http://www.360doc.com/content/10/1214/22/573136_78188909.shtml
最近朋友推荐的一个很好的工作,又是面了2轮没通过,已经是好几次朋友内推没过了,觉得挺对不住朋友的。面试反馈有一方面是有些方面理解思考的还不够,平时也是项目进度比较紧,有些方面赶进度时没有理解清楚的后面接着做新需求没时间或者给忘了。以后还是得抽时间深入理解学习一些知识了,后面重点是知识深度,多思考。
今天把面试问的较多的HashMap源码看了下,相关知识做了个总结,希望对大家有帮助。如果写的有问题的地方,欢迎讨论。
基本结构:
链表结构:
static class HashMapEntry<K, V> implements Entry<K, V> {
final K key;
V value;
final int hash;
HashMapEntry<K, V> next;
......
}
数组存储所有链表:
transient HashMapEntry<K, V>[] table; //后面tab=table
key的hash值的计算:
int hash = Collections.secondaryHash(key);
table中HashMapEntry位置的计算:
//通过key的hash值获得,因为HashMap数组的大小总是2^n,所以实际的运算就是 (0xfff...ff) & hash ,这里的tab.length-1相当于一个mask,滤掉了大于当前长度位的hash,使每个i都能插入到数组中。
int index = hash & (tab.length - 1);
新增元素:
//放在链表的最前面,next = table[index]
table[index] = new HashMapEntry<K, V>(key, value, hash, table[index]);
取元素:
//找到key的hash对应的HashMapEntry,然后遍历链表,通过key.equals取值
for (HashMapEntry<K, V> e = tab[hash & (tab.length - 1)]; e != null; e = e.next) {
K eKey = e.key;
if (eKey == key || (e.hash == hash && key.equals(eKey))) {
return e.value;
}
}
常见问题:
(其实了解上面的基本知识,下面的很多问题都好理解了)
当两个不同的键对象的hashcode相同时会发生什么?
它们会储存在同一个bucket位置的HashMapEntry组成的链表中。
如果两个键的hashcode相同,你如何获取值对象?
当我们调用get()方法,HashMap会使用键对象的hashcode找到bucket位置,找到bucket位置之后,会调用keys.equals()方法去找到链表中正确的节点。
什么是hash,什么是碰撞,什么是equals ?
Hash:是一种信息摘要算法,它还叫做哈希,或者散列。我们平时使用的MD5,SHA1都属于Hash算法,通过输入key进行Hash计算,就可以获取key的HashCode(),比如我们通过校验MD5来验证文件的完整性。
对于HashCode,它是一个本地方法,实质就是地址取样运算
碰撞:好的Hash算法可以出计算几乎出独一无二的HashCode,如果出现了重复的hashCode,就称作碰撞;
就算是MD5这样优秀的算法也会发生碰撞,即两个不同的key也有可能生成相同的MD5。
HashCode,它是一个本地方法,实质就是地址取样运算;
==是用于比较指针是否在同一个地址;
equals与==是相同的。
如何减少碰撞?
使用不可变的、声明作final的对象,并且采用合适的equals()和hashCode()方法的话,将会减少碰撞的发生,提高效率。不可变性使得能够缓存不同键的hashcode,这将提高整个获取对象的速度,使用String,Interger这样的wrapper类作为键是非常好的选择
如果HashMap的大小超过了负载因子(load factor)定义的容量,怎么办?
默认的负载因子大小为0.75,也就是说,当一个map填满了75%的bucket时候,和其它集合类(如ArrayList等)一样,将会创建原来HashMap大小的两倍的bucket数组,来重新调整map的大小,并将原来的对象放入新的bucket数组中。这个过程叫作rehashing,因为它调用hash方法找到新的bucket位置。

/**
* The default load factor. Note that this implementation ignores the
* load factor, but cannot do away with it entirely because it's
* mentioned in the API.
*
* <p>Note that this constant has no impact on the behavior of the program,
* but it is emitted as part of the serialized form. The load factor of
* .75 is hardwired into the program, which uses cheap shifts in place of
* expensive division.
*/
static final float DEFAULT_LOAD_FACTOR = .75F;
重新调整HashMap大小存在什么问题吗?
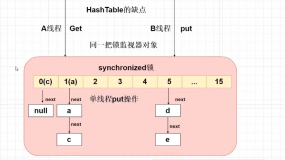
(当多线程的情况下,可能产生条件竞争(race condition))
当重新调整HashMap大小的时候,确实存在条件竞争,因为如果两个线程都发现HashMap需要重新调整大小了,它们会同时试着调整大小。在调整大小的过程中,存储在链表中的元素的次序会反过来,因为移动到新的bucket位置的时候,HashMap并不会将元素放在链表的尾部,而是放在头部,这是为了避免尾部遍历(tail traversing)。如果条件竞争发生了,那么就死循环了。这个时候,你可以质问面试官,为什么这么奇怪,要在多线程的环境下使用HashMap呢?
