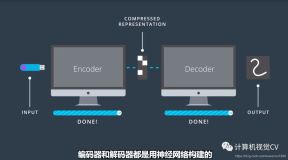
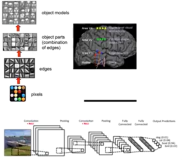
我们以Unet网络来进入我们今天将要分享的主题,请看下图:

我们知道,Unet网络结构大致可以分为三大部分:
- 编码器(Encoder):由四个子模块构成,每个子模块包含两个卷积层,并且在每个子模块之后均有一个通过max_pooling实现的下采样层;通过观察网络层级结构我们可以知道,Encoder共下采样4次,一共下采样16倍;
- 解码器(Decoder):同样由四个子模块组成,与Encoder对应,Decoder共上采样4次,从而可以将Encoder得到的高级语义特征图恢复到原图片的分辨率;
- skip connection:将上采样结果与编码器中具有相同分辨率的子模块的输出进行连接,作为解码器中下一个子模块的输入。
简单总结一下,Unet不像FCN那样直接上采样得到想要的特征图,而是通过一次又一次小规模的上采样得到,并且在上采样的过程中,与下采样过程中的特征图进行融合拼接。
OK,对Unet的大致过程有了了解之后,我们将重点放在解码器(Decoder)部分,即通过上采样将编码器所输出的图像大小恢复至与原图像大小一致。一般来讲,up_sampling上采样常用的方式有两种:
- FCN中介绍的反卷积
- 图像插值算法
接下来,我们来对这两种方法进行介绍。
一、 FCN中的反卷积
首先我们明确一点,本文中所提及的反卷积(Deconvolution)与其他相关文章中的转置卷积(Transposed Convolution)是一个意思,至于其原因,我会在讲解完反卷积的详细过程之后做以解释,请读者不用着急,我们一步一步来。
首先,我们来看一下基本的卷积操作过程,请看图示:

总结一下,我们所使用的输入矩阵大小为4 4,卷积核大小3 3,根据卷积过程中输入输出尺寸大小关系的计算公式(N = (W-F+2P)/S +1,其中W表示输入矩阵大小,F表示卷积核大小,P表示填充大小,S表示步长)可知,所得输出矩阵大小为2*2。
抛开具体的数学计算过程不谈,我们发现上述的卷积操作会使输入值和输出值在位置上有连接关系,简单来说,输入矩阵左上方的值将会影响到输出矩阵的左上方的值;回到上述的例子中,3 * 3的卷积核是用来连接输入矩阵中的9个值,并且通过矩阵运算将其转化为输出矩阵中的一个值。可见,一个卷积操作是一个多对一(本例子中是9 --> 1)的映射关系。
现在,我们想要反过来进行操作,与上述卷积过程中所采用的例子大致相同,只不过当前的输入矩阵为2 * 2(此处所使用的输入矩阵为上述卷积过程所得的输出矩阵),我们想要将该输入矩阵中的一个值映射到输出矩阵中的9个值,这将是一个一对多的映射关系,我们来看具体操作:
首先,我们将卷积核重新排列到我们可以用普通的矩阵乘法进行矩阵卷积操作,请看图示:

为了将卷积操作表示为卷积矩阵和输入矩阵的向量乘法,我们将输入矩阵4 4摊平为一个列向量,形状为16 1,如下图所示:
我们将这个4 16的卷积矩阵和16 1的输入列向量进行矩阵乘法,这样我们就得到了输出列向量。
这个输出的4 1的矩阵可以重新塑形为一个2 2 的矩阵,而这个矩阵正是和我们一开始通过传统的卷积操作得到的一模一样。
所以当输入矩阵的大小为2 2时,我们将原本的4 16的卷积矩阵转置一下,即所得卷积矩阵大小为16 4,所以此时的矩阵运算即为:16 4的卷积矩阵 与 4 1的输入矩阵进行运算,所得输出矩阵即为16 1的尺寸大小,我们可以将其重新塑形为一个4 * 4的矩阵。
细心的小伙伴一定发现了,反卷积操作之后的输出矩阵的参数为什么与卷积操作的输入矩阵参数不一样呢?其实,这就是我要提醒各位小伙伴的一点,反卷积并非常规卷积的逆过程。如果对常规卷积的输出进行反卷积,只能得到与常规卷积输入矩阵大小一样的矩阵,但里面的元素却不一定相同。
好的,关于反卷积操作的具体步骤,我们就介绍到这里,接下来我们来回答本小节最开始提出的那个问题?为什么说反卷积操作和转置卷积在某种程度上可以认为是一样的呢?理由如下:
- 反卷积是从宏观角度上命名的:我们来复习一下卷积的操作过程:4 4的输入矩阵,经过3 3的卷积核,两者进行运算可得到2 2的输出矩阵;再来看一下反卷积的操作过程:2 2的输入矩阵,经过重新排列之后的卷积核矩阵的转置(16 4),两者进行运算可得到4 4的输出矩阵;即卷积操作过程是从4 4到2 2的变化,反卷积过程是从2 2到4 4的变化;
- 转置卷积是从具体实现方法的角度命名的:卷积操作中将3 3的卷积核矩阵重新塑形为4 16的卷积核矩阵;反卷积操作中将4 16的卷积核矩阵转置为16 4的反卷积核矩阵。
二、图像插值算法
在图像几何变换时(放大、缩小等),无法给有些像素点直接赋值,例如,将图像放大两倍,必然会多出一些无法被直接映射的像素点,对于这些像素点,我们可以通过插值来决定它们的值,请看图示:

