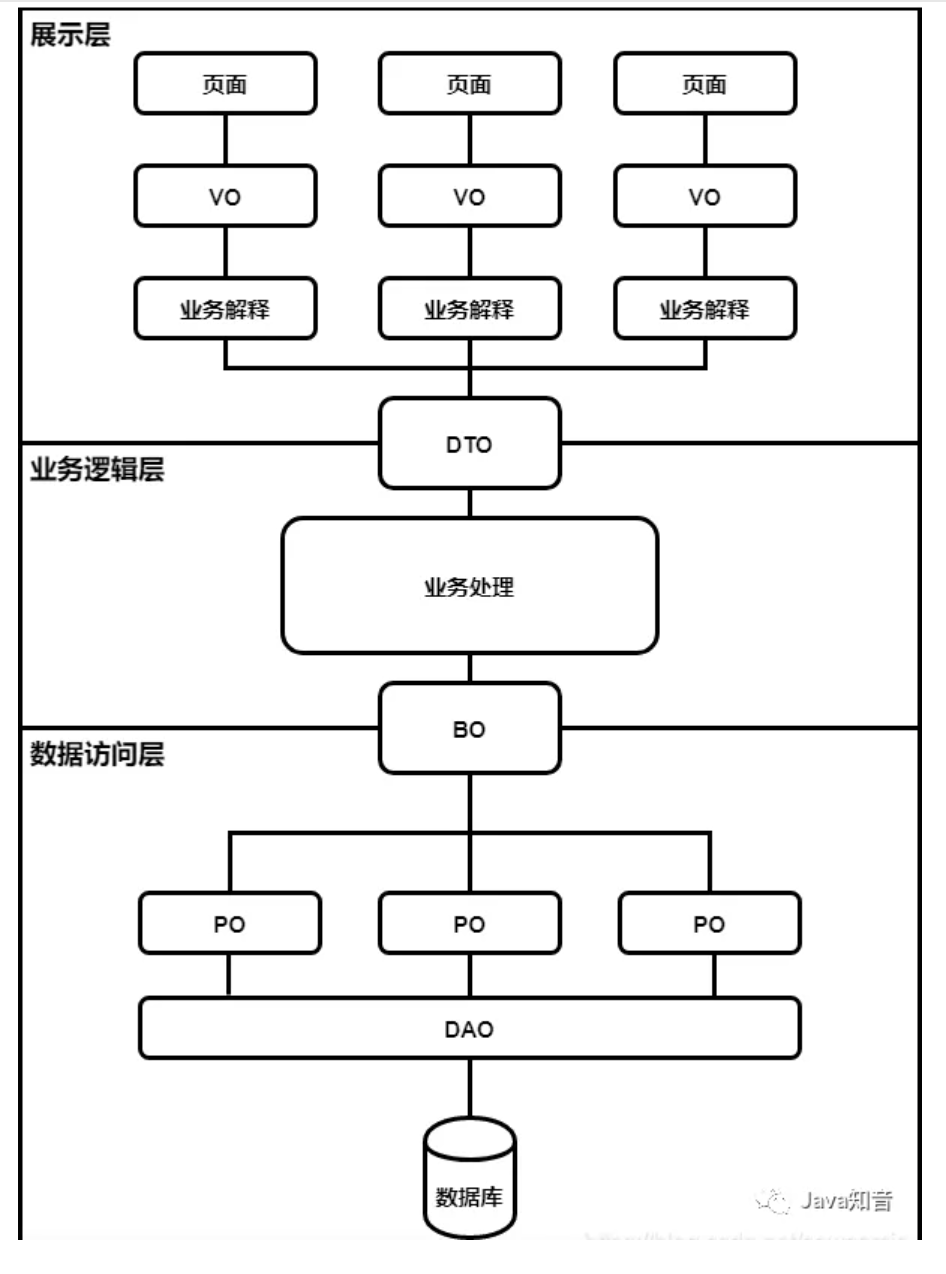
-
02.21 16:38:20发表了文章
2022-02-21 16:38:20
K8S 部署 SpringBoot 项目(一篇够用)
K8S 部署 SpringBoot 项目(一篇够用)
-
02.21 16:34:56发表了文章
2022-02-21 16:34:56
分布式ID(唯一性)的生成方法汇总
分布式ID(唯一性)的生成方法汇总
-
02.21 16:32:19发表了文章
2022-02-21 16:32:19
从实战到原理,线程池的各类使用场景整合(下)
从实战到原理,线程池的各类使用场景整合(下)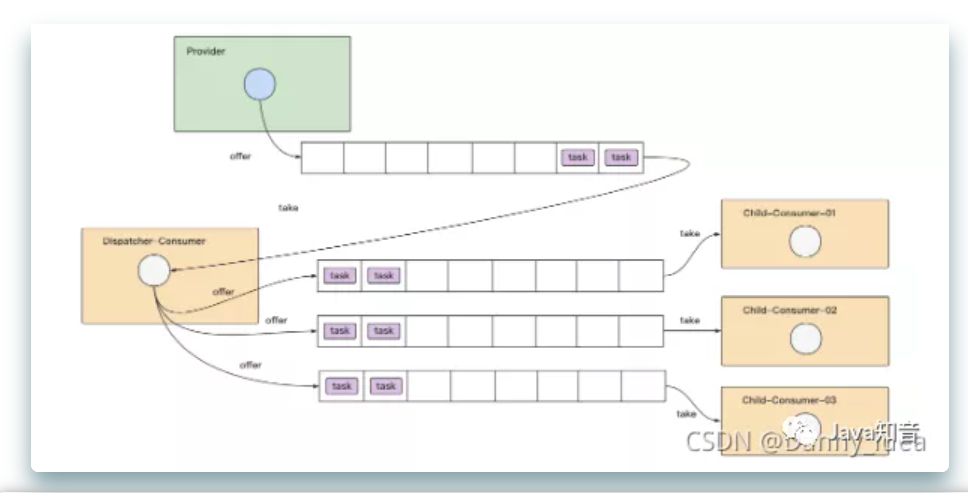
-
02.21 16:30:39发表了文章
2022-02-21 16:30:39
从实战到原理,线程池的各类使用场景整合(中)
从实战到原理,线程池的各类使用场景整合(中)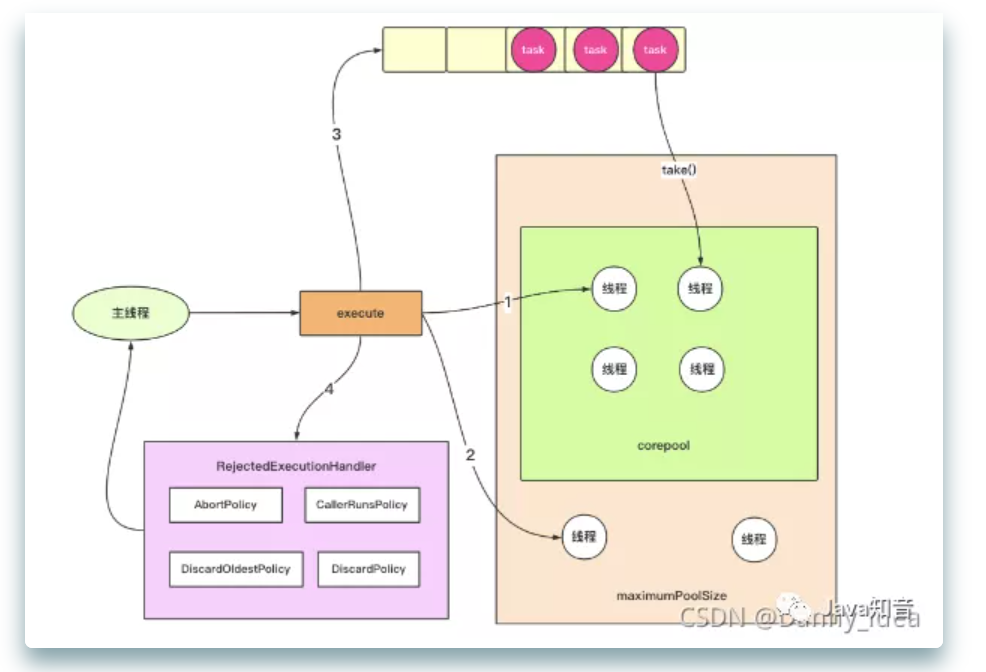
-
02.21 16:29:22发表了文章
2022-02-21 16:29:22
从实战到原理,线程池的各类使用场景整合(上)
从实战到原理,线程池的各类使用场景整合(上)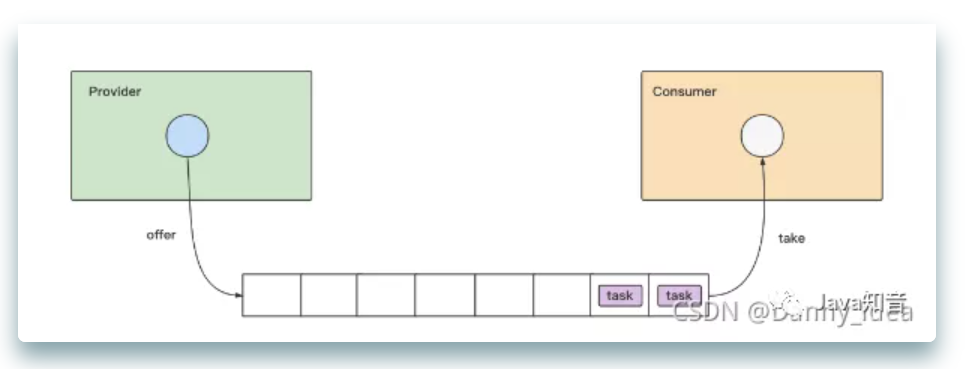
-
02.21 16:26:42发表了文章
2022-02-21 16:26:42
从0到1带你手撸一个请求重试组件,不信你学不会!
