0x00 前言
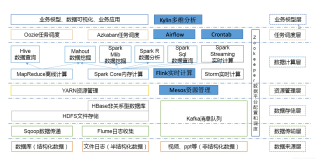
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。

▲ Hadoop生态系统
0x01 环境说明
| Xshell 7 |
| Hadoop-3.3.3 |
| jdk-18_linux-x64_bin |
| centos-a(192.168.1.10) |
| centos-b(192.168.1.11) |
| centos-c(192.168.1.12) |
0x02 准备工作
文中使用CentOS-7系统在三个虚拟机环境下进行示范,过程使用本地主机与虚拟机交互。首先要在Windows主机下载实验过程需要使用的环境。
ⅠXshell 7:
https://www.xshell.com/zh/xshell-download/
ⅡHadoop-3.3.3:
https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/stable/hadoop-3.3.3.tar.gz
Ⅲjdk-18_linux-x64_bin:
https://download.oracle.com/java/18/latest/jdk-18_linux-x64_bin.tar.gz
0x03 配置hosts文件(三个节点)
Ⅰ通过root执行命令
su root
Ⅱ配置虚拟机hosts文件
vi /etc/hosts
Ⅲ写入各个节点IP和主机名
192.168.1.10 centos-a 192.168.1.11 centos-b 192.168.1.12 centos-c
Ⅳ分别检测三个节点是否互联
ping-c3 centos-x
0x04 SSH免密登录(三个节点)
SSH为建立在应用层基础上的安全协议。SSH是较可靠,专为远程登录会话和其他网络服务提供安全性的协议。
Ⅰ生成密钥文件
ssh-keygen -t rsa -P''
Ⅱ在.ssh目录中生成authorized_keys文件(仅在主节点执行)
touch /root/.ssh/authorized_keys
Ⅲ通过SSH复制三个节点生成的id信息
ssh-copy-id centos-a ssh-copy-id centos-b ssh-copy-id cnetos-c
Ⅳ查看密钥文件是否成功配置
cat /root/.ssh/authorized_keys
Ⅴ验证免密登录是否成功
ssh centos-b
0x05 Xshell7连接虚拟机(三个节点)
Xshell7可以在Windows界面下用来访问远端不同系统下的服务器,从而比较好的达到远程控制终端的目的。

