作者 | 言枫
来源 | 阿里技术公众号
预习时关注重点,上课时由易到难,复习时举一反三,能否让机器也按照“预习-上课-复习”的学习范式进行学习呢?
达摩院对话智能(Conversational AI)团队对这个问题进行了研究探索,先将其用在了人机对话领域,在国际知名多轮对话数据集MultiWoz上取得了最好结果。
目前对话系统的各类研究工作,大多还是集中在模型结构的创新上,并按照传统的mini-batch方式进行有监督训练。然而,笔者所在团队经过最新研究发现,这种传统训练方式并不是对话系统的最优训练模式。受到人类在学习新知识时的学习范式的启发,我们提出了“预习-上课-复习”的三阶段训练范式来提升对话系统的性能,该范式能够像人一样预习时关注重点,上课时由易到难,复习时举一反三。具体来说,在预习阶段时,人一般会先了解重点概念、章节结构等信息,因此我们对应地设计了带有结构偏置的预训练目标,让模型学会对话数据中的槽值关联信息;在上课阶段时,人会从简单内容开始学习再逐步进阶到困难部分,因此我们使用了课程学习[1]的方法来训练对话模型;而在复习阶段时,人们通常是温故知新举一反三,因此我们专门设计了基于对话本体的数据增强方法,针对易错样例对模型进行加强训练。通过这样的优化框架,我们最终在多轮对话数据集MultiWOZ2.1和 WOZ2.0上都取得了目前最好结果,相关工作被ACL21以4-4-4高分接收。
一 人类学习范式与机器学习范式
在教育学中,针对人类学习的模式,不少学者提出“预习->上课->复习”的三阶段过程,是最为高效的学习范式之一[3]。预习时,由于没有老师进行指导,因此学生会利用已学知识和技能,通过观察章节标题、浏览段落文字、准备课上问题等方式进行自主地学习,大致了解课堂内容;进入到正式上课阶段时,学生会根据老师安排好的课程从易到难进行学习,这种由浅入深的教学是人类数百年教育发展总结出的最佳方式,能够让学生的知识接受效率最大化;在上完课后,学生应当及时地回顾所学的课程内容,温故知新,通过自我反思总结,找出仍旧没有掌握的知识点,并准备好和老师进一步沟通解答。
在人工智能的主要方向自然语言处理(Natural Language Processing,NLP)领域中,目前大家普遍采用的是“pre-train + fine-tune”的机器学习范式,即先得到大规模预训练语言模型,再基于该模型进行下游任务微调。这种机器学习范式过于简化,没有考虑到人类学习范式中的重要特性,即:预习时关注重点,上课时由易到难,复习时举一反三。因此,对于某个具体的NLP任务,我们应该在构建训练目标时就将这些特性考虑进来,通过设计出更具任务本身特点的新目标函数来模仿人类学习范式中的三阶段学习过程。
二 基于“预习-上课-复习”学习范式的多轮对话理解
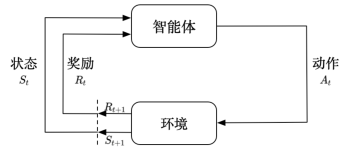
在本文中,我们主要研究任务型多轮对话系统中的核心任务 -- 对话状态跟踪(Dialog State Tracking, DST),并希望能够设计出多轮对话特有的“预习-上课-复习”三阶段学习范式以提升DST 模型的效果。
1 对话状态追踪任务介绍
首先, 我们介绍一下任务型对话系统和DST任务。
任务型对话系统是通过人机对话完成某个特定任务的系统,例如政务事务办理、满意度回访、订餐馆等。该系统不仅可以回答用户问题,同时还能主动发问,引导会话的有效进行,通过多轮对话完成特定任务。例如在一个餐馆查找场景中,一个典型的对话如下:

图2 任务型多轮对话示例
如图2所示,可以看到,在该对话中,机器人需要根据用户的不同的回答情况进行多轮的对话,最终收集完整自己需要的信息后给出找到的结果。
对话状态跟踪(DST)是一个重要的对话理解任务,即给定整个对话历史,将用户表达的语义识别成槽值对形式的对话标签。例如用户说 “我想要便宜的餐馆”,对应的DST语义标签就是 “价格=便宜”。 对话标签的集合一般已经预定义好,统称为对话本体(ontology)或者对话schema。
2 对话状态追踪任务难点
在一些经典的学术对话数据集中,例如 MultiWOZ[4],CrossWOZ[5]等,DST 任务普遍存在以下3个挑战:
- 不同槽之间的取值存在指代关联。例如用户在前几轮交互已经预定好了某家餐馆,在当前轮时,用户说 “我还想要该餐馆附近的一家酒店”,那么隐含地,酒店的area 槽值应当和餐馆的 area 槽值是一致的,这需要DST模型有能力识别出来。

- 用户隐含接受系统推荐。例如,当系统推荐某家酒店时,用户针对推荐的结果的态度既可以是正面的表达(that’s great),也可以是非正面的表达(hold on please),对应的hotel-name 槽也就会填或不填。