从0到1带你手撸一个请求重试组件,不信你学不会!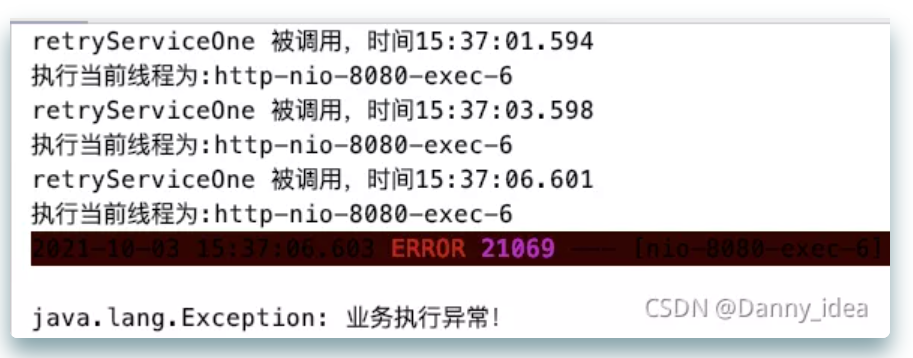
-
02.21 16:23:33发表了文章
2022-02-21 16:23:33
工作中常用到的 Spring 依赖管理技术盘点(下)
工作中常用到的 Spring 依赖管理技术盘点(下)
-
02.21 16:20:55发表了文章
2022-02-21 16:20:55
工作中常用到的 Spring 依赖管理技术盘点(上)
工作中常用到的 Spring 依赖管理技术盘点(上)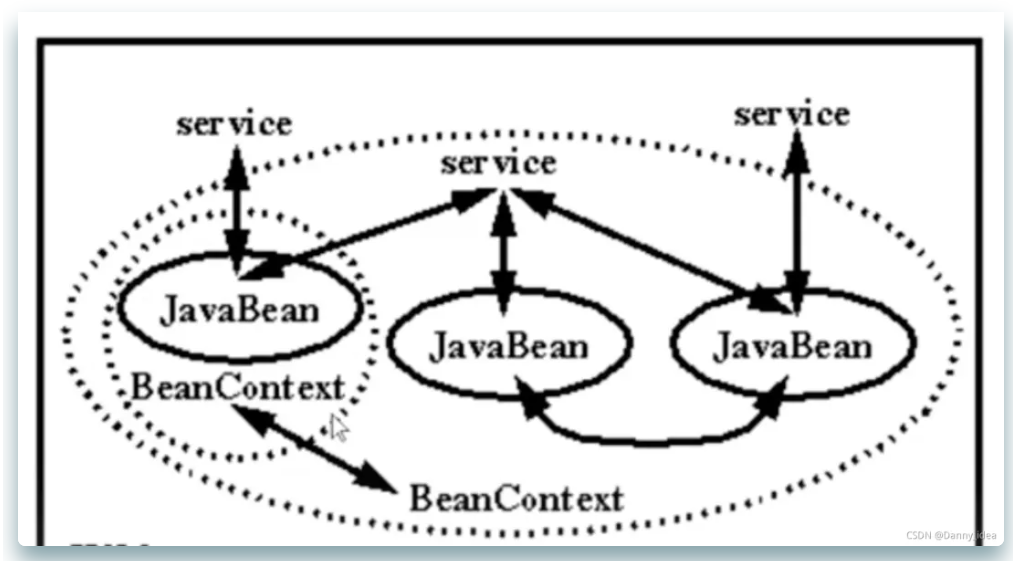
-
02.21 16:16:43发表了文章
2022-02-21 16:16:43
从头捋一遍Java项目中的五大设计原则,就不信你学不会!(下)
从头捋一遍Java项目中的五大设计原则,就不信你学不会!(下) -
02.21 16:15:16发表了文章
2022-02-21 16:15:16
从头捋一遍Java项目中的五大设计原则,就不信你学不会!(中)
从头捋一遍Java项目中的五大设计原则,就不信你学不会!(中)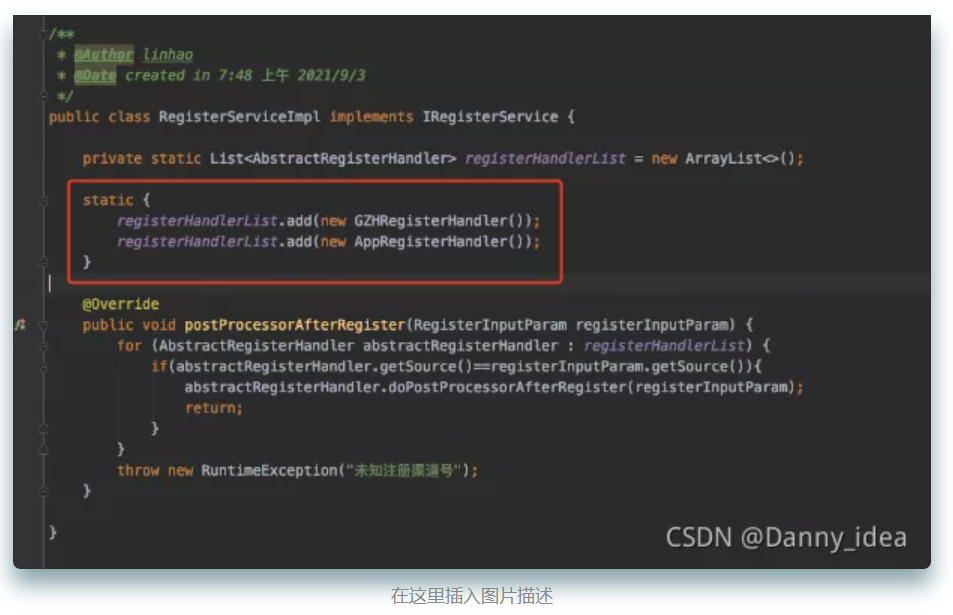
-
02.21 16:13:50发表了文章
2022-02-21 16:13:50
从头捋一遍Java项目中的五大设计原则,就不信你学不会!(上)
从头捋一遍Java项目中的五大设计原则,就不信你学不会!(上) -
02.21 16:10:42发表了文章
2022-02-21 16:10:42
基于CAS实现SSO单点登录
基于CAS实现SSO单点登录
-
02.21 16:06:45发表了文章
2022-02-21 16:06:45
生产环境中,RabbitMQ 持续积压消息不进行ack ,发生什么了?
生产环境中,RabbitMQ 持续积压消息不进行ack ,发生什么了? -
02.21 16:05:07发表了文章
2022-02-21 16:05:07
Java中对象池的本质是什么?(实战分析版)(下)
Java中对象池的本质是什么?(实战分析版)(下) -
02.21 16:03:31发表了文章
2022-02-21 16:03:31
Java中对象池的本质是什么?(实战分析版)(上)
Java中对象池的本质是什么?(实战分析版)(上) -
02.21 16:01:34发表了文章
2022-02-21 16:01:34
教你用纯Java实现一个即时通讯系统(附源码)(下)
教你用纯Java实现一个即时通讯系统(附源码)(下)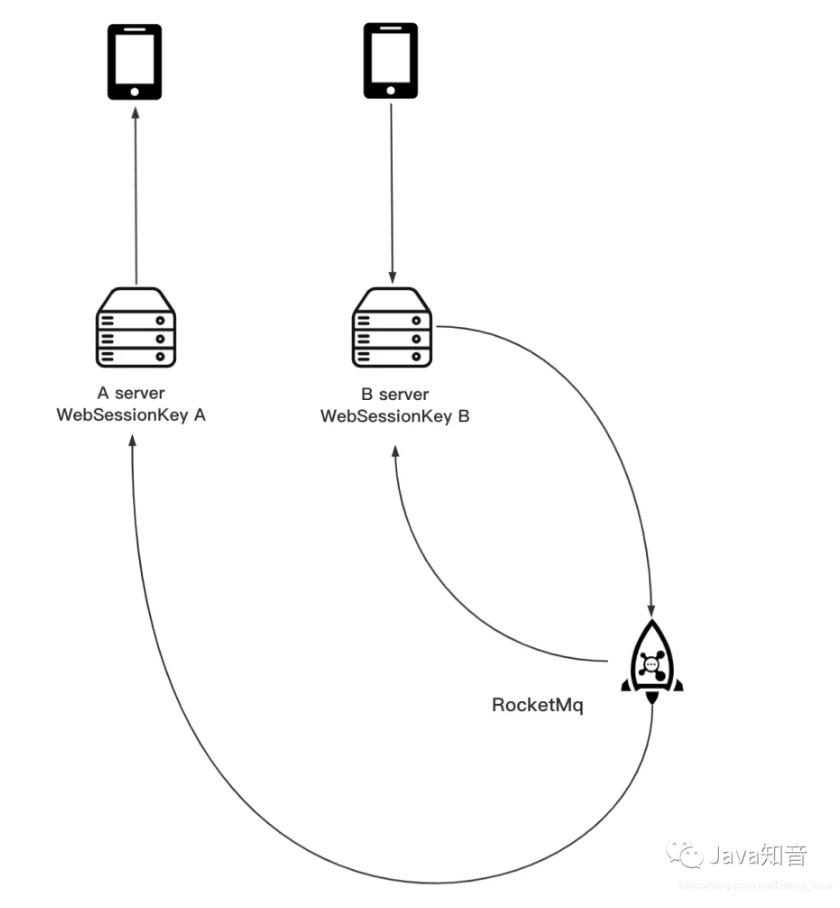