为什么String, Interger这样的wrapper类适合作为键?
因为String是不可变的,也是final的,而且已经重写了equals()和hashCode()方法了。其他的wrapper类也有这个特点。不可变性是必要的,因为为了要计算hashCode(),就要防止键值改变,如果键值在放入时和获取时返回不同的hashcode的话,那么就不能从HashMap中找到你想要的对象。不可变性还有其他的优点如线程安全。如果你可以仅仅通过将某个field声明成final就能保证hashCode是不变的,那么请这么做吧。因为获取对象的时候要用到equals()和hashCode()方法,那么键对象正确的重写这两个方法是非常重要的。如果两个不相等的对象返回不同的hashcode的话,那么碰撞的几率就会小些,这样就能提高HashMap的性能。
可以使用自定义的对象作为键吗?
当然你可能使用任何对象作为键,只要它遵守了equals()和hashCode()方法的定义规则,并且当对象插入到Map中之后将不会再改变了。如果这个自定义对象时不可变的,那么它已经满足了作为键的条件,因为当它创建之后就已经不能改变了。
可以使用CocurrentHashMap来代替Hashtable吗?
Hashtable是synchronized的,但是ConcurrentHashMap同步性能更好,因为它仅仅根据同步级别对map的一部分进行上锁。ConcurrentHashMap当然可以代替HashTable,但是HashTable提供更强的线程安全性。
能否让HashMap同步?
HashMap可以通过下面的语句进行同步:
Map m = Collections.synchronizeMap(hashMap);
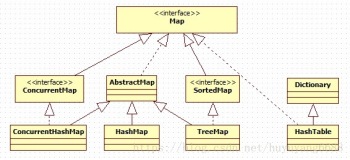
HashMap和Hashtable的区别:
主要的不同:线程安全以及速度。仅在你需要完全的线程安全的时候使用Hashtable,而如果你使用Java 5或以上的话,请使用ConcurrentHashMap吧。
HashMap和Hashtable都实现了Map接口,但决定用哪一个之前先要弄清楚它们之间的分别。主要的区别有:线程安全性,同步(synchronization),以及速度。
HashMap几乎可以等价于Hashtable,除了HashMap是非synchronized的,并可以接受null(HashMap可以接受为null的键值(key)和值(value),而Hashtable则不行)。
HashMap是非synchronized,而Hashtable是synchronized,这意味着Hashtable是线程安全的,多个线程可以共享一个Hashtable;而如果没有正确的同步的话,多个线程是不能共享HashMap的。Java 5提供了ConcurrentHashMap,它是HashTable的替代,比HashTable的扩展性更好。
另一个区别是HashMap的迭代器(Iterator)是fail-fast迭代器,而Hashtable的enumerator迭代器不是fail-fast的。所以当有其它线程改变了HashMap的结构(增加或者移除元素),将会抛出ConcurrentModificationException,但迭代器本身的remove()方法移除元素则不会抛出ConcurrentModificationException异常。但这并不是一个一定发生的行为,要看JVM。这条同样也是Enumeration和Iterator的区别。
由于Hashtable是线程安全的也是synchronized,所以在单线程环境下它比HashMap要慢。如果你不需要同步,只需要单一线程,那么使用HashMap性能要好过Hashtable。
HashMap不能保证随着时间的推移Map中的元素次序是不变的。
要注意的一些重要术语:
1) sychronized意味着在一次仅有一个线程能够更改Hashtable。就是说任何线程要更新Hashtable时要首先获得同步锁,其它线程要等到同步锁被释放之后才能再次获得同步锁更新Hashtable。
2) Fail-safe和iterator迭代器相关。如果某个集合对象创建了Iterator或者ListIterator,然后其它的线程试图“结构上”更改集合对象,将会抛出ConcurrentModificationException异常。但其它线程可以通过set()方法更改集合对象是允许的,因为这并没有从“结构上”更改集合。但是假如已经从结构上进行了更改,再调用set()方法,将会抛出IllegalArgumentException异常。
3) 结构上的更改指的是删除或者插入一个元素,这样会影响到map的结构。
HashMap和HashSet的区别:
什么是HashSet
HashSet实现了Set接口,它不允许集合中有重复的值,当我们提到HashSet时,第一件事情就是在将对象存储在HashSet之前,要先确保对象重写equals()和hashCode()方法,这样才能比较对象的值是否相等,以确保set中没有储存相等的对象。如果我们没有重写这两个方法,将会使用这个方法的默认实现。
public boolean add(Object o)方法用来在Set中添加元素,当元素值重复时则会立即返回false,如果成功添加的话会返回true。
什么是HashMap
HashMap实现了Map接口,Map接口对键值对进行映射。Map中不允许重复的键。Map接口有两个基本的实现,HashMap和TreeMap。TreeMap保存了对象的排列次序,而HashMap则不能。HashMap允许键和值为null。HashMap是非synchronized的,但collection框架提供方法能保证HashMap synchronized,这样多个线程同时访问HashMap时,能保证只有一个线程更改Map。
public Object put(Object Key,Object value)方法用来将元素添加到map中。
HashSet和HashMap的区别
HashMap实现了Map接口 HashSet实现了Set接口
HashMap储存键值对 HashSet仅仅存储对象