- 真实用户表达丰富多样,增大解析难度。例如,在DST任务中,每个槽有一个特殊的槽值叫 dontcare,用于表示用户对该槽可选取所有值,即没有特定值限制。在 MultiWOZ 数据集中,用户对于 dontcare 的表达多样性很大,十分考验模型的语言理解能力。

下图3是我们利用目前最好的DST 模型 TripPy[10],在 MultiWOZ2.1数据集上进行错误分析得到的一个错因占比统计。除了标注错误,后处理不当等额外因素,以上三类问题的占比达到约 42%,这需要更好的模型和方案来进行解决。

图3 MultiWoz 2.1 数据集DST错误分析(模型采用TriPy)
3 “预习-上课-复习”技术方案
针对上文提到的 DST 难点,我们希望能够从人类学习的过程中总结出一种特有范式来优化模型,实现一种model-agnostic的DST优化方案。基于此,我们设计了“预习-上课-复习”三阶段DST 训练方案,充分地利用好对话schema 中已经存在的槽值关联的结构(即 schema structure)和对话数据中存在的难易数据分布的结构(即 curriculum structure),提出了 Schema-aware Curriculum Learning for Dialog State Tracking (SaCLog) 通用的DST优化框架,如下图4所示:

图4 基于“预习-上课-复习”的对话状态追踪
预习模块(preview module)
我们希望在预习模块中能够实现对schema structure 的有效建模,通过设计类似[6]的带有结构偏置信息的预训练目标,让DST 模型的基座(如 BERT, BiRNN等)对schema 中信息有一个初步大致的了解,在不接触具体下游DST任务的情况下,先对各个槽的取值以及在用户语句中的表达有一个显式关系的建模。下图5是MultiWoz中的一个典型的schema structure:

图5 MultiWoz数据集中的典型的schema structure
实线连接的是同一个领域下的槽,虚线连接的是不同领域之间可能存在槽值关联的槽,整体形成了一个网络状的结构。每个槽的槽值在不同的自然语句中也会有不同的表达形式,我们希望将这些隐含的联系在预习阶段通过预训练的方式让模型学习出来。
具体的做法是,我们利用一个槽编码器和一个对话历史编码器(两个编码器共享参数,模型可选择BERT、BiRNN等)分别编码每个槽和对话历史,槽编码向量和对话历史的各个位置的向量进行两种loss计算,一种是操作分类loss ,判断某个槽在当前的对话语句中属于“增”、“删”、“改”、“无”四个操作中的哪一个操作类别,另一种是序列预测loss , 判断当前对话历史中,哪些词属于该槽的槽值(利用预设的字符串匹配得到)。同时我们再加上一个辅助的MLM loss ,对整个对话预料进行类似RoBERTa的预训练。最终整体loss是三者的加权和。
上课模块(attend module)
通过预习模块我们得到了一个预训练好的模型基座,如 BERT。接下来我们正式进行 DST 任务的学习。前面我们提到,在对话数据中存在的丰富的 curriculum structure,即数据的难易度分布的结构。下图6展示了一个简单和一个困难的对话例子:

图6 对话中不同难易程度的示意图
同样是用户想要一辆从 nandos 作为出发地的taxi, 图6中上方的对话例子是一个最简单的表达。而图6中下方的对话例子,尽管DST结果和简单例子一样,却要困难很多,用户是通过”from the restaurant”这种表述间接地表达了需要一辆出发地是nandos餐馆的taxi。
在前人的工作中,DST 模型一般都是采用 random sampling 的方式选择 batch data 进行优化的,这里,我们打算充分地考虑人在课程学习时的学习模式,将训练数据进行难易度划分,利用课程学习[1]中的经典算法 baby step[9]来优化,让模型先学习好简单的数据再学习复杂的数据。课程学习的诸多理论和实践[7]也已经证明了,这种类人教学的训练策略不仅能够加速模型收敛,还能够提升模型效果。下图是论文[8]中一个的可用于说明课程学习提升效果的示意图:

图7 课程学习效果提升示意图
假设我们的目标优化函数超曲面是最上方的一个曲线,下面的曲线分别是简单的优化函数超曲面,位置越下面说明训练数据越简单。可以看到,如果一开始就选择优化目标超曲面,模型很可能会陷入到局部峰值中,但是如果通过一系列合理的中间优化函数由简到难逐步逼近目标函数,那么模型就很可能跳出局部峰,达到更优解。
我们具体来看SaCLog中的上课模块是怎样实现的:首先我们使用了一个基于规则和模型的混合困难度打分器,模型打分器采用类似交叉验证的方式,将模型在训练集中的 K-fold 验证集上的预测概率作为模型得分,规则打分器利用了一些常见特征,如对话长度、当前轮槽值个数、实体词个数等作为规则得分,两类得分结合在一起对整个训练集进行排序,并提前划分成10个bucket。在 baby step 的训练中,首先让模型在最简单的bucket 数据上训练,当模型训练在现阶段训练集上收敛时再依次加入新的bucket一起训练,直至最终所有数据都加入了累计训练集。最后模型在全集上进一步训练至收敛为止。
复习模块(review module)
前面我们提到,复习是人类学习过程中的重要一环,所谓温故而知新,学习完重要的知识点后需要立即巩固练习,针对薄弱的环节加强训练。
落实到我们具体的SaCLog中的复习模块里,我们采取的方式是基于schema信息的数据增强方法,由于schema中已经预定义好了所有的槽和值,因此我们可以通过字符串匹配的方式尽可能地从对话语句中将相应位置的槽值找出来进行不同槽值的替换或者同义词替换,以扩充对话训练数据。我们在课程学习时,采取每次迭代的epoch 结尾都将模型预测出错的loss前10%的训练数据送入复习模块,通过槽替换、值替换和对话重组三种规则方式进行数据的扩充,将新增数据并入训练集一起参与下一轮训练。其中,对话重组是将和当前轮对话数据带有相同对话状态标签的其他对话数据进行历史对话和后续对话进行重新组合。
4 “预习-上课-复习”方案的实验结果
整体榜单
我们在 MultiWOZ2.1 和 WOZ2.0 两个经典的多轮对话数据集上进行了实验。首先,我们将 SaCLog 框架应用到目前最好的transformer-based DST模型TripPy [10] 上,利用预习模块对BERT基座进行预训练,再利用上课模块和复习模块对 TripPy进行DST 任务的fine-tune, 实验结果如下图所示:

可以看到应用我们的框架后,TripPy 模型在两个数据集上性能都有很大提升,取得到了目前最佳结果。
消融实验
同时在MultiWOZ2.1上我们也进行了一个ablation study,发现利用预习模块和复习模块能够带来最大的提升。

其他实验
为了验证我们框架的通用性,我们也在目前最好的RNN-based DST 模型 TRADE [11] 上进行验证,发现同样也能带来提升。

三 整体总结
本文主要介绍了如何通过模仿人类“预习-上课-复习”的三阶段学习范式,设计出一个适用于对话状态跟踪任务的通用优化框架。具体来看我们采用了预习、上课、复习三个模块,通过充分利用对话数据中的schema structure 和curriculum structure 以提升模型的性能。实验表明,我们在利用了SaCLog优化框架后,在多个多轮对话数据集上都取得了目前最好效果。
四 新学习范式的未来展望
在未来,我们希望能将“预习-上课-复习”三阶段学习范式扩展到更多的任务中,例如 对话生成、端到端对话系统,以及其他的 NLP 任务。我们希望这样的新范式能够带来更多的训练优化方法上的变革,同时也准备在对话系统的业务落地上开展更多的实践应用。
智能对话系统是个极具前景和挑战性的方向,达摩院 Conversational AI团队将不断地探索推进在这个领域的技术进步和落地,敬请期待我们后续的工作!
五 参考文献
[1] Bengio Y, et al. Curriculum learning. ICML19.
[2] Yinpei Dai, et al. Preview, Attend and Review: Schema-Aware Curriculum Learning for Multi-Domain Dialog State Tracking.ACL21.
[3] https://www.educationcorner.com/the-study-cycle.html
[4] Eric M et al. MultiWOZ 2.1: A consolidated multi-domain dialogue dataset with state corrections and state tracking baselines.LERC, 2020.
[5] Zhu Q, Huang K, Zhang Z, et al. Crosswoz: A large-scale chinese cross-domain task-oriented dialogue dataset. TACL, 2020.
[6]Yu T, Zhang R, Polozov O, et al. SCORE: PRE-TRAINING FOR CONTEXT REPRESENTA-TION IN CONVERSATIONAL SEMANTIC PARSING. ICLR 2021.
[7] Xin Wang, Yudong Chen and Wenwu Zhu. A Survey on Curriculum Learning. PAMI 2021.
[8] Bengio Y. Evolving culture versus local minima. Growing Adaptive Machines, 2014.
[9] Spitkovsky V I, Alshawi H, Jurafsky D. From baby steps to leapfrog: How “less is more” in unsupervised dependency parsing. NAACL 2010.
[10] Heck M, van Niekerk C, Lubis N, et al. Trippy: A triple copy strategy for value independent neural dialog state tracking. SIGDIAL, 2020.
[11] Wu C S, Madotto A, Hosseini-Asl E, et al. Transferable multi-domain state generator for task-oriented dialogue systems. ACL, 2019.
饮水思源、万象更新 - 数据库开源(杭州站)沙龙活动
本次沙龙是PostgreSQL中文社区与阿里云数据库开源团队联合主办的。PostgreSQL生态技术沙龙,旨在推动PG的用户交流,分享最新热门的数据库技术,包括阿里云开源的PolarDBforPG共享存储版本如何实现类似Oracle的RAC架构?PG如何支持DirectIO?PG的内核学习方法等。
大咖云集,点击这里查看详情!