-
02.21 15:59:48发表了文章
2022-02-21 15:59:48
教你用纯Java实现一个即时通讯系统(附源码)(上)
教你用纯Java实现一个即时通讯系统(附源码)(上)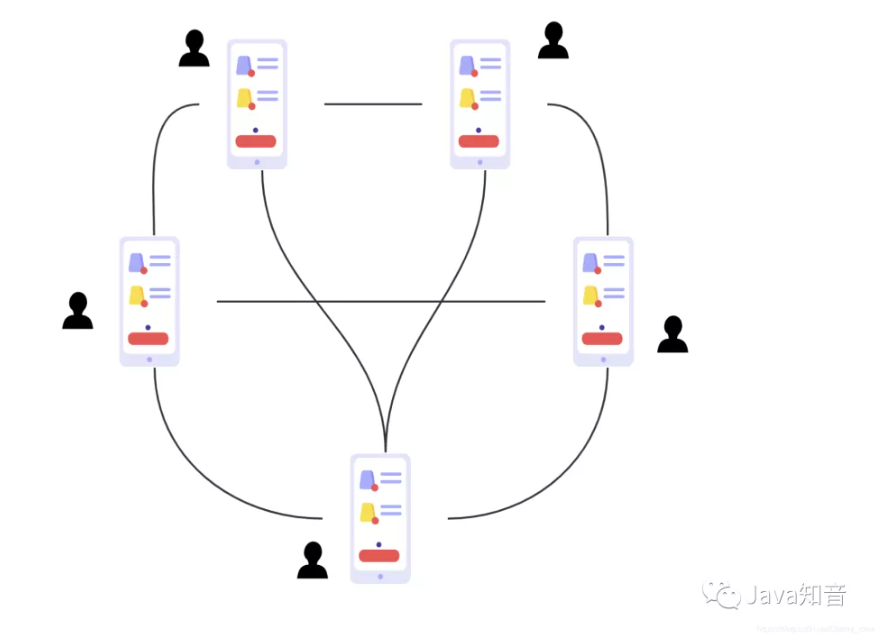
-
02.21 15:56:13发表了文章
2022-02-21 15:56:13
手动实现一个迷你版的AOP(实战增强版)(下)
手动实现一个迷你版的AOP(实战增强版)(下)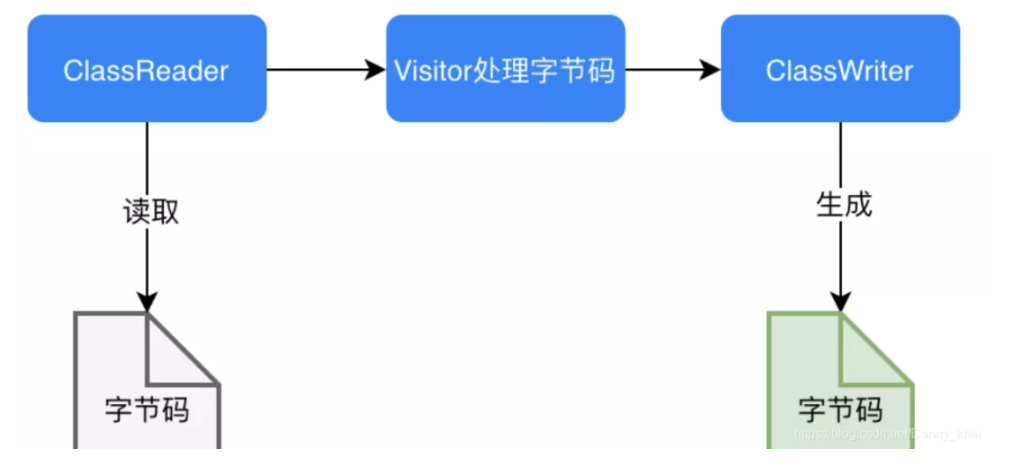
-
02.21 15:55:00发表了文章
2022-02-21 15:55:00
手动实现一个迷你版的AOP(实战增强版)(上)
手动实现一个迷你版的AOP(实战增强版)(上)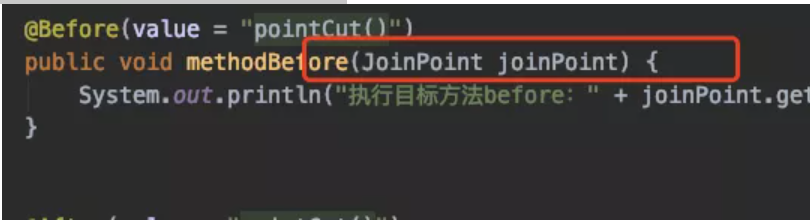
-
02.21 15:50:32发表了文章
2022-02-21 15:50:32
为什么强烈推荐你使用单表查询?(续篇)
为什么强烈推荐你使用单表查询?(续篇)
-
02.21 15:47:56发表了文章
2022-02-21 15:47:56
为什么强烈建议你不要做联表查询?
