.png")
关于我们
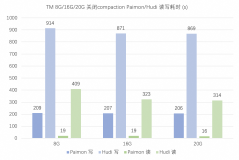
E-MapReduce团队负责阿里云云原生数据湖相关产品/技术研发,详见我们发布的数据湖白皮书
目前团队负责公有云两款产品
1. E-MapReduce
E-MapReduce构建在阿里云云服务器 ECS/K8S 上的开源 Hadoop、Spark、HBase、Hive、Flink 生态大数据 PaaS 产品。提供用户在云上使用开源技术建设数据仓库、离线批处理、在线流式处理、即时查询、机器学习等场景下的大数据解决方案。
2. 数据湖构建(Data Lake Formation)
数据湖构建(Data Lake Formation,DLF)作为云原生数据湖架构核心组成部分,帮助用户简单快速地构建云原生数据湖解决方案。数据湖构建提供湖上元数据统一管理、企业级权限控制,并无缝对接多种计算引擎,打破数据孤岛,洞察业务价值。
实习岗位
1.参与各种大数据开源组件内核的研发(如Spark/Hive/Presto/Delta Lake/Hudi/HBase/Kudu/Imapala/ClickHouse等等)
- Spark/Presto on K8S等云原生产品技术研发
- HDFS、基于对象存储OSS等分布式存储技术研发
4.参与开源组件社区工作(如Spark),贡献代码,目前团队中有Spark/HDFS等多位committer
5.能够接触了解国内外企业级客户在大数据/数据湖等场景遇到的各种挑战(性能/功能),并参与解决
岗位要求
- 本科及以上学历(2022届),计算机、数学、电子工程、通信等相关专业;
- 具备扎实的数据结构和计算机系统基础,精通一种开发语言;
- 对基础软件充满热情,具备较好的动手能力和技术热情,有成功的研究型或实战型项目技术成果落地者优先;
- 关注开源技术,有开源贡献者优先;
- 快速学习,不断突破技术瓶颈,乐于探索未知领域,随时准备好去面对新挑战;
- 良好的团队合作精神,能够做到严谨、皮实、乐观。
联系方式
发简历到邮箱:
北京: yanhui.jy@alibaba-inc.com
杭州: songjun.sj@alibaba-inc.com
上海: zhengkai.zk@alibaba-inc.com
感兴趣的同学,欢迎加群交流
附: