架构选择(ELK VS EFK)
ELK
我们首先介绍一下传统的日志监控方案。其中,ELK Stack 是我 们最熟悉不过的架构。所谓ELK,分别指Elastic公司的Elasticsearch、Logstash、Kibana。在比较旧的ELK架构中,Logstash身兼日志的采集、过滤两职。但由于Logstash基于JVM,性能有一定限制,因此,目前业界更推荐使用Go语言开发FIiebeat代替Logstash的采集功能,Logstash只作为了日志过滤的中间件。
最常见的ELK架构如下:
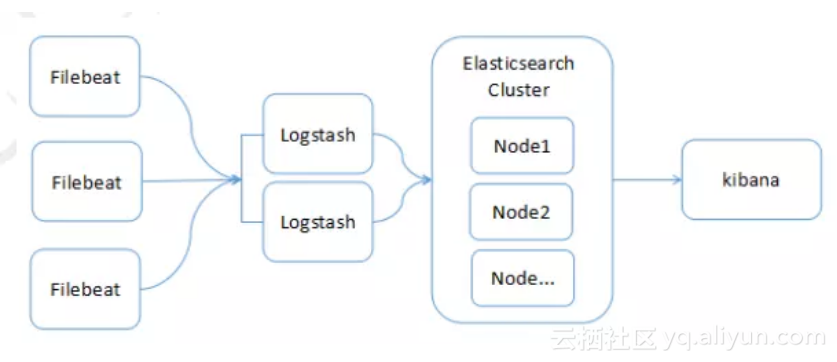
如上图所示,各角色功能如下:
多个Filebeat在各个业务端进行日志采集,然后上传至Logstash
多个Logstash节点并行(负载均衡,不作为集群),对日志记录进行过滤处理,然后上传至Elasticsearch集群
多个Elasticsearch构成集群服务,提供日志的索引和存储能力
Kibana负责对Elasticsearch中的日志数据进行检索、分析
当然,在该架构中,根据业务特点,还可以加入某些中间件,如Redis、Kafak等:
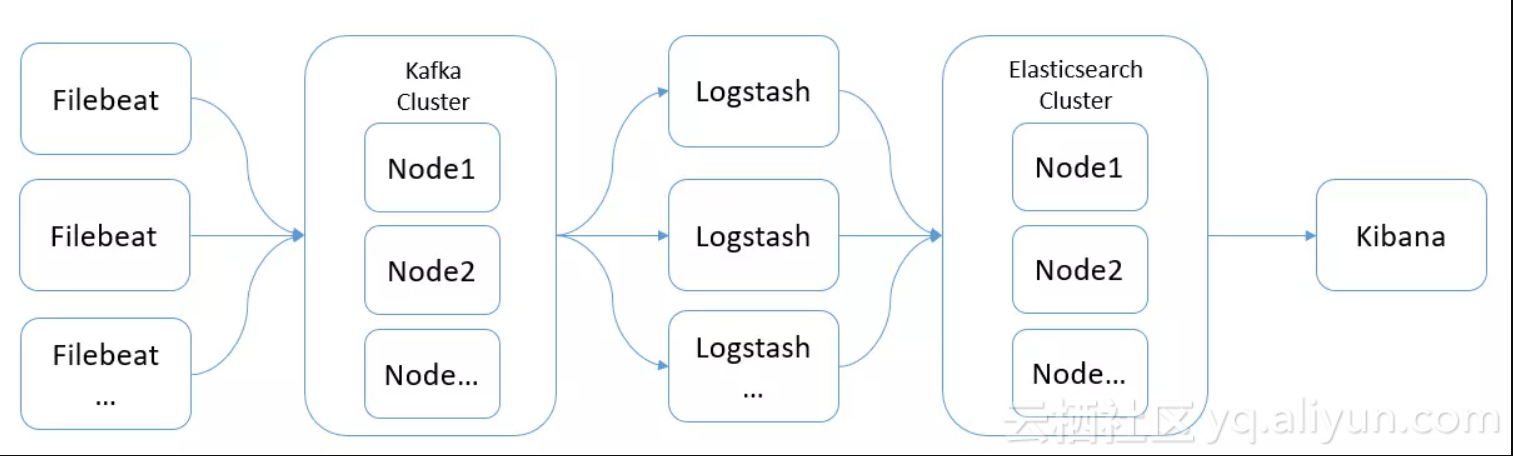
如上图所示,Kafka集群作为消息缓冲队列,可以降低大量FIlebeat对Logstash的并发访问压力。
EFK
目前,在K8S的日志监控解决方案中,EFK也是较常用的架构。所谓的EFK,即Elasticsearch + Fluentd + Kibana。在该架构中,Fluentd作为日志采集客户端。但我个人认为,相对于Filebeat,Fluentd并没有突出的优势。并且,由于同属于Elastic公司,Filebeat可以更好的兼容其产品栈。因此,在K8S上,我仍然推荐ELK架构。
日志采集方式
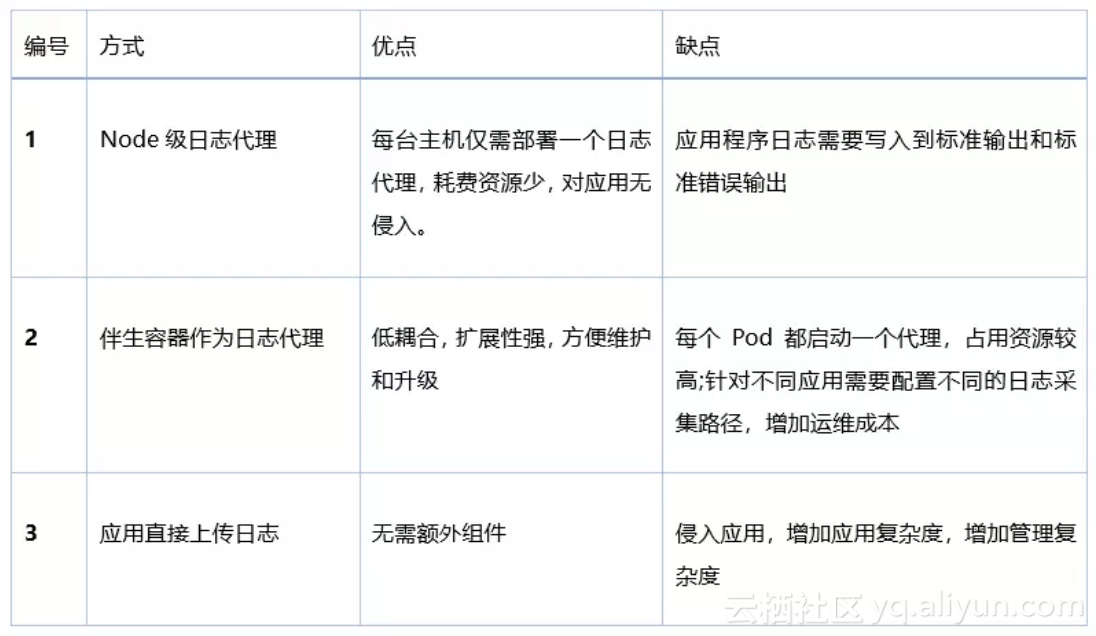
确定使用ELK+Filebeat作为架构后,我们还需要明确Filebeat采集K8S集群日志的方式,这也是本文的重点。官方文档中提到了三种采集方式,这里简单介绍一下:
方式1:Node级日志代理
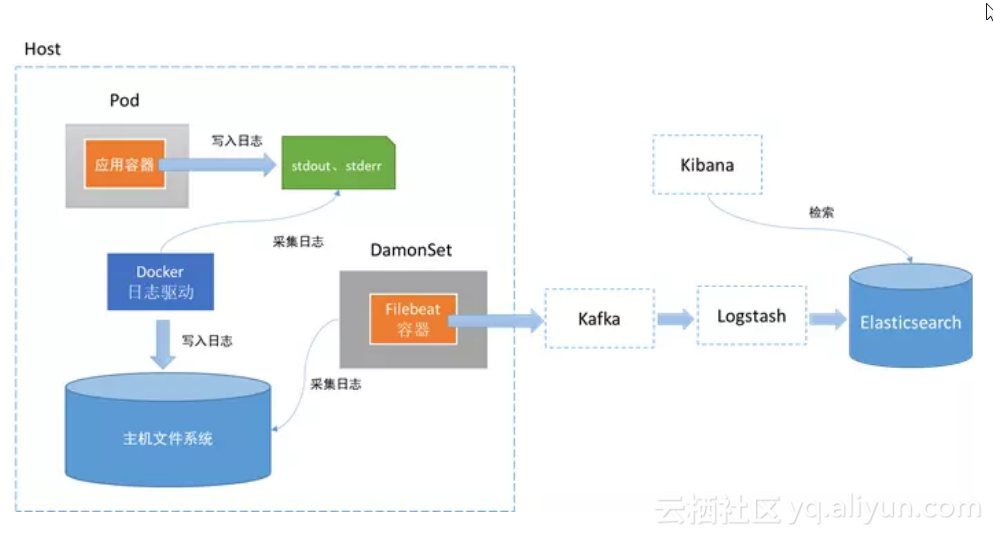
在每个节点(即宿主机)上可以独立运行一个Node级日志代理,通常的实现方式为DaemonSet。用户应用只需要将日志写到标准输出,Docker 的日志驱动会将每个容器的标准输出收集并写入到主机文件系统,这样Node级日志代理就可以将日志统一收集并上传。另外,可以使用K8S的logrotate或Docker 的log-opt 选项负责日志的轮转。
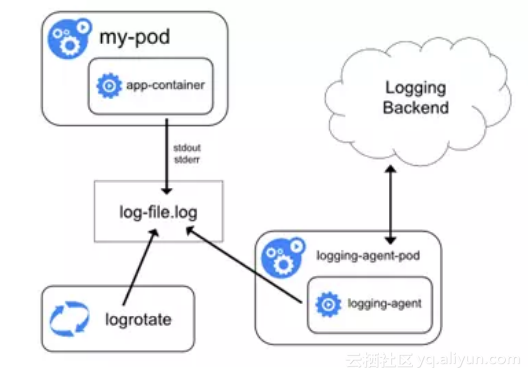
Docker默认的日志驱动(LogDriver)是json-driver,其会将日志以JSON文件的方式存储。所有容器输出到控制台的日志,都会以*-json.log的命名方式保存在/var/lib/docker/containers/目录下。对于Docker日志驱动的具体介绍,请参考官方文档。另外,除了收集Docker容器日志,一般建议同时收集K8S自身的日志以及宿主机的所有系统日志,其位置都在var/log下。
所以,简单来说,本方式就是在每个node上各运行一个日志代理容器,对本节点/var/log和 /var/lib/docker/containers/两个目录下的日志进行采集,然后汇总到elasticsearch集群,最后通过kibana展示。
方式2:伴生容器(sidecar container)作为日志代理
创建一个伴生容器(也可称作日志容器),与应用程序容器在处于同一个Pod中。同时伴生容器内部运行一个独立的、专门为收集应用日志的代理,常见的有Logstash、Fluentd 、Filebeat等。日志容器通过共享卷可以获得应用容器的日志,然后进行上传。
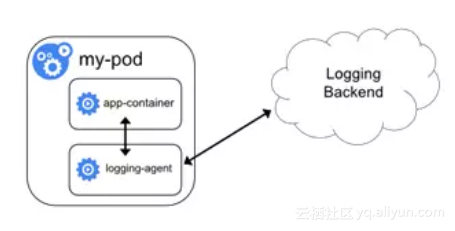
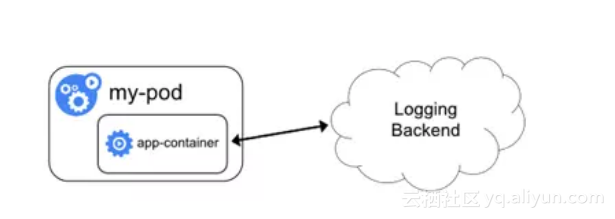
方式3:应用直接上传日志
应用程序容器直接通过网络连接上传日志到后端,这是最简单的方式。
对比
其中,相对来说,方式1在业界使用更为广泛,并且官方也更为推荐。因此,最终我们采用ELK+Filebeat架构,并基于方式1,如下:
准备操作
DaemonSet概念介绍
在搭建前,我们先简单介绍一下方式1中提到的DaemonSet,这也是一个重要的概念:
DaemonSet能够让所有(或者一些特定)的Node节点运行同一个pod。当节点加入到kubernetes集群中,pod会被(DaemonSet)调度到该节点上运行,当节点从kubernetes集群中被移除,被(DaemonSet)调度的pod会被移除,如果删除DaemonSet,所有跟这个DaemonSet相关的pods都会被删除。
因此,我们可以使用DaemonSet来部署Filebeat。这样,每当集群加入一个新的节点,该节点就会自动创建一个Filebeat守护进程,并有且只有一个。
另外,由于篇幅限制,本文只介绍如何通过基于DaemonSet的Filebeat来收集K8S集群的日志,而非介绍如何在K8S上搭建一个ELK集群。同时,日志记录将直接上传至Elasticsearch中,而不通过Logstash,并且本文假设Elasticsearch集群已提前搭建完毕可直接使用。
清楚了本文的侧重点后,好,走你~
官方Filebeat部署脚本介绍
这里,我们将基于Elastic官方提供的Filebeat部署脚本进行部署,如下所示:
---
apiVersion: v1
kind: ConfigMap
metadata:
name: filebeat-config
namespace: kube-system
labels:
k8s-app: filebeat
kubernetes.io/cluster-service: "true"
data:
filebeat.yml: |-
filebeat.config:
prospectors:
# Mounted `filebeat-prospectors` configmap:
path: ${path.config}/prospectors.d/*.yml
# Reload prospectors configs as they change:
reload.enabled: false
modules:
path: ${path.config}/modules.d/*.yml
# Reload module configs as they change:
reload.enabled: false
processors:
- add_cloud_metadata:
cloud.id: ${ELASTIC_CLOUD_ID}
cloud.auth: ${ELASTIC_CLOUD_AUTH}
output.elasticsearch:
hosts: ['${ELASTICSEARCH_HOST:elasticsearch}:${ELASTICSEARCH_PORT:9200}']
username: ${ELASTICSEARCH_USERNAME}
password: ${ELASTICSEARCH_PASSWORD}
---
apiVersion: v1
kind: ConfigMap
metadata:
name: filebeat-prospectors
namespace: kube-system
labels:
k8s-app: filebeat
kubernetes.io/cluster-service: "true"
data:
kubernetes.yml: |-
- type: docker
containers.ids:
- "*"
processors:
- add_kubernetes_metadata:
in_cluster: true
---
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: filebeat
namespace: kube-system
labels:
k8s-app: filebeat
kubernetes.io/cluster-service: "true"
spec:
template:
metadata:
labels:
k8s-app: filebeat
kubernetes.io/cluster-service: "true"
spec:
serviceAccountName: filebeat
terminationGracePeriodSeconds: 30
containers:
- name: filebeat
image: docker.elastic.co/beats/filebeat:6.2.4
args: [
"-c", "/etc/filebeat.yml",
"-e",
]
env:
- name: ELASTICSEARCH_HOST
value: elasticsearch
- name: ELASTICSEARCH_PORT
value: "9200"
- name: ELASTICSEARCH_USERNAME
value: elastic
- name: ELASTICSEARCH_PASSWORD
value: changeme
- name: ELASTIC_CLOUD_ID
value:
- name: ELASTIC_CLOUD_AUTH
value:
securityContext:
runAsUser: 0
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 100Mi
volumeMounts:
- name: config
mountPath: /etc/filebeat.yml
readOnly: true
subPath: filebeat.yml
- name: prospectors
mountPath: /usr/share/filebeat/prospectors.d
readOnly: true
- name: data
mountPath: /usr/share/filebeat/data
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
volumes:
- name: config
configMap:
defaultMode: 0600
name: filebeat-config
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
- name: prospectors
configMap:
defaultMode: 0600
name: filebeat-prospectors
- name: data
emptyDir: {}
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: filebeat
subjects:
- kind: ServiceAccount
name: filebeat
namespace: kube-system
roleRef:
kind: ClusterRole
name: filebeat
apiGroup: rbac.authorization.k8s.io
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRole
metadata:
name: filebeat
labels:
k8s-app: filebeat
rules:
- apiGroups: [""] # "" indicates the core API group
resources:
- namespaces
- pods
verbs:
- get
- watch
- list
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: filebeat
namespace: kube-system
labels:
k8s-app: filebeat
---
如上,看起来似乎挺复杂,可以分为如下几个部分:
ConfigMap
DaemonSet
ClusterRoleBinding
ClusterRole
ServiceAccount
ConfigMap
我们先重点关注一下DaemonSet的volumeMounts和volumes,以了解ConfigMap的挂载方式:
volumeMounts:
- name: config
mountPath: /etc/filebeat.yml
readOnly: true
subPath: filebeat.yml
- name: prospectors
mountPath: /usr/share/filebeat/prospectors.d
readOnly: true
- name: data
mountPath: /usr/share/filebeat/data
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
volumes:
- name: config
configMap:
defaultMode: 0600
name: filebeat-config
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
- name: prospectors
configMap:
defaultMode: 0600
name: filebeat-prospectors
- name: data
emptyDir: {}
如上,volumeMounts包括四个部分,解释如下:
config
filebeat-config这个Configmap会生成一个filebeat.yml文件,其会被挂载为Filebeat的配置文件/etc/filebeat.yml
prospectors
prospectors这个Configmap会生成一个kubernetes.yml文件,其会被挂载到路径/usr/share/filebeat/prospectors.d下,并被filebeat.yml引用
data
Filebeat自身的数据挂载为emptyDir: {}
varlibdockercontainers
K8S集群的日志都存储在/var/lib/docker/containers,Filebeat将从该路径进行收集
了解了ConfigMap的挂载方式后,现在,我们分析第一个ConfigMap:
---
apiVersion: v1
kind: ConfigMap
metadata:
name: filebeat-config
namespace: kube-system
labels:
k8s-app: filebeat
kubernetes.io/cluster-service: "true"
data:
filebeat.yml: |-
filebeat.config:
prospectors:
# Mounted `filebeat-prospectors` configmap:
path: ${path.config}/prospectors.d/*.yml
# Reload prospectors configs as they change:
reload.enabled: false
modules:
path: ${path.config}/modules.d/*.yml
# Reload module configs as they change:
reload.enabled: false
processors:
- add_cloud_metadata:
cloud.id: ${ELASTIC_CLOUD_ID}
cloud.auth: ${ELASTIC_CLOUD_AUTH}
output.elasticsearch:
hosts: ['${ELASTICSEARCH_HOST:elasticsearch}:${ELASTICSEARCH_PORT:9200}']
username: ${ELASTICSEARCH_USERNAME}
password: ${ELASTICSEARCH_PASSWORD}
我们知道,Configmap的每个key都会生成一个同名的文件,因此这里会创建一个配置文件filebeat.yml文件,其内容中的环境变量将由DaemonSet中的env部分定义。
在filebeat.yml中,可以看到Filebeat的一个重要组件: prospectors(采矿者),其主要用来指定从哪些文件中采集数据。这里,prospectors并没有直接指定目标文件,而是间接的引用路径:${path.config}/prospectors.d/*.yml,由前面可知,该路径中的yml文件由第二个ConfigMap定义:
---
apiVersion: v1
kind: ConfigMap
metadata:
name: filebeat-prospectors
namespace: kube-system
labels:
k8s-app: filebeat
kubernetes.io/cluster-service: "true"
data:
kubernetes.yml: |-
- type: docker
containers.ids:
- "*"
processors:
- add_kubernetes_metadata:
in_cluster: true
如上,type指定了prospectors的类型为docker,表示收集本机的docker日志。containers.ids为*表示监听所有容器。type除了docker,一般使用更多的是log,可以直接指定任何路径上的日志文件,参见官方文档。
部署步骤
介绍完Filebeat的部署脚本后,我们开始真正的部署过程。
1.部署Filebeat
官方配置文件无法直接使用,需要我们定制。首先,修改DaemonSet中的环境变量env:
env:
- name: ELASTICSEARCH_HOST
value: "X.X.X.X"
- name: ELASTICSEARCH_PORT
value: "9200"
- name: ELASTICSEARCH_USERNAME
value:
- name: ELASTICSEARCH_PASSWORD
value:
- name: ELASTIC_CLOUD_ID
value:
- name: ELASTIC_CLOUD_AUTH
value:
如上,ELASTICSEARCH_HOST指定为Elasticsearch集群的入口地址,端口ELASTICSEARCH_PORT为默认的9200;由于我的集群没有加密,因此ELASTICSEARCH_USERNAME和ELASTICSEARCH_PASSWORD全部留空,大家可以酌情修改;其他保持默认。