为什么强烈建议你不要做联表查询?
-
02.21 15:46:30发表了文章
2022-02-21 15:46:30
字符串拼接还在用StringBuilder?快试试Java8中的StringJoiner吧,真香!
字符串拼接还在用StringBuilder?快试试Java8中的StringJoiner吧,真香! -
02.21 15:43:48发表了文章
2022-02-21 15:43:48
引入 Gateway 网关,这些坑一定要学会避开!!!
引入 Gateway 网关,这些坑一定要学会避开!!!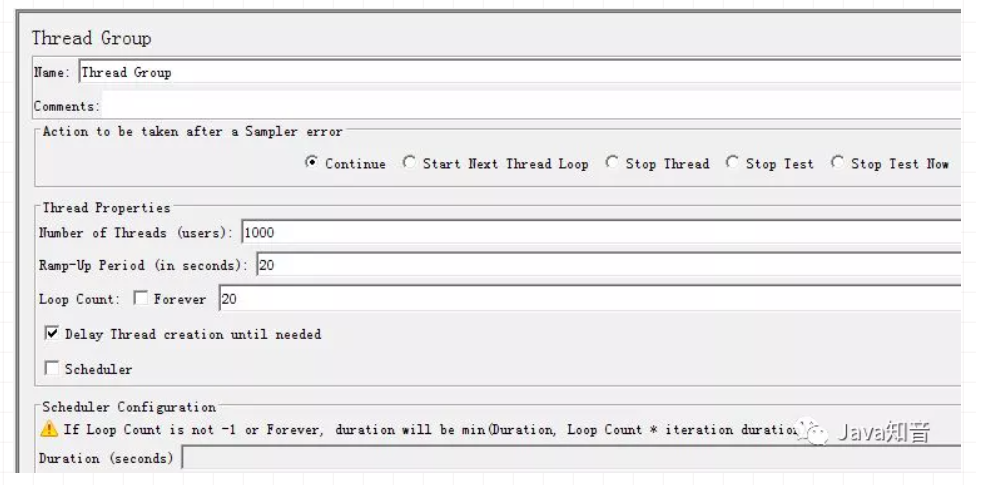
-
02.21 15:36:32发表了文章
2022-02-21 15:36:32
JVM超神之路:年后跳槽需要的JVM知识点,周末给你整理了一份!!!