使用put()方法将元素放入map中 使用add()方法将元素放入set中
HashMap中使用键对象来计算hashcode值 HashSet使用成员对象来计算hashcode值,对于两个对象来说hashcode可能相同,所以equals()方法用来判断对象的相等性,如果两个对象不同的话,那么返回false
HashMap比较快,因为是使用唯一的键来获取对象 HashSet较HashMap来说比较慢
HashMap的复杂度
HashMap整体上性能都非常不错,但是不稳定,为O(N/Buckets),N就是以数组中没有发生碰撞的元素。
获取 查找 添加/删除 空间
ArrayList O(1) O(1) O(N) O(N)
LinkedList O(N) O(N) O(1) O(N)
HashMap O(N/Bucket_size) O(N/Bucket_size) O(N/Bucket_size) O(N)
注:发生碰撞实际上是非常稀少的,所以N/Bucket_size约等于1
对key进行Hash计算
在JDK8中,由于使用了红黑树来处理大的链表开销,所以hash这边可以更加省力了,只用计算hashCode并移动到低位就可以了
static final int hash(Object key) {
int h;
//计算hashCode,并无符号移动到低位
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
几个常用的哈希码的算法
1:Object类的hashCode.返回对象的内存地址经过处理后的结构,由于每个对象的内存地址都不一样,所以哈希码也不一样。
/**
* Returns an integer hash code for this object. By contract, any two
* objects for which {@link #equals} returns {@code true} must return * the same hash code value. This means that subclasses of {@code Object} * usually override both methods or neither method. * * <p>Note that hash values must not change over time unless information used in equals * comparisons also changes. * * <p>See <a href="{@docRoot}reference/java/lang/Object.html#writing_hashCode">Writing a correct * {@code hashCode} method</a> * if you intend implementing your own {@code hashCode} method. * * @return this object's hash code. * @see #equals */ public int hashCode() { int lockWord = shadow$_monitor_; final int lockWordMask = 0xC0000000; // Top 2 bits. final int lockWordStateHash = 0x80000000; // Top 2 bits are value 2 (kStateHash). if ((lockWord & lockWordMask) == lockWordStateHash) { return lockWord & ~lockWordMask; } return System.identityHashCode(this); }
2:String类的hashCode.根据String类包含的字符串的内容,根据一种特殊算法返回哈希码,只要字符串所在的堆空间相同,返回的哈希码也相同。
@Override
public int hashCode() {
int hash = hashCode;
if (hash == 0) { if (count == 0) { return 0; } final int end = count + offset; final char[] chars = value; for (int i = offset; i < end; ++i) { hash = 31*hash + chars[i]; } hashCode = hash; } return hash; }
3:Integer类,返回的哈希码就是Integer对象里所包含的那个整数的数值,例如Integer i1=new Integer(100),i1.hashCode的值就是100 。由此可见,2个一样大小的Integer对象,返回的哈希码也一样。
public int hashCode() {
return value;
}
int,char这样的基础类,它们不需要hashCode.
插入包装类到数组
(1). 如果输入当前的位置是空的,就插进去,如图,左为插入前,右为插入后
0 0
| |
1 -> null 1 - > null
| |
2 -> null 2 - > null
| |
..-> null ..- > null
| |
i -> null i - > new node
| |
n -> null n - > null
(2). 如果当前位置已经有了node,且它们发生了碰撞,则新的放到前面,旧的放到后面,这叫做链地址法处理冲突。
0 0
| |
1 -> null 1 - > null
| |
2 -> null 2 - > null
| |
..-> null ..- > null
| |
i -> old i - > new - > old
| |
n -> null n - > null
我们可以发现,失败的hashCode算法会导致HashMap的性能下降为链表,所以想要避免发生碰撞,就要提高hashCode结果的均匀性。当然,在JDK8中,采用了红黑二叉树进行了处理,这个我们后面详细介绍。
什么是Hash攻击?
