
ADB执行这个查询慢查询表为啥报错呢?
ADB执行这个查询慢查询表为啥报错呢?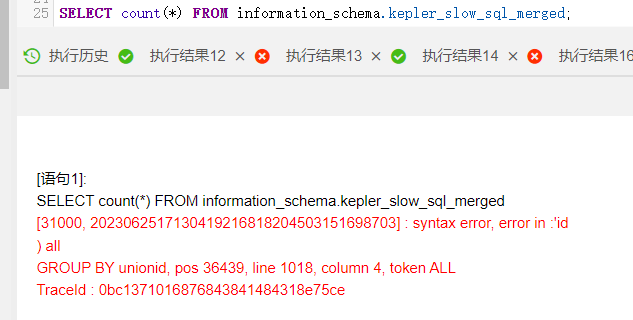
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在云原生数据仓库AnalyticDB MySQL版(ADB)中,执行查询时出现慢查询并报错可能由多种原因引起。以下是根据知识库资料总结的详细分析和解决方法:
1. 表结构设计问题
如果表使用的分布键倾斜严重,可能导致导入任务或查询任务只有部分分片在执行,从而引发长尾现象,导致查询变慢甚至报错。
建议: 根据表结构设计优化分布键,避免数据倾斜。
2. 数据量增加或查询条件变化
- 数据量增加:某些表的数据量增加会导致处理的数据量增大,进而使查询变慢。
- 查询条件变化:例如扫描的二级分区数增多或查询范围扩大,也会导致查询性能下降。
建议: 检查查询条件是否合理,尽量减少扫描的分区数或优化查询范围。
3. 系统压力增加
系统压力增加可能是由于写入量增加占用了较多系统资源,或者存在“Bad SQL”占用了大量资源,影响了查询性能。
建议: - 监控系统负载情况,排查是否存在高耗资源的SQL。 - 使用SQL诊断功能查看不同SQL Pattern的资源消耗(如执行次数、查询耗时、扫描量等),定位问题SQL。
4. ANALYZE命令低优先级执行
系统在运维时间自动发起的ANALYZE命令会以低优先级执行(IO限流+CPU低优先级),因此执行缓慢,可能会被诊断为慢查询。
说明: 如果CPU负载不高,或者CPU负载高与运维时间没有明显联系,可以忽略该问题。如果CPU负载持续很高,请参考后续解决方案。
5. 表结构中的二级分区问题
如果表结构定义了较多二级分区,但查询条件中没有对二级分区进行过滤,会导致查询扫描多个二级分区数据。特别是混合表或冷表,扫描冷二级分区数据会比热二级分区数据更慢。
建议: - 检查表结构,确保查询条件包含二级分区的过滤条件。 - 使用ADB的自助慢查询诊断功能,进一步分析问题。
6. 新增字段后查询报错
在新增字段后,查询提示找不到新添加的列,可能是因为: - 表正在上线,但上线失败。 - CN副本在重启。
解决方案: - 对于普通表,新增字段后需执行optimize操作,待其成功后再查询。 - 如果是未上线或CN副本重启导致的报错,请检查上线情况或重启状态。
7. 查询内存、CPU或磁盘I/O消耗过大
内存消耗过大
- GROUP BY操作:GROUP BY字段的唯一值较多时,会占用较多内存。
- JOIN操作:使用Hash方式Join时,较大的表会被缓存到内存中。
- SORT操作:排序数据量较大时,会占用较多内存。
- 窗口函数操作:执行窗口函数时,数据量较大也会占用较多内存。
建议: 使用SQL诊断功能查看峰值内存信息,定位消耗内存较多的Stage或算子,并优化相关操作。
CPU消耗过大
- 过滤条件未下推:无法有效利用索引,增加CPU资源消耗。
- Join条件中带有过滤操作:先执行Join后过滤的方式无法使用索引。
- 未指定Join条件:执行笛卡尔积运算,产生大量数据。
建议: 检查SQL语句,确保过滤条件能够下推,并明确指定Join条件。
磁盘I/O消耗过大
- 过滤条件筛选率低:索引使用效率不高,需要读取的索引量较大。
- 过滤条件未下推:导致全表扫描。
- 扫描分区过多:分区越多,扫描的数据量越大。
建议: 优化过滤条件,减少扫描的分区数。
8. SQL表达式过于复杂
如果SQL表达式太复杂,编译出来的代码可能超过JDK限制,导致查询报错。例如,Quick BI即席分析生成的SQL超出ADB的filter expression size限制(默认3000)。
解决方案: 手工优化SQL,调整字段查询顺序,减少表达式的复杂度。
9. 查询超时或连接问题
MySQL Client在超时后会发送KILL QUERY XXX,但AnalyticDB MySQL不支持该命令,可能导致报错Unknown connection id。
解决方案: - 全局设置超时时间:SET ADB_CONFIG QUERY_TIMEOUT=1000; - 单个查询设置超时时间:/*+ QUERY_TIMEOUT=1000 */ select count(*) from t;
10. 其他常见问题
- 表不存在或已存在:检查是否有DDL操作冲突,或ADB是否在备份快照阶段。
- 字符集问题:创建别名时使用中文字符集可能导致查询报错,建议使用字母或英文。
- 查询控件过长:where子句过长可能导致数据库编译失败,建议提工单咨询技术支持。
总结建议
针对ADB查询慢或报错的问题,建议按照以下步骤排查: 1. 检查表结构设计,优化分布键和分区策略。 2. 使用SQL诊断功能,定位资源消耗较大的查询。 3. 优化SQL语句,减少复杂度和资源消耗。 4. 调整系统配置,如超时时间和资源管理参数。
如果问题仍未解决,建议联系AnalyticDB MySQL版技术支持团队获取进一步帮助。您可以复制页面截图提供更多信息,我可以进一步帮您分析问题原因。

阿里云自主研发的云原生数据仓库,具有高并发读写、低峰谷读写、弹性扩展、安全可靠等特性,可支持PB级别数据存储,可广泛应用于BI、机器学习、实时分析、数据挖掘等场景。包含AnalyticDB MySQL版、AnalyticDB PostgreSQL 版。