JVM超神之路:年后跳槽需要的JVM知识点,周末给你整理了一份!!! -
02.21 15:33:35发表了文章
2022-02-21 15:33:35
Gateway网关使用不规范,同事加班泪两行~
Gateway网关使用不规范,同事加班泪两行~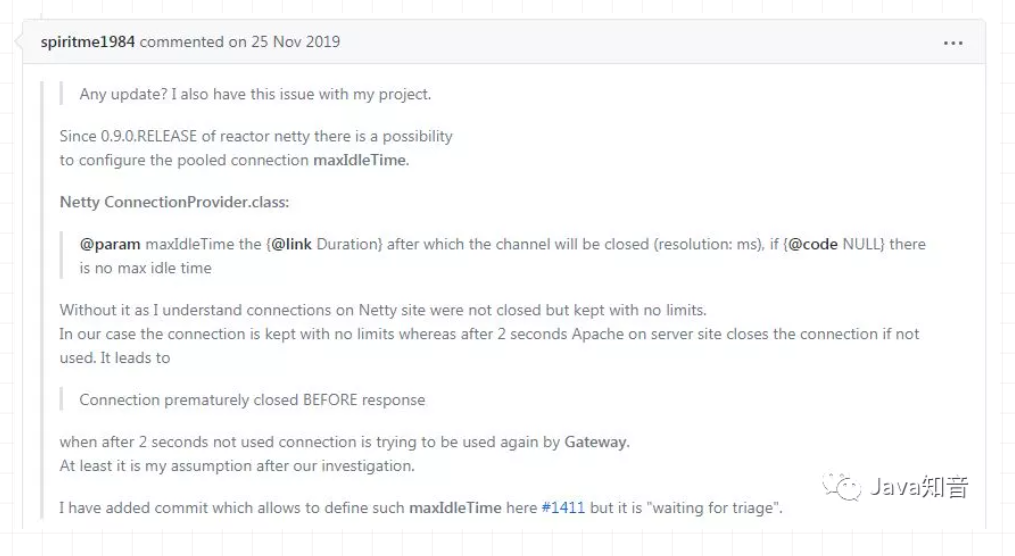
-
02.21 13:38:59发表了文章
2022-02-21 13:38:59
Java8 Stream流式编程,极大解放你的生产力!
Java8 Stream流式编程,极大解放你的生产力! -
02.21 13:37:13发表了文章
2022-02-21 13:37:13
搞定面试官:咱们从头到尾再说一次 Java 垃圾回收
搞定面试官:咱们从头到尾再说一次 Java 垃圾回收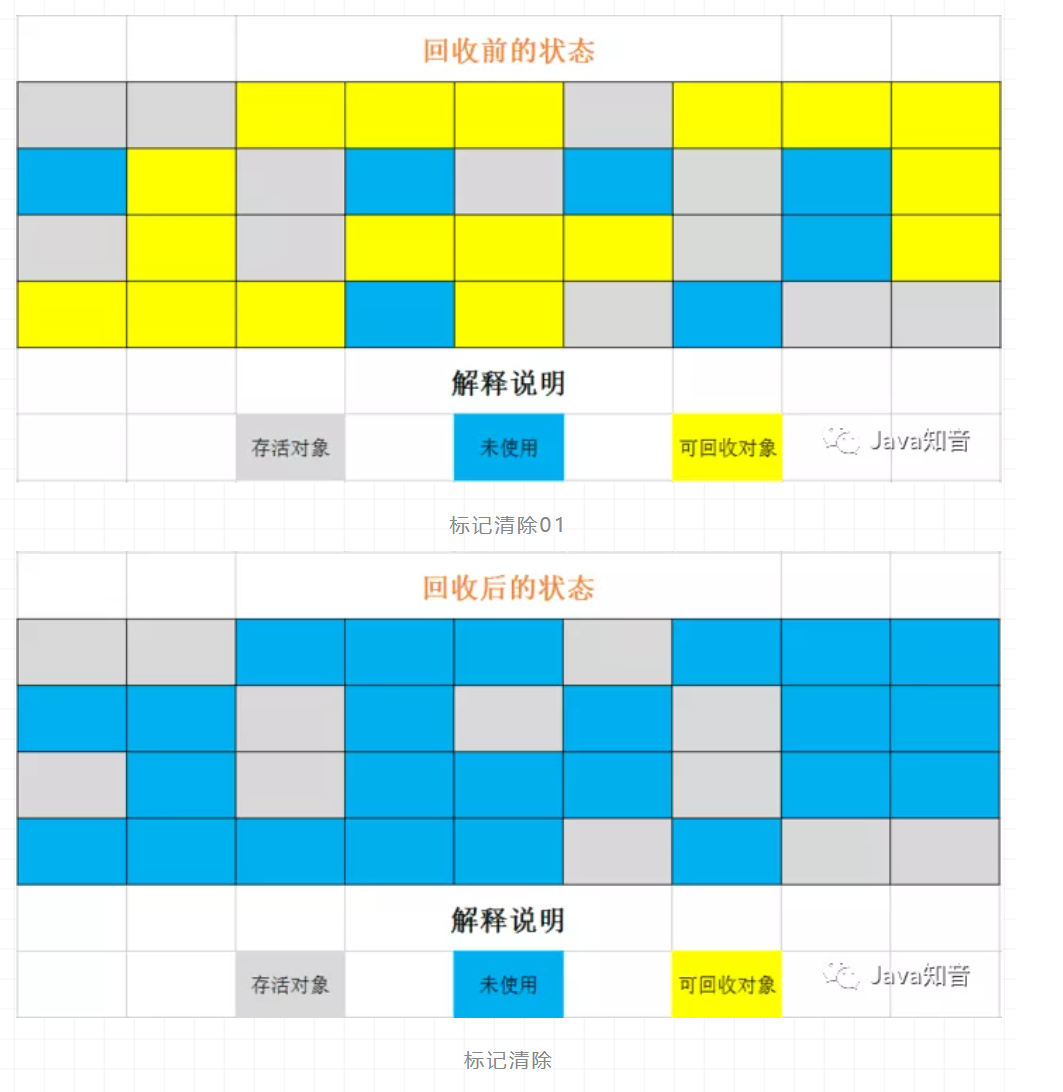
-
02.21 13:32:48发表了文章
2022-02-21 13:32:48
SpringBoot项目,如何优雅的把接口参数中的空白值替换为null值?
SpringBoot项目,如何优雅的把接口参数中的空白值替换为null值?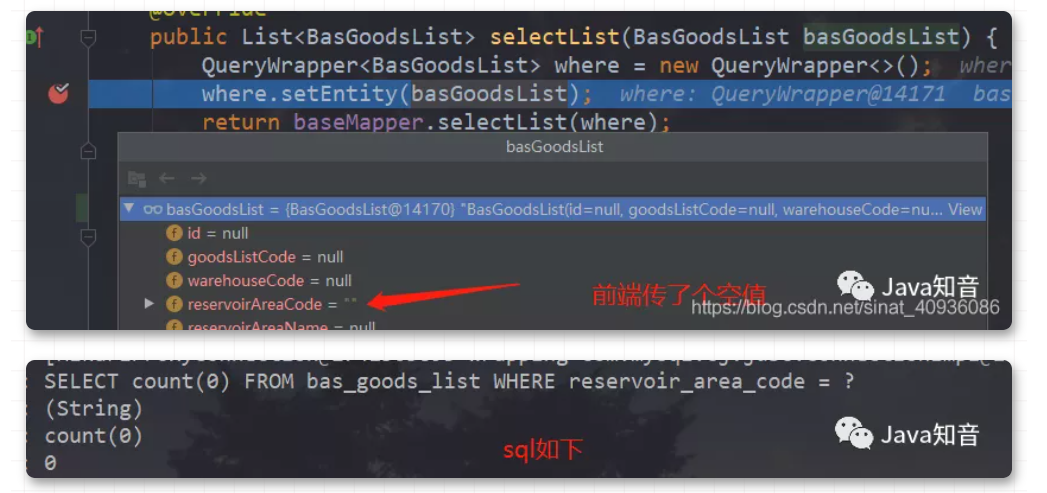
-
发表了文章
2022-04-12
又一款神器:半小时带你轻松上手k8s
-
发表了文章
2022-04-12
基本功:超全面 IO 流教程,小白也能看懂
-
发表了文章
2022-04-11
Spring Aop 常见注解和执行顺序
-
发表了文章
2022-04-11
再见丑陋的 Swagger,这个API神器界面更炫酷,逼格更高,体验更好!
-
发表了文章
2022-04-11
SpringCloud 微服务架构,适合接私活(附源码)
-
发表了文章
2022-04-11
神器 Nginx 的学习手册 ( 建议收藏 )(二)
-
发表了文章
2022-04-11
神器 Nginx 的学习手册 ( 建议收藏 )(一)
-
发表了文章
2022-04-11
系统架构演变:SOA、微服务架构的区别和联系(下)
-
发表了文章
2022-04-11
系统架构演变:SOA、微服务架构的区别和联系(上)
-
发表了文章
2022-04-11
这几行代码,真的骚!
-
发表了文章
2022-02-21
实战干货:基于Redis6.2 部署迷你版本消息队列(下)
-
发表了文章
2022-02-21
实战干货:基于Redis6.0 部署迷你版本消息队列(中)
-
发表了文章
2022-02-21
实战干货:基于Redis6.0 部署迷你版本消息队列(上)
-
发表了文章
2022-02-21
GitLab 配置 OAuth2 实现第三方登录,简直太方便了!
-
发表了文章
2022-02-21
Mybatis 一连串提问,被面试官吊打了!
-
发表了文章
2022-02-21
中招了,重写TreeMap的比较器引发的问题...(下)
-
发表了文章
2022-02-21
中招了,重写TreeMap的比较器引发的问题...(上)
-
发表了文章
2022-02-21
通俗讲解分布式锁:场景和使用方法
-
发表了文章
2022-02-21
重磅发布:Redis 对象映射框架来了,操作大大简化!
-
发表了文章
2022-02-21
频频曝出程序员被抓,我们该如何避免面向监狱编程?
滑动查看更多
暂无更多信息
暂无更多信息