同时,还需要注释掉第一个ConfigMap中output.elasticsearch的用户名和密码:
output.elasticsearch:
hosts: ['${ELASTICSEARCH_HOST:elasticsearch}:${ELASTICSEARCH_PORT:9200}']
#username: ${ELASTICSEARCH_USERNAME}
#password: ${ELASTICSEARCH_PASSWORD}
其次,还需要修改第二个ConfigMap的data部分为:
data:
kubernetes.yml: |-
- type: log
enabled: true
paths:
- /var/log/*.log
- type: docker
containers.ids:
- "*"
processors:
- add_kubernetes_metadata:
in_cluster: true
如上,type: docker的配置可以对K8S上所有Docker容器产生的日志进行收集。另外,为了收集宿主机系统日志和K8S自身日志,我们还需要获取/var/log/*.log。
修改并创建完毕后,查看DaemonSet信息,如下图所示:
[root@k8s-node1 filebeat]# kubectl get ds -n kube-system
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
calico-etcd 1 1 1 1 1 node-role.kubernetes.io/master= 5d
calico-node 3 3 3 3 3 <none> 5d
filebeat 2 2 0 2 0 <none> 24s
kube-proxy 3 3 3 3 3 <none> 5d
查看pod信息,每个节点都会启动一个filebeat容器:
filebeat-hr5vq 1/1 Running 1 3m 192.168.169.223 k8s-node2
filebeat-khzzj 1/1 Running 1 3m 192.168.108.7 k8s-node3
filebeat-rsnbl 1/1 Running 0 3m 192.168.36.126 k8s-node1
2.部署Kibana
参考官方示例,我们按需修改为如下:
apiVersion: apps/v1
kind: Deployment
metadata:
name: kibana-logging
namespace: kube-system
labels:
k8s-app: kibana-logging
spec:
replicas: 1
selector:
matchLabels:
k8s-app: kibana-logging
template:
metadata:
labels:
k8s-app: kibana-logging
spec:
containers:
- name: kibana-logging
image: docker.elastic.co/kibana/kibana:6.2.4
