
上篇讲述了从redis单机架构到主从模式的演进,怎么一步一步降低服务的不可用时间,没有看过建议先看上篇从高可用看redis的改革与创新。上篇讲述的架构还存在问题,服务的不可用时间=人工发现故障所需的时间,这个时间往往是不可控的,所以我们今天就来讲一下,redis主节点发生故障的时候,怎么进行自动切换,进一步缩短服务的不可用时间。
我们想一下,需要完成从库自动切换成主库,我们需要做些什么?
- 发现主库不行了,怎么发现?
- 选择某一个从库作为主库,怎么选择?
- 通知其他从库和客户端主库发生了改变,怎么通知?
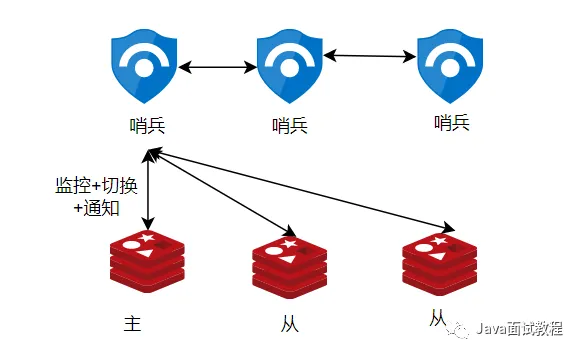
一.哨兵模式
哨兵模式下,哨兵是独立的进程,有多个组成,至少是3个,通常是奇数个,每个哨兵都监控着redis节点。
配置哨兵时,只需要配置主库的 IP 和端口
哨兵之前相互发现:哨兵通过跟主库pub/sub命令,发现其他哨兵的存在,这样哨兵之间就可以建立连接,相互通信了。
哨兵发现从库:哨兵通过向主库发送info命令,就可以获取到salve列表,跟从库建立连接。
哨兵通知客户端发送了主从切换:客户端跟哨兵发送订阅命令,订阅哨兵的主从切换的各自事件,来得知主库是否发生了改变。
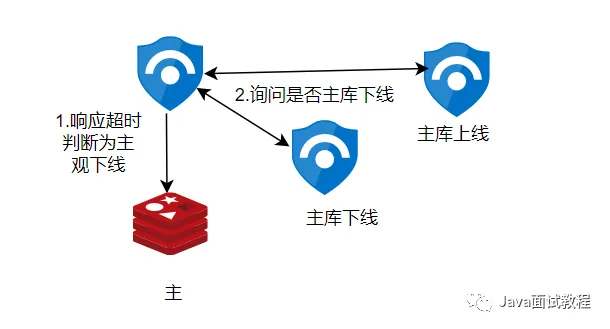
怎么发现,发现主库不行了
1.主观下线:哨兵会不断的发送ping命令给redis节点,redis节点响应超时了,哨兵就会把节点标识为主观下线,如果是从库,标识完就可以了;如果是主库,还需要把下线的信息同步给其他哨兵,进一步判断是否可以进行主从切换。
2.客观下线:其他哨兵收到( is-master-down by-addr )主库下线的命令,会根据自身的对主库的监控,来判断是否主库下线了,回复是否下线,一般有n/2+1个节点(这个可以配置)认为主库主观下线了,才能判断主库为客观下线,这时候才能进行主从切换操作。
如图所示:有三个哨兵组成的集群,有两个哨兵认为主库下线了,就可以判断为主库为客观下线了。
怎么选择某一个从库作为主库
先按照一定规则,把不满足升级为主库的筛选掉;然后再按照规则排序,优先级高的选为主库。
筛选:先把与主库连接网络不好的从节点,从库是否和主库断开连接的时间超过了10次, down-after-milliseconds配置值,就可以过滤掉。
排序:
- 选取配置slave-priority 的从节点最高的为主库
- 与旧主库同步最接近的从节点为主库,对比slave_repl_offset大小
- run ID最小的从节点为主库
哪个哨兵来执行主从切换操作:
