
云数据仓库ADBsubmit job根本不执行,怎么解决?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
当云数据仓库AnalyticDB(ADB)中的SUBMIT JOB任务未执行时,可能是由于多种原因导致的。以下是详细的排查步骤和解决方案:
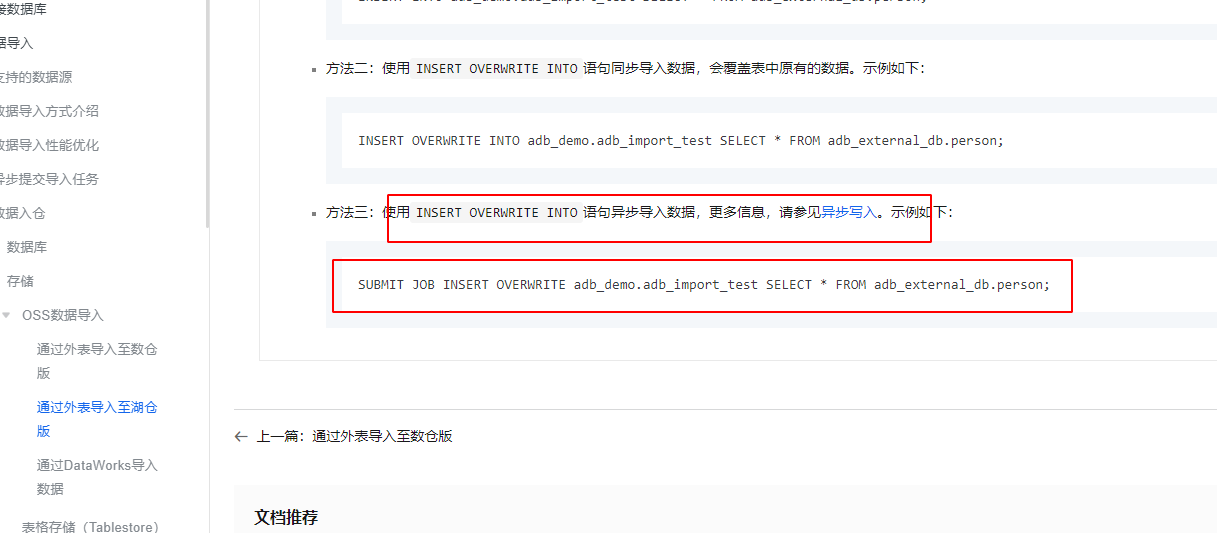
确保您提交任务的SQL语句符合规范。例如,使用SUBMIT JOB提交异步任务时,需正确指定Hint参数和目标表。以下是一个标准的异步任务提交示例:
/*+ elastic_load=true, elastic_load_configs=[adb.load.resource.group.name=resource_group] */
SUBMIT JOB INSERT OVERWRITE INTO adb_demo.adb_import_test
SELECT * FROM adb_demo.oss_import_test_external_table;
重要提示: - 确保elastic_load=true已启用。 - adb.load.resource.group.name必须指定为有效的资源组名称。
如果语法有误,任务可能无法提交成功。
SUBMIT JOB依赖于指定的资源组来执行任务。如果资源组配置错误或资源不足,可能导致任务无法启动。请按照以下步骤检查资源组: 1. 确认资源组名称是否正确。
SELECT * FROM information_schema.kepler_meta_resource_groups;
集群Shard个数+1 ACU。可以通过以下命令查询集群Shard数量:
SELECT count(1) FROM information_schema.kepler_meta_shards;
解决方法: - 如果资源不足,请增加资源组的ACU配额。 - 调整adb.load.job.max.acu参数以限制单个任务的最大资源使用量。
如果客户端与ADB服务端之间的网络连接不稳定,可能导致任务提交失败或任务中断。建议采取以下措施: - 确保客户端与ADB服务端之间的网络延迟较低且稳定。 - 如果数据量较大,推荐使用异步任务提交方式(SUBMIT JOB),并监控任务状态。
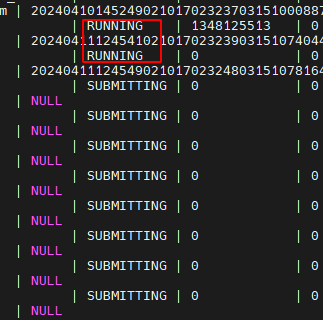
提交任务后,返回的job_id可用于查询任务状态或终止任务。如果任务未执行,可以通过以下命令检查任务状态:
SHOW JOBS WHERE job_id = 'your_job_id';
常见问题及解决方法: - 任务状态为PENDING:表示任务正在等待资源调度。可以尝试调整资源组优先级或增加资源配额。 - 任务状态为FAILED:表示任务执行失败。可以通过以下命令查看详细日志:
SHOW JOB LOG WHERE job_id = 'your_job_id';
如果集群正在进行统计信息收集任务,可能会导致CPU负载过高,从而影响其他任务的执行。建议采取以下措施: 1. 调整统计信息收集任务的运维时间到业务低峰期:
SET adb_config O_CBO_MAINTENANCE_WINDOW_DURATION = [04:00-05:00];
SET adb_config CSTORE_IO_LIMIT_SYSTEM_QUERY_BPS = 52428800;
SET adb_config O_CBO_AUTONOMOUS_STATS_ACCOUNT = [user_name];
如果任务涉及Spark作业(如弹性导入),需要确保Spark资源配置正确。以下是一些关键参数的说明: - spark.driver.resourceSpec:指定Spark Driver的资源规格,默认值为small。 - spark.executor.resourceSpec:指定Spark Executor的资源规格,默认值为large。 - spark.adb.executorDiskSize:指定Executor的磁盘容量,默认值为10 GiB。
解决方法: - 根据任务需求调整资源规格。例如,对于大规模数据导入任务,可以将spark.executor.resourceSpec设置为xlarge。
如果以上方法均无法解决问题,建议联系阿里云技术支持团队,提供以下信息以便快速定位问题: - 任务的job_id。 - 提交任务的完整SQL语句。 - 集群版本号和相关配置信息。
通过以上步骤,您可以逐步排查并解决SUBMIT JOB任务未执行的问题。
阿里云自主研发的云原生数据仓库,具有高并发读写、低峰谷读写、弹性扩展、安全可靠等特性,可支持PB级别数据存储,可广泛应用于BI、机器学习、实时分析、数据挖掘等场景。包含AnalyticDB MySQL版、AnalyticDB PostgreSQL 版。