首先,我们来以一张图帮助小伙伴们梳理一下知识结构:

- 线性图像插值算法:该类图像插值方法在图像插值过程中采用同一种插值内核,不用考虑待插像素点所处的位置,但是这种做法会使图像中的边缘变得模糊不清,达不到高清图像的视觉效果。
- 非线性图像插值算法:隐式方法中包括边缘导向插值(New Edge Directive Interpolation)NEDI、最小均方误差估计插值(Linear minimum mean square-error estimation)LMMSE、软判决自适应插值(Soft-decision Adaptive Interpolation)SAI、边缘对比度引导的图像插值(Contrast-guideed image interpolation)CGI。
在本小节中,我们将着重介绍线性插值的三种方法,首先我们通过一段代码来读取一张小猫的图片,请看代码:
import matplotlib.pyplot as plt
img_cat_src = "svg_pic/cat.jpg"
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False#用来正常显示负号
img_cat = plt.imread(img_cat_src)
plt.title("小猫原图(尺寸大小:533*300)")
plt.imshow(img_cat)
plt.show()我们来看一下效果图:
接下来我们来看三种线性插值的方法:
- 最近邻插值(Nearest neighbor interpolation)
请看图示:

在一维空间中,最近点插值就相当于四舍五入取整。在二维图像中,像素点的坐标都是整数,该方法就是选取离目标点最近的点。具体来说,将目标图像中的点对应到原图像中后,找到最相邻的整数坐标点的像素值,作为该点的像素值输出。用一句“近朱者赤近墨者黑”来形容该插值算法再合适不过了。
请看代码演示:
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
img_cat_src = "svg_pic/cat.jpg"
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False#用来正常显示负号
img_cat = plt.imread(img_cat_src)
# 最近邻法
img_resize_nearest = tf.image.resize(img_cat,size=(600,600),method="nearest")
img_resize_nearest_intType = np.asarray(img_resize_nearest,dtype="uint8")
plt.title("最邻近插值")
plt.imshow(img_resize_nearest_intType)
plt.show()我们来看一下效果图:
对于最邻近插值算法,其放大后的图像有很严重的马赛克,会出现明显的块状效应;缩小后的图像有很严重的失真。这是一种最基本、最简单的图像缩放方式。变化后的每个像素点的像素值,只由原图像中的一个像素点确定。例如,点(0,0.75)的像素只由点(0,1)确定,这样的效果显然不好。点(0,0.75)不止和点(0,1)有关,也和点(0,0)有关,只是点(0,1)的影响更大。如果可以用附近的几个像素点按权重分配,共同确定目标图像某点的像素,效果会更好,接下来请看双线性插值算法。
- 双线性插值(Bilinear interpolation)
要了解双线性插值算法,我们先来看单线性插值,请看下图:

我们清楚的知道,最邻近插值算法最大的缺点就是每个像素点的像素值只由原图中的一个像素点确定,我们回到上述图中,我们知道像素点x的值应该和原像素x1、x2均有关系,只不过权重值不同罢了。
上述图中的公式很简单,相信小伙伴们都能看懂,这里不做赘述。
了解了单线性插值,对于我们理解双线性插值有很大帮助。实际上,双线性插值是单线性插值在二维时的推广,本质上是在两个方向上做了三次线性插值,请看图示:

这里我们首先给出目标矩阵到源矩阵的坐标映射公式:

了解了具体的数学计算过程之后,我们来看代码:
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
img_cat_src = "svg_pic/cat.jpg"
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False#用来正常显示负号
img_cat = plt.imread(img_cat_src)
# 双线性插值
img_resize_bilinear = tf.image.resize(img_cat,size=(600,600),method="bilinear")
img_resize_bilinear_intType = np.asarray(img_resize_bilinear,dtype="uint8")
plt.title("双线性插值")
plt.imshow(img_resize_bilinear_intType)
plt.show()接下来,我们来看效果图:
- 双三次插值(Bicubic interpolation)
关于双三次插值的具体原理,我们不做赘述,这里推荐一篇我在知乎上找到优质文图像插值算法(线性插值与非线性插值),我们来直接看代码:
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
img_cat_src = "svg_pic/cat.jpg"
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False#用来正常显示负号
img_cat = plt.imread(img_cat_src)
# 双三次插值
img_resize_bicubic = tf.image.resize(img_cat,size=(600,600),method="bicubic")
img_resize_bicubic_intType = np.asarray(img_resize_bicubic,dtype="uint8")
plt.title("双三次插值")
plt.imshow(img_resize_bicubic_intType)
plt.show()请看效果图:
- 关于代码的一些说明:
我们使用TensorFlow 2.0版本中的tf.image.resize方法,请看下图:

我们重点关注其中的method参数,请看method可以接收的具体参数,如下所示:

最后,我们来对上述所介绍的三种线性插值算法做一些简单的总结:
- 最邻近法:计算速度最快,但是效果最差;
- 双线性插值:该方法使用原图像中4 (2 * 2)个点计算新图像中1个点,效果略逊于双三次插值,速度比双三次插值快,属于一种平衡美,在很多框架中属于默认算法;
- 双三次插值:双三次插值是用原图像中16 (4 * 4)个点计算新图像中1个点,效果比较好,但是计算代价过大。
以上,就是我们本次推文分享的全部内容,获取更多咨询或交流问题,请微信搜索 hahaCoder 公众号,下次见。