
Problem:
Why I only change “shuffle=False” to “shuffle=True” in my DataLoader when I test my model, my test result will be different so much?
Solve:
这个问题现在看来挺脑残的...唉,排查了老久...其实很简单,就是因为pytorch新手入门,很多东西没学好,在测试的时候没有先进行model.eval():
Do need to use model.eval() when I test?
1. Sure, Dropout works as a regularization for preventing overfitting during training. 2. It randomly zeros the elements of inputs in Dropout layer on forward call. 3. It should be disabled during testing since you may want to use full model (no element is masked)
用 model.eval(),让model变成测试模式,这主要是对dropout和batch normalization的操作在训练和测试的时候是不一样的:
Batch Normalization 和 Dropout
- 训练时是正对每个min-batch的,但是在测试中往往是针对单张图片,即不存在min-batch的概念。由于网络训练完毕后参数都是固定的,因此每个批次的均值和方差都是不变的,因此直接结算所有batch的均值和方差。所有Batch Normalization的训练和测试时的操作不同
- 在训练中,每个隐层的神经元先乘概率P,然后在进行激活,在测试中,所有的神经元先进行激活,然后每个隐层神经元的输出乘P。
Extension:
Batch Normalization
BN主要时对网络中间的每层进行归一化处理,并且使用变换重构(Batch Normalizing Transform)保证每层所提取的特征分布不会被破坏,详细参见Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift。该算法主要如下:

训练时是正对每个min-batch的,但是在测试中往往是针对单张图片,即不存在min-batch的概念。由于网络训练完毕后参数都是固定的,因此每个批次的均值和方差都是不变的,因此直接结算所有batch的均值和方差。所有Batch Normalization的训练和测试时的操作不同
Dropout
Dropout能够克服Overfitting,在每个训练批次中,通过忽略一半的特征检测器,可以明显的减少过拟合现象,详细见文章:Dropout: A Simple Way to Prevent Neural Networks from Overtting具体如下所示:
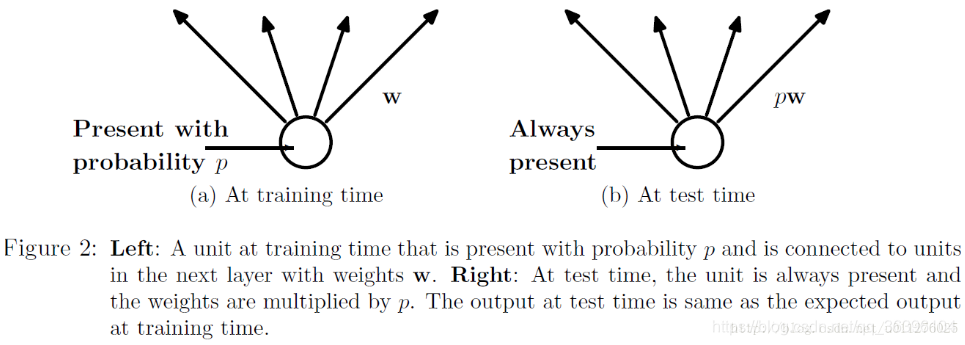
在训练中,每个隐层的神经元先乘概率P,然后在进行激活,在测试中,所有的神经元先进行激活,然后每个隐层神经元的输出乘P。
###模型的保存和加载
模型的保存和加载有两种方式:
(1) 仅仅保存和加载模型参数
1. torch.save(the_model.state_dict(), PATH) 2. 3. the_model = TheModelClass(*args, **kwargs) 4. the_model.load_state_dict(torch.load(PATH))
(2) 保存和加载整个模型
1. torch.save(the_model, PATH) 2. 3. the_model = torch.load(PATH)
第一种方式需要自己定义网络,并且其中的参数名称与结构要与保存的模型中的一致(可以是部分网络,比如只使用VGG的前几层),相对灵活,便于对网络进行修改。第二种方式则无需自定义网络,保存时已把网络结构保存,比较死板,不能调整网络结构。
pytorch使用注意:
- 当网络中有 dropout,bn 的时候。训练的要记得 net.train(), 测试 要记得 net.eval()
- 在测试的时候 创建输入 Variable 的时候 要记得 volatile=True
- torch.sum(Tensor), torch.mean(Tensor) 返回的是 python 浮点数,不是 Tensor。
- 在不需要 bp 的地方用 Tensor 运算。
参考:
PyTorch(七)——模型的训练和测试、保存和加载_hudongloop的博客-CSDN博客
pytorch学习笔记(十六):pytorch 写代码时应该注意_u012436149的博客-CSDN博客
Pytorch的net.train 和 net.eval的使用_Never-Giveup的博客-CSDN博客_net.eval
带你跨过神经网络训练常见的37个坑_语言 & 开发_Slav Ivanov_InfoQ精选文章
AIEarth是一个由众多领域内专家博主共同打造的学术平台,旨在建设一个拥抱智慧未来的学术殿堂!【平台地址:https://devpress.csdn.net/aiearth】 很高兴认识你!加入我们共同进步!





