Kaggle的比赛真的好玩到令人上瘾。在享受比赛的过程中,如果比赛成绩能够名列前茅那就非常棒了~~~
一位名叫Abhay Pawar的小哥开发了一些特征工程和机器学习建模的标准方法。这些简单而强大的技术帮助他在Instacart Market Basket Analysis竞赛中取得了前2%的成绩。
下文是他以第一人称为小伙伴们分享他的技术经验。希望对你有所帮助。enjoy!
要构建数值型连续变量的监督学习模型,最重要的方面之一就是好好理解特征。观察一个模型的部分依赖图有助于理解模型的输出是如何随着每个特征变化而改变的。
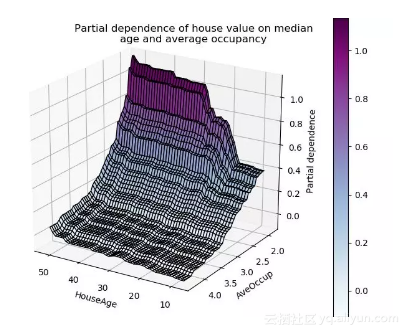
但是,绘制的图形是基于训练好的模型构建的,这会引发一些问题。而如果我们直接用未经学习的训练数据去作图,我们就能更好理解这些数据的深层含义。因为这样做能帮助我们进行:
● 特征理解● 识别嘈杂特征(这是最有趣的!)
● 特征工程
● 特征重要性
● 特征调试
● 泄漏检测与理解
● 模型监控
为了方便大家使用,我把这些方法用Python做了一个包,叫做featexp。本文中,我们会利用它来进行特征探索。我们将使用来自Kaggle竞赛“违约者预测”的数据集,竞赛的任务是基于已有的数据预测债务违约者。
featexp:
https://github.com/abhayspawar/featexp
Home Credit Default Risk
https://www.kaggle.com/c/home-credit-default-risk/
特征理解
如果因变量 (分析目标) 是二分类数据,散点图就不太好用了,因为所有点不是0就是1。针对连续型变量,数据点太多的话,会让人很难理解目标和特征之间的关系。但是,用featexp可以做出更加友好的图像。让我们试一下吧!
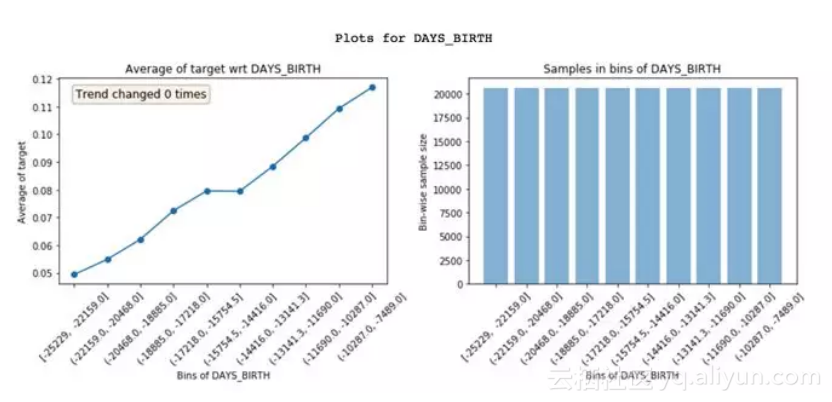