resources:
# need more cpu upon initialization, therefore burstable class
limits:
cpu: 1000m
requests:
cpu: 100m
env:
- name: ELASTICSEARCH_URL
value: http://X.X.X.X:9200
ports:
- containerPort: 5601
name: ui
protocol: TCP
---
apiVersion: v1
kind: Service
metadata:
name: kibana-logging
namespace: kube-system
labels:
k8s-app: kibana-logging
spec:
type: NodePort
ports:
- port: 5601
targetPort: 5601
selector:
k8s-app: kibana-logging
如上,Kibana的版本为6.2.4,并且一定要与Filebeat、Elasticsearch保持一致。另外,注意将Deployment中env的环境变量ELASTICSEARCH_URL,修改为自己的Elasticsearch集群地址。
这里我们使用了Service暴露了NodePort,当然也可以使用Ingress。
3.访问Kibana
好了,现在我们可以通过NodeIp:NodePort或Ingress方式来访问Kibana。在配置Elasticsearch索引前缀后,即可检索日志:
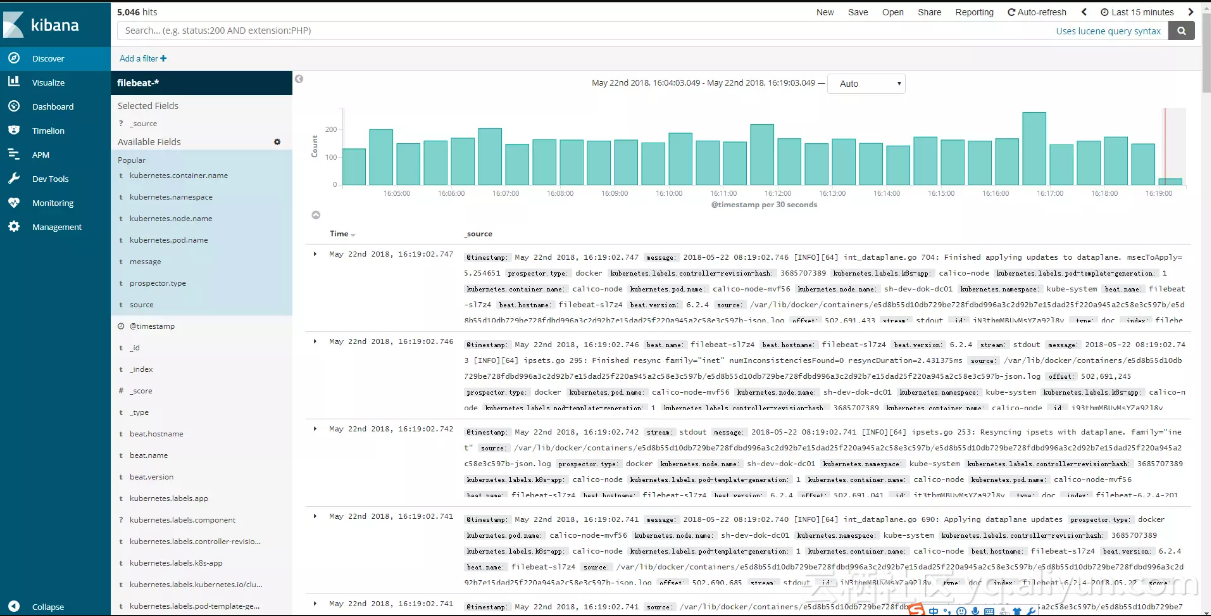
如上,可以看到K8S中各个容器的日志,当然也包括宿主机的系统日志。
4.测试应用日志
至此,我们通过Filebeat成功获取了K8S上的容器日志以及系统日志。但在实际中,我们更关注的是应用程序的业务日志。这里,我们编写一个简单的JAVA项目来测试一下。
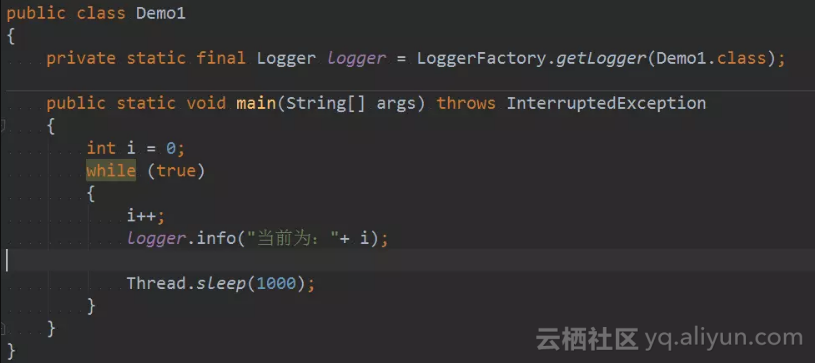
测试代码
只是简单的循环输出递增序列:
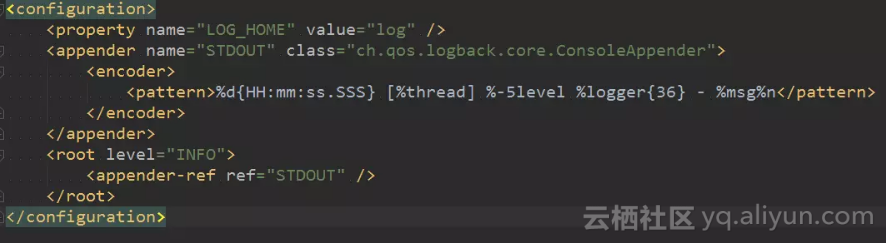
logback.xml
appender指定为STDOUT即可:
Dockerfile
可以使用gradle将项目发布为tar包,然后拷贝到java:9-re镜像中。在build镜像后,记得别忘记上传至自己的仓库中:

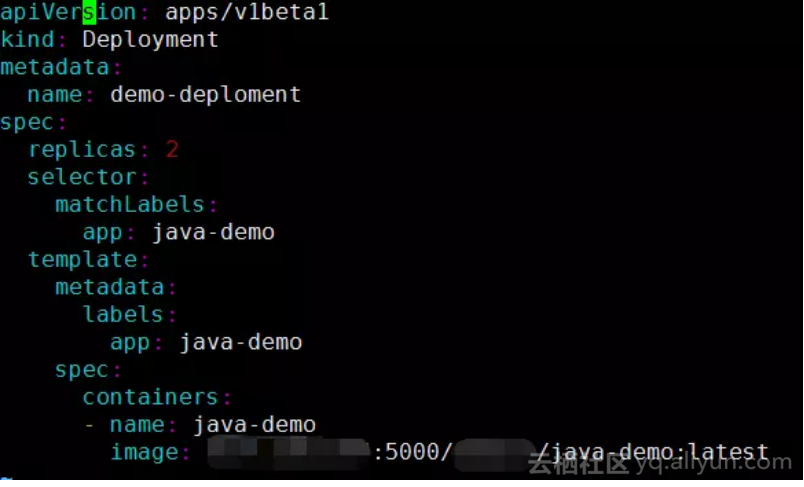
K8S部署脚本
执行该脚本即可完成测试项目的部署:
输出日志
我们可以去/var/lib/docker/containers/下查看测试项目输出的json格式日志:
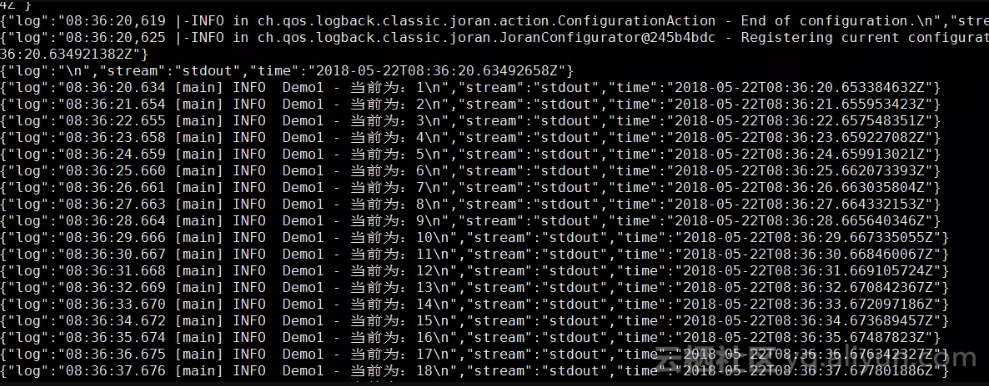
在Dashborad中,也可以查看标准输出的日志:
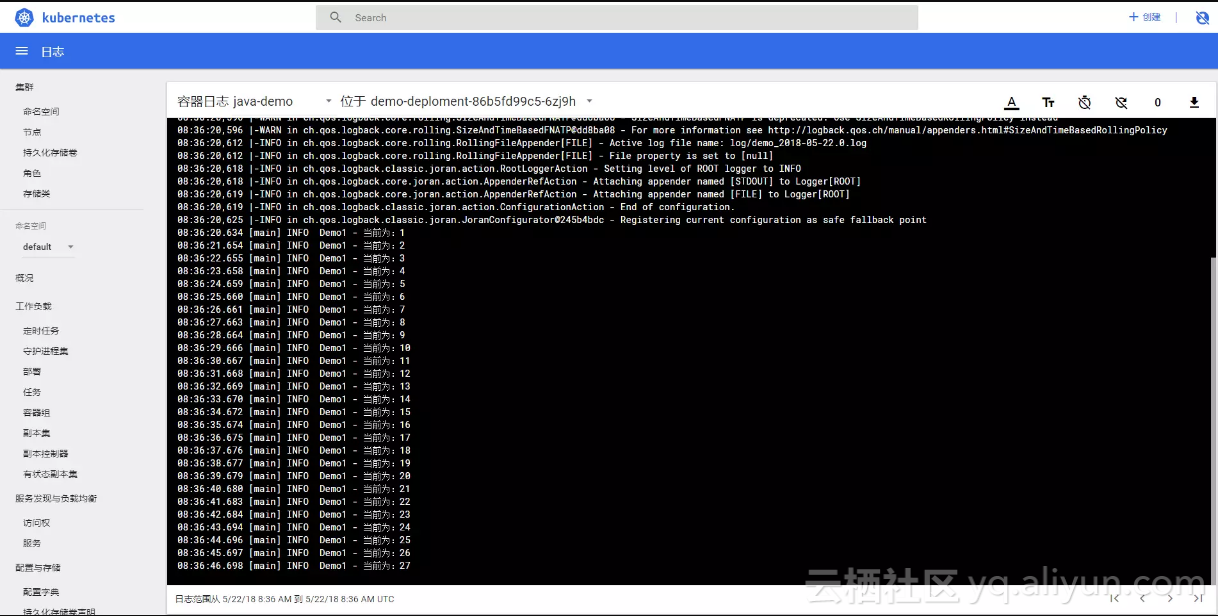
好了,我们已经成功的通过Filebeat上传了自定义的应用程序日志,收工~
本文转自CSDN-从零开始搭建K8S--如何监控K8S集群日志