通过请求大量key不同,但是hashCode相同的数据,让HashMap不断发生碰撞,硬生生的变成了SingleLinkedList
0
|
1 -> a ->b -> c -> d(撞!撞!撞!复杂度由O(1)变成了O(N))
|
2 -> null(本应该均匀分布,这里却是空的)
|
3 -> null
|
4 -> null
这样put/get性能就从O(1)变成了O(N),CPU负载呈直线上升,形成了放大版DDOS的效果,这种方式就叫做hash攻击。在Java8中通过使用TreeMap,提升了处理性能,可以一定程度的防御Hash攻击。
扩容
如果当表中的75%已经被占用,即视为需要扩容了
初始容量:
if (capacity < MINIMUM_CAPACITY) {
capacity = MINIMUM_CAPACITY;
} else if (capacity > MAXIMUM_CAPACITY) { capacity = MAXIMUM_CAPACITY; } else { capacity = Collections.roundUpToPowerOfTwo(capacity); }
public static int roundUpToPowerOfTwo(int i) {
i--; // If input is a power of two, shift its high-order bit right. // "Smear" the high-order bit all the way to the right. i |= i >>> 1; i |= i >>> 2; i |= i >>> 4; i |= i >>> 8; i |= i >>> 16; return i + 1; }
(threshold = capacity * load factor ) < size
它主要有两个步骤:
1. 容量加倍
左移N位,就是2^n,用位运算取代了乘法运算
newCap = oldCap << 1;
newThr = oldThr << 1;
2. 遍历计算Hash
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
//如果发现当前有Bucket if ((e = oldTab[j]) != null) { oldTab[j] = null; //如果这里没有碰撞 if (e.next == null) //重新计算Hash,分配位置 newTab[e.hash & (newCap - 1)] = e; //这个见下面的新特性介绍,如果是树,就填入树 else if (e instanceof TreeNode) ((TreeNode<K,V>)e).split(this, newTab, j, oldCap); //如果是链表,就保留顺序....目前就看懂这点 else { // preserve order Node<K,V> loHead = null, loTail = null; Node<K,V> hiHead = null, hiTail = null; Node<K,V> next; do { next = e.next; if ((e.hash & oldCap) == 0) { if (loTail == null) loHead = e; else loTail.next = e; loTail = e; } else { if (hiTail == null) hiHead = e; else hiTail.next = e; hiTail = e; } } while ((e = next) != null); if (loTail != null) { loTail.next = null; newTab[j] = loHead; } if (hiTail != null) { hiTail.next = null; newTab[j + oldCap] = hiHead; } } } }
由此可以看出扩容需要遍历并重新赋值,成本非常高,所以选择一个好的初始容量非常重要。
如何提升性能?
解决扩容损失:如果知道大致需要的容量,把初始容量设置好以解决扩容损失;
比如我现在有1000个数据,需要 1000/0.75 = 1333 ,又 1024 < 1333 < 2048,所以最好使用2048作为初始容量。
2048=Collections.roundUpToPowerOfTwo(1333)
解决碰撞损失:使用高效的HashCode与loadFactor,这个...由于JDK8的高性能出现,这儿问题也不大了。
解决数据结构选择的错误:在大型的数据与搜索中考虑使用别的结构比如TreeMap,这个就是积累了;
JDK8中HashMap的新特性
如果某个桶中的链表记录过大的话(当前是TREEIFY_THRESHOLD = 8),就会把这个链动态变成红黑二叉树,使查询最差复杂度由O(N)变成了O(logN)。
//e 为临时变量,p为当前的链
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
在Android中使用SparseArray代替HashMap
官方推荐使用SparseArray([spɑ:s] [ə'reɪ],稀疏的数组)或者LongSparseArray代替HashMap,目前国内好像涉及的比较少,容我先粘贴一段
Note that this container keeps its mappings in an array data structure, using a binary search to find keys. The implementation is not intended to be appropriate for data structures that may contain large numbers of items. It is generally slower than a traditional HashMap, since lookups require a binary search and adds and removes require inserting and deleting entries in the array.
For containers holding up to hundreds of items, the performance difference is not significant, less than 50%.
To help with performance, the container includes an optimization when removing keys: instead of compacting its array immediately, it leaves the removed entry marked as deleted. The entry can then be re-used for the same key, or compacted later in a single garbage collection step of all removed entries. This garbage collection will need to be performed at any time the array needs to be grown or the the map size or entry values are retrieved.
