最近有很多同学微信问我说:峰哥,能不能帮我看看简历里的项目可以写哪些亮点或难点?
一般写难点可以从业务、架构、技术框架,对于大多数人来说写技术框架的难点比较好切入。
拿一个大数据项目来说,你用了很多框架,其中有Hadoop Spark Kafka Zookeeper等,刚好你对Spark比较熟悉,这时你就可以在Spark上做文章去包装优化你的项目。
比如常见Spark技术难点有:Spark处理小文件问题、OOM、内存资源分配、数据倾斜等,后几者可以统一归纳为性能调优。
Spark性能调优细分为:资源分配、JVM调优、shuffle调优、算子调优、数据倾斜等。
网上关于性能调优的资料非常多,但更多的是停留在理论层面,毕竟你是写在简历项目上,所以得落实到具体的项目场景才可以。所以你需要先理解理论,然后反推回自己的项目,看是否能进行落地。
你总不能在简历上写了个技术难点 --- 解决了数据倾斜问题。但当面试官问你项目里哪里出现了数据倾斜、为什么出现数据倾斜、如何解决?
你要是生搬硬套像回答Java的HashMap一样搞一套八股文出来,基本是凉了。
所以光会说不牛逼,能结合项目说才是真牛逼!

之前我的公众号发了很多Spark性能调优的文章,感兴趣的可以自行搜索查阅。

文章很多,但基本都是偏理论层面。刚好极客时间上新了一门《Spark性能调优实战》,里面不止有理论,也有实战篇,更重要的是作者是大厂的技术负责人,内容质量肯定没话说。
作者是吴磊,现任 Comcast Freewheel 机器学习团队负责人,主要负责计算广告业务中机器学习应用的实践、落地与推广。之前也任职于 IBM、联想研究院、新浪微博,可以说具备丰富的数据库、数据仓库、大数据开发与调优经验了。
早之前听说过他,研究 Spark 是下了功夫的,而且做事儿有股“较真儿”的风格,看课程目录就知道,是个严谨、认真的人,跟着这样有实践、有理论,懂实现细节的大佬学习,错不了。
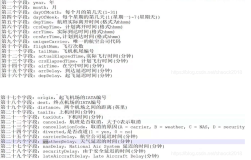
课程的完整目录在这,大家可以看看。

这门课不仅深入浅出的讲了 Spark 核心原理,还全面解析 Spark SQL 性能调优,总结了一份应用开发、配置项设置实操指南,真心实用。
最吸引我的是实操,专栏以「北京市汽油车摇号」数据为例,手把手带你实现一个分布式应用。一句话总结,就是能让你一站式加速 Spark 作业执行性能,是不是很牛。


![Spark集群搭建记录 | 云计算[CentOS8] | Scala Maven项目访问Spark(local模式)实现单词计数(下)](https://ucc.alicdn.com/pic/developer-ecology/727799447e3d4bcf9a7390f4d6174fe0.png?x-oss-process=image/resize,h_160,m_lfit)
![Spark集群搭建记录 | 云计算[CentOS7] | Scala Maven项目访问Spark(local模式)实现单词计数(上)](https://ucc.alicdn.com/pic/developer-ecology/2709fe8f00b74df4a505e574de531d20.png?x-oss-process=image/resize,h_160,m_lfit)