Featexp可以把一个数字特征,分成很多个样本量相等的区间(X轴)。然后,计算出目标的平均值 (Mean),并绘制出左上方的图像。在这里,平均值代表违约率。图像告诉我们,年纪 (DAYS_BIRTH) 越大的人,违约率越低。
这非常合理的,因为年轻人通常更可能违约。这些图能够帮助我们理解客户的特征,以及这些特征是如何影响模型的。右上方的图像表示每个区间内的客户数量。
识别嘈杂特征
嘈杂特征容易造成过拟合,分辨噪音一点也不容易。在featexp里,你可以跑一下测试集或者验证集,然后对比训练集和测试集的特征趋势,从而找出嘈杂的特征。
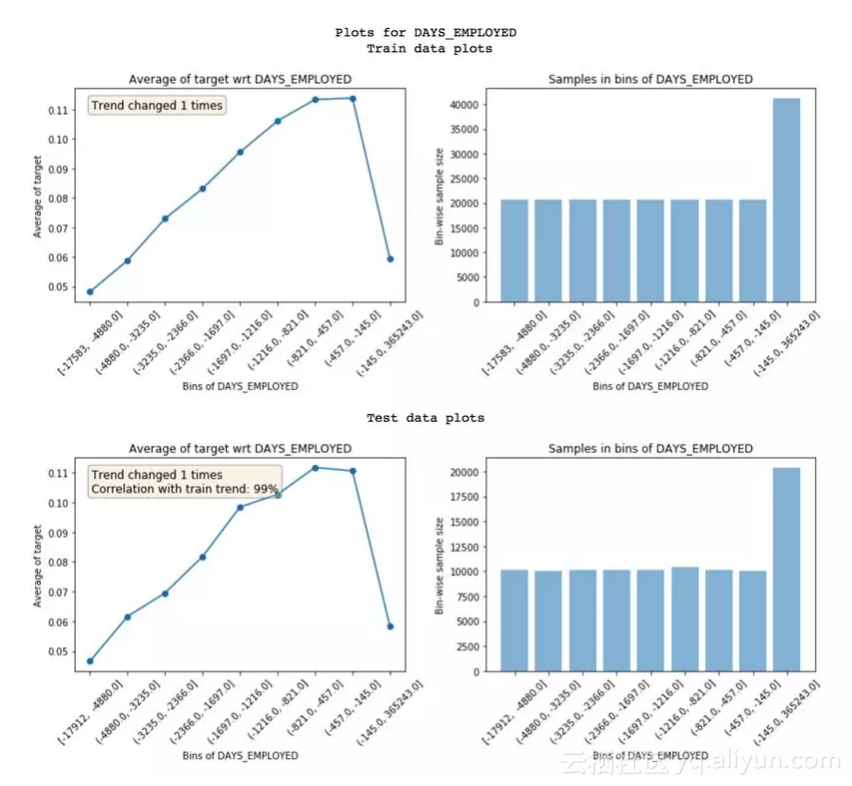
训练集和测试集特征趋势的对比
为了衡量噪音影响程度,featexp会计算两个指标:
● 趋势相关性 (从测试绘图中可见) :如果一个特征在训练集和测试集里面表现出来的趋势不一样,就有可能导致过拟合。这是因为,模型从测试集里学到的一些东西,在验证集中不适用。趋势相关性可以告诉我们训练集和测试集趋势的相似度,以及每个区间的平均值。上面这个例子中,两个数据集的相关性达到了99%。看起来噪音不是很严重!● 趋势变化:有时候,趋势会发生突然变化和反复变化。这可能就参入噪音了,但也有可能是特定区间内有其他独特的特征对其产生了影响。如果出现这种情况,这个区间的违约率就没办法和其他区间直接对比了。
下面这个特征,就是嘈杂特征,训练集和测试集没有相同的趋势:两者相关性只有85%。有时候,可以选择丢掉这样的特征。
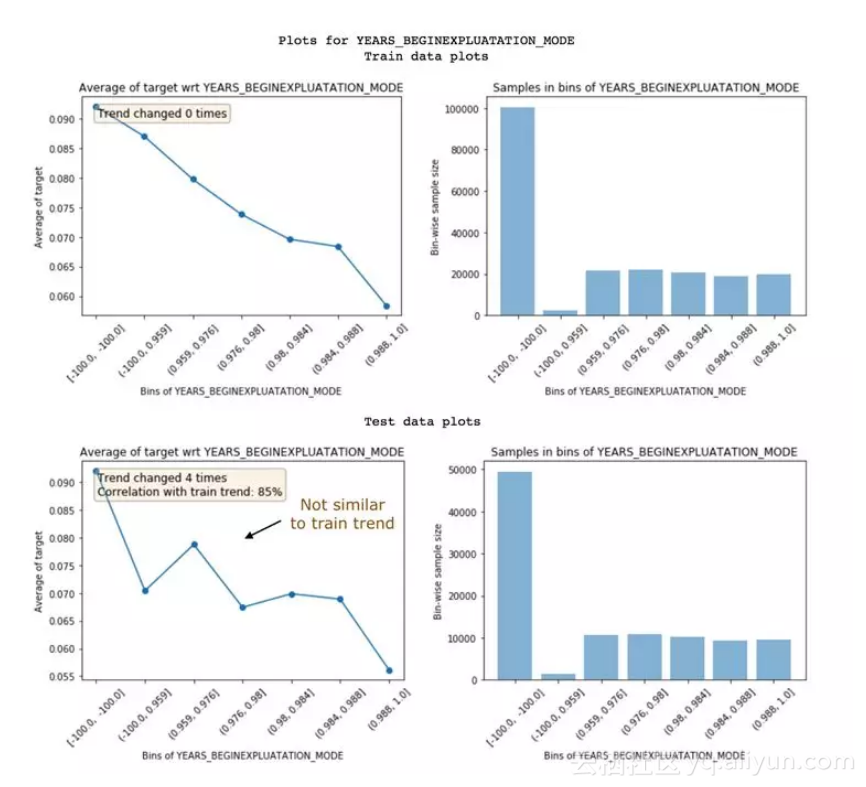
嘈杂特征的例子
抛弃相关性低的特征,这种做法在特征非常多、特征之间又充满相关性的情况下比较适用。这样可以减少过拟合,避免信息丢失。不过,别把太多重要的特征都丢掉了;否则模型的预测效果可能会大打折扣。同时,你也不能用重要性来评价特征是否嘈杂,因为有些特征既非常重要,又嘈杂得不得了。