总的来说就是:
SparseArray使用基本类型(Primitive)中的int作为Key,不需要Pair<K,V>或者Entry<K,V>这样的包装类,节约了内存;
SpareAraay维护的是一个排序好的数组,使用二分查找数据,即O(log(N)),每次插入数据都要进行排序,同样耗时O(N);而HashMap使用hashCode来加入/查找/删除数据,即O(N/buckets_size);
总的来说,就是SparseArray针对Android嵌入式设备进行了优化,牺牲了微小的时间性能,换取了更大的内存优化;同时它还有别的优化,比如对删除操作做了优化;
如果你的数据非常少(实际上也是如此),那么使用SpareArray也是不错的;
重要结构及方法:
static class HashMapEntry<K, V> implements Entry<K, V> {
final K key;
V value;
final int hash;
HashMapEntry<K, V> next; //链表
......
}
/**
* The table is rehashed when its size exceeds this threshold.
* The value of this field is generally .75 * capacity, except when
* the capacity is zero, as described in the EMPTY_TABLE declaration
* above.
*/
private transient int threshold;
/**
* Maps the specified key to the specified value.
*
* @param key
* the key.
* @param value
* the value.
* @return the value of any previous mapping with the specified key or
* {@code null} if there was no such mapping.
*/
public V put(K key, V value) {
if (key == null) {
return putValueForNullKey(value);
}
//二次hash,目的是为了让所有的位数都来参加hash,防止冲突
int hash = Collections.secondaryHash(key);
HashMapEntry<K, V>[] tab = table;
//位置的获得,tab.length-1与任何数相与都小于length
int index = hash & (tab.length - 1);
for (HashMapEntry<K, V> e = tab[index]; e != null; e = e.next) {
//遍历index处的链表
if (e.hash == hash && key.equals(e.key)) {
//替换并返回旧的value
preModify(e);
V oldValue = e.value;
e.value = value;
return oldValue;
}
}
// No entry for (non-null) key is present; create one
modCount++;
if (size++ > threshold) {
//检查容量
tab = doubleCapacity();
index = hash & (tab.length - 1);
}
//添加新的value,放在链表的最前面,next = table[index]
table[index] = new HashMapEntry<K, V>(key, value, hash, table[index]);
return null;
}
/**
* Returns the value of the mapping with the specified key.
*
* @param key
* the key.
* @return the value of the mapping with the specified key, or {@code null}
* if no mapping for the specified key is found.
*/
public V get(Object key) {
if (key == null) {
HashMapEntry<K, V> e = entryForNullKey;
return e == null ? null : e.value;
}
int hash = Collections.secondaryHash(key);
HashMapEntry<K, V>[] tab = table;
//找到hash对应的HashMapEntry,然后遍历链表,通过key.equals取值
for (HashMapEntry<K, V> e = tab[hash & (tab.length - 1)];
e != null; e = e.next) {
K eKey = e.key;
if (eKey == key || (e.hash == hash && key.equals(eKey))) {
return e.value;
}
}
return null;
}
/**
* Doubles the capacity of the hash table. Existing entries are placed in
* the correct bucket on the enlarged table. If the current capacity is,
* MAXIMUM_CAPACITY, this method is a no-op. Returns the table, which
* will be new unless we were already at MAXIMUM_CAPACITY.
*/
private HashMapEntry<K, V>[] doubleCapacity() {
//size++ > threshold时调用
HashMapEntry<K, V>[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
return oldTable;
}
int newCapacity = oldCapacity * 2;
HashMapEntry<K, V>[] newTable = makeTable(newCapacity);
if (size == 0) {
return newTable;
}
for (int j = 0; j < oldCapacity; j++) {
/*
* Rehash the bucket using the minimum number of field writes.
* This is the most subtle and delicate code in the class.
*/
HashMapEntry<K, V> e = oldTable[j];
if (e == null) {
continue;
}
int highBit = e.hash & oldCapacity;
HashMapEntry<K, V> broken = null;
newTable[j | highBit] = e;
for (HashMapEntry<K, V> n = e.next; n != null; e = n, n = n.next) {
int nextHighBit = n.hash & oldCapacity;
if (nextHighBit != highBit) {
if (broken == null)
newTable[j | nextHighBit] = n;
else
broken.next = n;
broken = e;
highBit = nextHighBit;
}
}
if (broken != null)
broken.next = null;
}
return newTable;
}
http://www.cnblogs.com/John-Chen/p/4375046.html