Leader 选举:需要满足拿到半数以上的票,而且拿到的票需要大于等于 quorum 值才能成为leader。在一轮投票中,每个哨兵只能投一次,投了就不能再投了,防止重复投票,所以在发起投票时,会携带一个配置纪元(configuration epoch),说明投票的版本,每次重新发起投票都会递增。目标哨兵回复时会带上leader_runid参数和leader_epoch参数,源哨兵会判断是否跟自身一致,如果相同代表目标哨兵同意。
选完Leader 就能进行主从切换了。
怎么通知其他从库和客户端主库发生了改变
从库和客户端都会对哨兵进行订阅主从切换的频道,当哨兵完成主从切换后,就会向频道发出切换消息,从库和客户端就知道主库发送变化,跟主库建立新的连接。
二.集群模式
集群模式跟主从模式不太一样,主从模式下的只有一个主节点,所以主节点和从节点都保存了全部数据。集群模式下是有多个主节点的,每个主节点存储一部分数据,所有主节点加起来的数据等于全部数据。
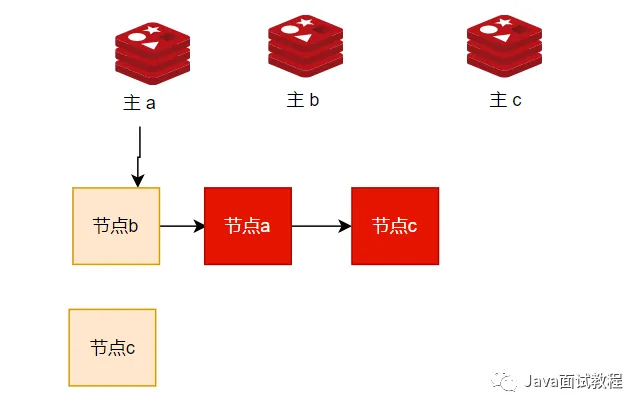
怎么发现,发现主库不行了
主节点之间会相互发送ping,如果超过时间没有收到响应,主节点就会把接收ping的节点判断为疑似下线。主节点之间会相互发送疑似下线节点的信息,主节点会存放起来,当某个主节点有n/2+1都判定为疑似下线。主节点就会向集群广播发出Fail消息给所有的节点。
下图:主节点a,保存的主节点b信息有两个节点都认为b节点为疑似下线,满足n/2+1的条件,主节点就发出fail命令给所有的节点。
怎么选择某一个从库作为主库
所有从节点都收到fail命令,当从节点发现是自己的主节点出现了故障,从节点就会向其他主节点发送CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST消息,每个主节点在一次配置纪元有一次投票机会,当有大于等于N/2+1个节点的票数时,就代表可以成为主节点了。这个跟哨兵选取leader是一样的。
新主节点后的动作:
- 新主节点会执行SLAVEOF no one命令,代表成为新的主节点
- 把旧主节点负责的槽,指派给自己
- 给其他节点发送pong命令,让其他节点知道它成为了主节点并且负责了旧主节点的槽
怎么通知其他从库和客户端主库发生了改变
通知其他从库:上一步选出主库后,新的主库会发出pong命令完成从库的通知。
通知客户端:这个不需要通知,当客户端根据key访问槽时,如果当前槽不是所在节点负责的,就会发送move命令给客户端,告知客户端槽的正确节点在哪,客户端就会重新发起请求处理。由于所有的节点都知道新的主节点所负责的槽,所以可以路由到新的主节点。
三. 总结
讲解了哨兵模式和集群模式的自动主从切换原理,从怎么发现主库不可用,怎么选出新的主库,怎么通知新的主库变化的角度来说明 。选取哨兵比较适合数据量不太的场景,集群模式比较适合数据量大的场景。
此时服务的不可用时间=程序的自动切换时间,不需要依赖人工切换了,不可用时间已经是大大降低了,符合我们生产对高可用的要求了。