用与训练集不同时间段的数据来做测试集可能会比较好。这样就能看出来数据是不是随时间变化的了。
Featexp里有一个 get_trend_stats() 函数,可以返回一个数据框 (Dataframe) ,显示趋势相关性和趋势变化。
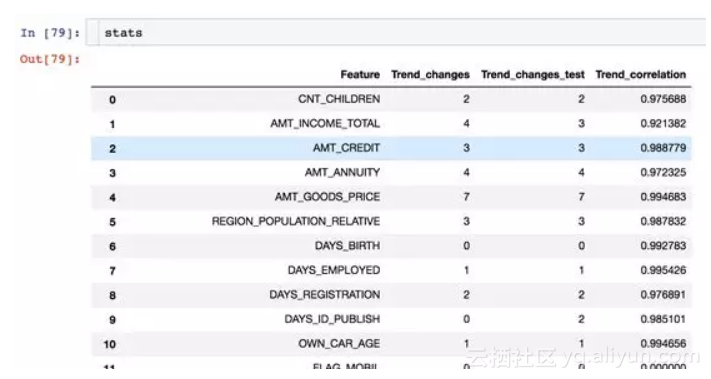
get_trend_stats()返回的数据框
现在,可以试着去丢弃一些趋势相关性弱的特征了,看看预测效果是否有提高。
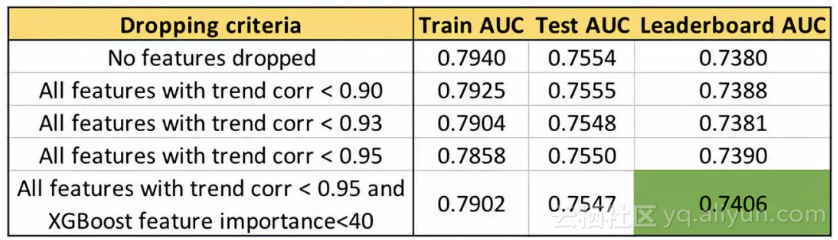
用趋势相关性进行不同特征选择得到的的AUC值
我们可以看到,丢弃特征的相关性阈值越高,排行榜(LB)上的AUC越高。只要注意不要丢弃重要特征,AUC可以提升到0.74。有趣的是,测试集的AUC并没有像排行榜的AUC变化那么大。完整代码可以在featexp_demo记事本里面找到。
featexp_demo
https://github.com/abhayspawar/featexp/blob/master/featexp_demo.ipynb
特征工程
通过查看这些图表获得的见解,有助于我们创建更好的特征。只需更好地了解数据,就可以实现更好的特征工程。除此之外,它还可以帮助你改良现有特征。下面来看另一个特征EXT_SOURCE_1:
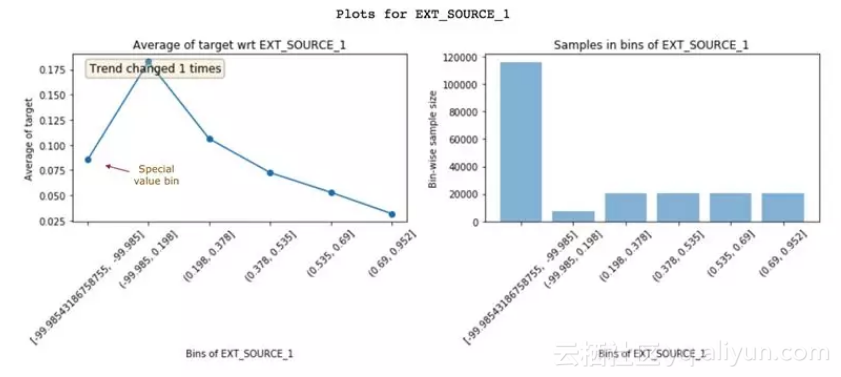
EXT_SOURCE_1的特征与目标图
具有较高EXT_SOURCE_1值的客户违约率较低。但是,第一个区间(违约率约8%)不遵循这个特征趋势(上升并下降)。它只有-99.985左右的负值且人群数量较多。这可能意味着这些是特殊值,因此不遵循特征趋势。幸运的是,非线性模型在学习这种关系时不会有问题。但是,对于像Logistic回归这样的线性模型,如果需要对特殊值和控制进行插值,就需要考虑特征分布,而不是简单地使用特征的均值进行插补。