▲ Ⅰ打开Xshell7选择新建

▲ Ⅱ修改常规项并连接虚拟机

▲ Ⅲ接受并保存

▲ Ⅳ输入主机名并确定

▲ Ⅴ输入虚拟机密码并确定

▲ Ⅵ虚拟机连接成功
0x06 Xshell7文件上传(三个节点)
Ⅰ通过root执行命令
su root
Ⅱ创建software文件夹

mkdir /usr/local/software
Ⅲ下载文件互传工具

yum -y install lrzsz
Ⅳ打开software文件夹

cd /usr/local/software
Ⅴ利用lrzsz文件互传工具

rz
Ⅵ上传jdk-18_linux-x64_bin文件

Ⅶ上传Hadoop-3.3.3文件

0x07 安装JDK(三个节点)
Ⅰ创建jdk文件夹以保存解压的jdk文件
mkdir /usr/local/jdk
Ⅱ解压jdk文件
tar -zxvf jdk-18_linux-x64_bin.tar.gz -C /usr/local/jdk
Ⅲ打开profile文件
vi /etc/profile
Ⅳ配置jdk环境变量
#--在末尾写入配置文件--exportJAVA_HOME=/usr/local/jdk/jdk-18.0.2 exportPATH=$PATH:$JAVA_HOME/bin exportCLASSPATH=$CLASSPATH:$JAVA_HOME/lib/
Ⅴ使配置文件生效
source /etc/profile
0x08 安装Hadoop(三个节点)
Ⅰ创建hadoop文件夹以保存解压的hadoop文件
mkdir /usr/local/hadoop
Ⅱ解压hadoop文件
tar -zxvf hadoop-3.3.3.tar.gz -C /usr/local/hadoop
Ⅲ打开profile文件
vi /etc/profile
Ⅳ配置hadoop环境变量
exportHADOOP_HOME=/usr/local/hadoop/hadoop-3.3.3 exportPATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATHexportHDFS_NAMENODE_USER=root exportHDFS_DATANODE_USER=root exportHDFS_SECONDARYNAMENODE_USER=root exportYARN_RESOURCEMANAGER_USER=root exportYARN_NODEMANAGER_USER=root
Ⅴ使配置文件生效
source /etc/profile
0x09 配置Hadoop文件(仅在主节点执行)
Ⅰ打开hadoop-env.sh文件
vi /usr/local/hadoop/hadoop-3.3.3/etc/hadoop/hadoop-env.sh
修改hadoop-env.sh文件
JAVA_HOME=/usr/local/jdk/jdk-18.0.2
Ⅱ打开core-site.xml文件
vi /usr/local/hadoop/hadoop-3.3.3/etc/hadoop/core-site.xml
修改core-site.xml文件
#在configuration标签中加入<!-- HDFS临时目录 --> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/hadoop/hadoop-3.3.3/tmp</value> <description>Abase for other temporary directories.</description> </property> <!-- HDFS的默认地址、端口 访问地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://centos-a:9000</value> </property>
Ⅲ打开yarn-site.xml文件
vi /usr/local/hadoop/hadoop-3.3.3/etc/hadoop/yarn-site.xml
修改yarn-site.xml文件
#在configuration标签中加入<!-- 集群master --> <property> <name>yarn.resourcemanager.hostname</name> <value>centos-a</value> </property> <!-- NodeManager上运行的附属服务 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 容器可能会覆盖的环境变量,而不是使用NodeManager的默认值 --> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ</value> </property> <!-- 关闭内存检测,在虚拟机中不做配置会报错 --> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property>
Ⅳ打开mapred-site.xml文件
vi /usr/local/hadoop/hadoop-3.3.3/etc/hadoop/mapred-site.xml
修改mapred-site.xml文件
#在configuration标签中加入<!-- yarn表示新的框架,local表示本地运行,classic表示经典mapreduce框架 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!-- 如果mapreduce任务访问本地库(压缩等),则必须保留原始值,当此值为空时,设置执行环境的命令将取决于操作系统 --> <property> <name>mapreduce.admin.user.env</name> <value>HADOOP_MAPRED_HOME=/usr/local/hadoop/hadoop-3.3.3</value> </property> <!-- 设置AM[AppMaster]端的环境变量 --> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=/usr/local/hadoop/hadoop-3.3.3</value> </property>
Ⅴ打开hdfs-site.xml文件
vi /usr/local/hadoop/hadoop-3.3.3/etc/hadoop/hdfs-site.xml
修改hdfs-site.xml文件
#在configuration标签中加入<!-- hdfs web的地址 --> <property> <name>dfs.namenode.http-address</name> <value>centos-a:50070</value> </property> <!-- 副本数 --> <property> <name>dfs.replication</name> <value>3</value> </property> <!-- 是否启用hdfs权限 --> <property> <name>dfs.permissions.enabled</name> <value>false</value> </property> <!-- 块大小,默认128M --> <property> <name>dfs.blocksize</name> <value>134217728</value> </property>
Ⅵ打开works文件
vi /usr/local/hadoop/hadoop-3.3.3/etc/hadoop/workers
修改works文件
centos-a #--主节点--centos-b #--从节点--centos-c #--从节点--
Ⅶ将centos-a主机节点配置好的文件发送给centos-b和centos-c
scp -r /usr/local/hadoop/hadoop-3.3.3 centos-b://usr/local/hadoop/ scp -r /usr/local/hadoop/hadoop-3.3.3 centos-c://usr/local/hadoop/
0x10 启动Hadoop(仅在主节点执行)
Ⅰhadoop启动前必须要格式化
hadoop namenode -format
Ⅱ启动hadoop,启动文件位于sbin目录
start-all.sh #--启动--stop-all.sh #--停用--
Ⅲ浏览器访问hadoop的web界面

192.168.1.10:50070
0x11 总结
至此Hadoop部署完成。由于作者水平有限,文中若有错误与不足欢迎留言,便于及时更正。