特征重要性
Featexp还可以帮助衡量特征的重要性。DAYS_BIRTH和EXT_SOURCE_1都有很好的趋势。但是,EXT_SOURCE_1的人群集中在特殊值区间中,这表明它可能不如DAYS_BIRTH那么重要。基于XGBoost模型来衡量特征重要性,发现DAYS_BIRTH实际上比EXT_SOURCE_1更重要。
特征调试
查看Featexp的图表,可以帮助你通过以下两项操作来发现复杂特征工程代码中的错误:

零方差特征只展现一个区间
1、检查特征的人群分布是否正确。由于一些疏忽,我遇到过多次类似上面这样的极端情况。
2、在查看这些图之前,我总是会先做假设,假设特征趋势会是什么样子的。如果特征趋势看起来不符合预期,可能暗示着存在某些问题。实际上,这个验证趋势假设的过程使机器学习模型更有趣了!
泄漏检测
从目标到特征的数据泄漏会导致过拟合。泄露的特征具有很高的特征重要性。要理解为什么在特征中会发生泄漏是很困难的,查看featexp图像可以帮助理解这一问题。
在“Nulls”区间的特征违约率为0%,同时,在其他所有区间中的违约率为100%。显然,这是泄漏的极端情况。只有当客户违约时,此特征才有价值。基于此特征,可能是因为一个故障,或者因为这个特征在违约者中很常见。了解泄漏特征的问题所在能让你更快地进行调试。

模型监控
由于featexp可计算两个数据集之间的趋势相关性,因此它可以很容易地利用于模型监控。每次我们重新训练模型时,都可以将新的训练数据与测试好的训练数据(通常是第一次构建模型时的训练数据)进行比较。趋势相关性可以帮助你监控特征信息与目标的关系是否发生了变化。
这些简单的步骤总能帮助我在Kaggle或者实际工作中构建更好的模型。用featexp,花15分钟去观察那些图像,是十分有价值的:它会带你一步步看清黑箱里的世界。
原文发布时间为:2018-11-28




