AWS Data Pipeline是AWS提供的一项用于在不同计算和存储服务之间大规模传输、转换和处理数据的Web服务。利用AWS Data Pipeline,用户在不用关心计算存储网络等资源的情况下轻松创建出高可用的复杂数据处理任务,可以定期地读取并处理用户存储在AWS上的数据,最终高效地将计算结果传输到各种AWS服务中。借助AWS Data Pipeline,用户不用关系任务间的依赖关系、任务的故障或者超时重试以及在出错时的故障通知系统等问题,并且可以传输和处理之本地数据孤岛中锁定的数据。
AWS Data Pipeline支持的数据输入和输出位置包括Amazon DynamoDB、Amazon Redshift、Amazon S3以及SQL数据表,其中SQL数据表不仅可以是Amazon的RDS数据库,还支持JDBC协议的各种数据库。Data Pipeline支持的数据活动包括复制活动、SQL查询活动、Hive查询活动、在 Amazon EMR 集群上运行 Pig 脚本以及运行自定义 UNIX/Linux shell 命令。
本文以一个导出DynamoDB数据到S3的示例来介绍一下AWS Data Pipeline的使用和常用功能。
准备工作
创建一个DynamoDB表
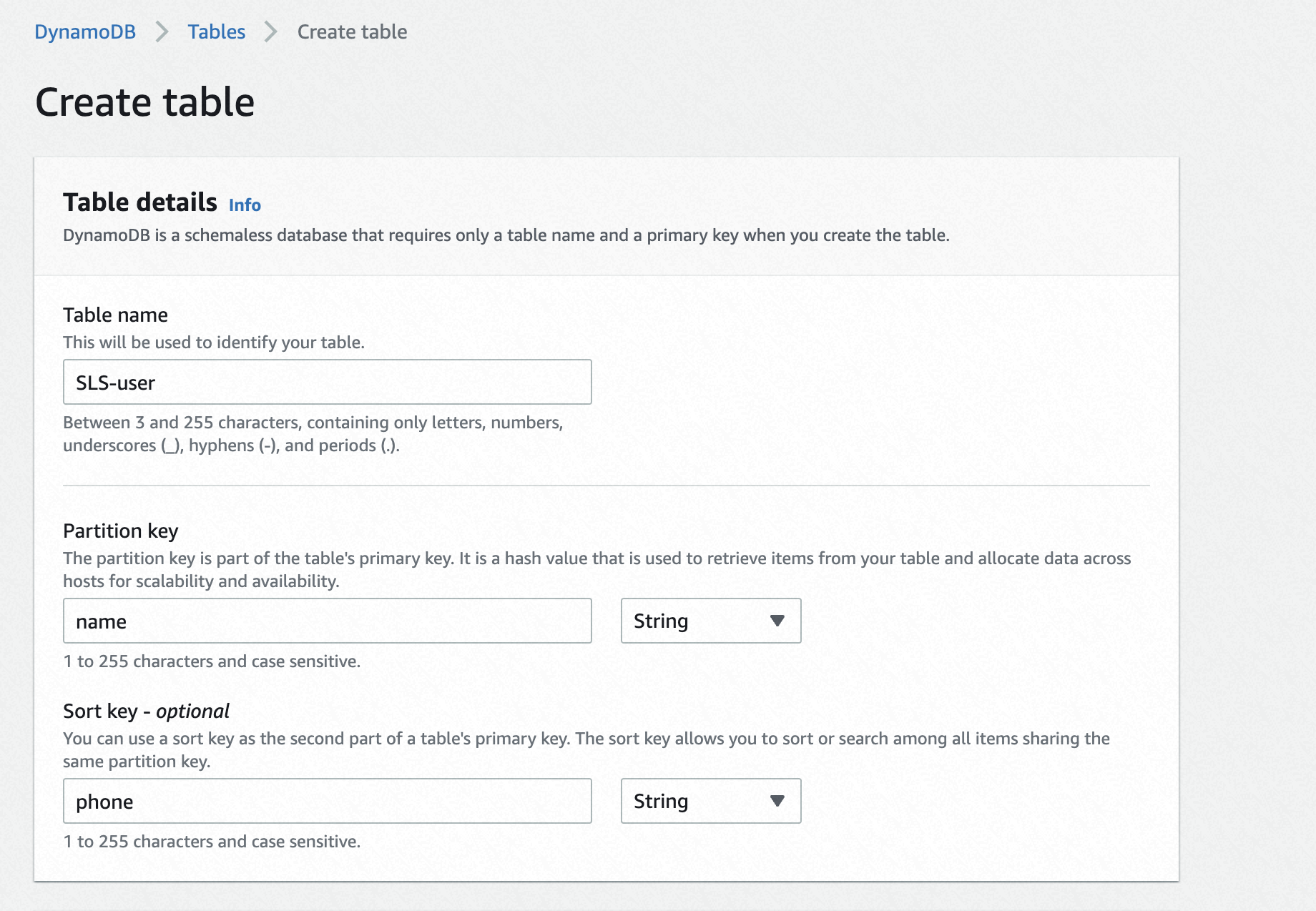
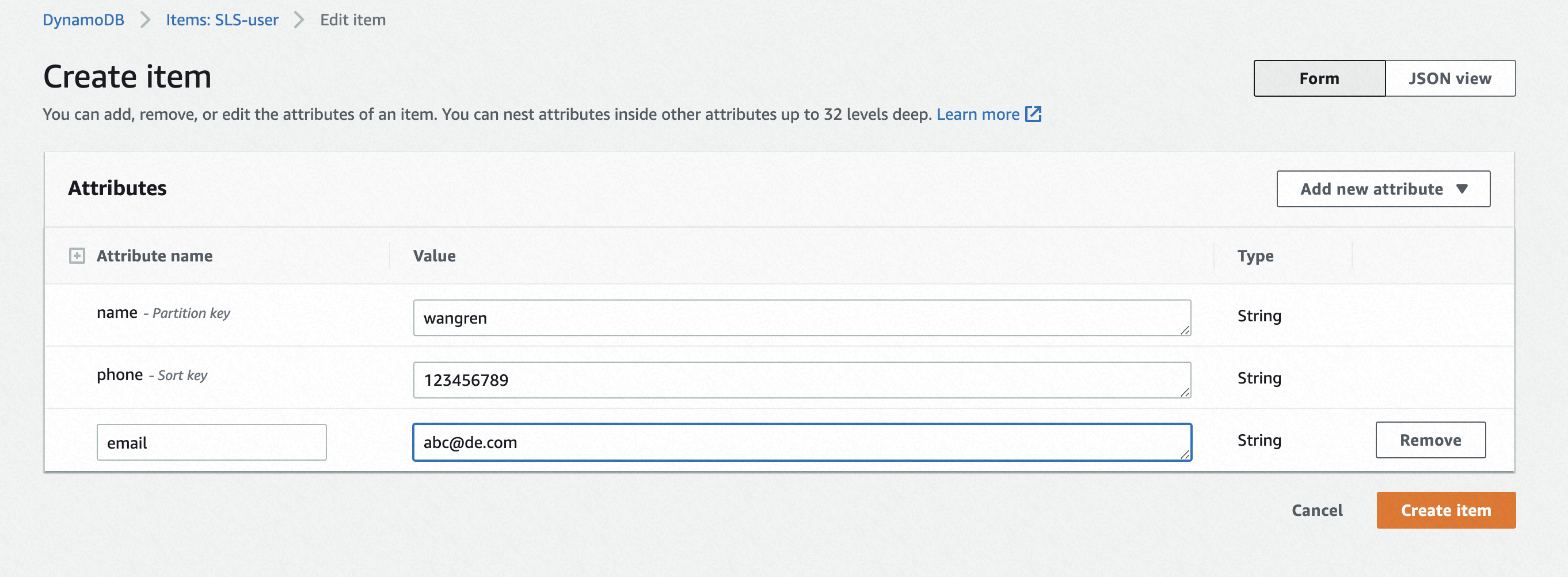
创建一个名为SLS-user的DynamoDB表,并给其中写入一些数据。
创建IAM的策略和角色
为了将DynamoDB中的数据传输到S3中,还需创建两个IAM角色和需要的策略。
- 在IAM创建角色的页面,搜索Data Pipeline,选择Data Pipeline,创建一个名为sls-data的角色。

- 在IAM创建角色的页面,选择EC2,在下一步添加权限的时候搜索AmazonEC2RoleforDataPipelineRole,选中后创建一个名为sls-ec2-role的角色。
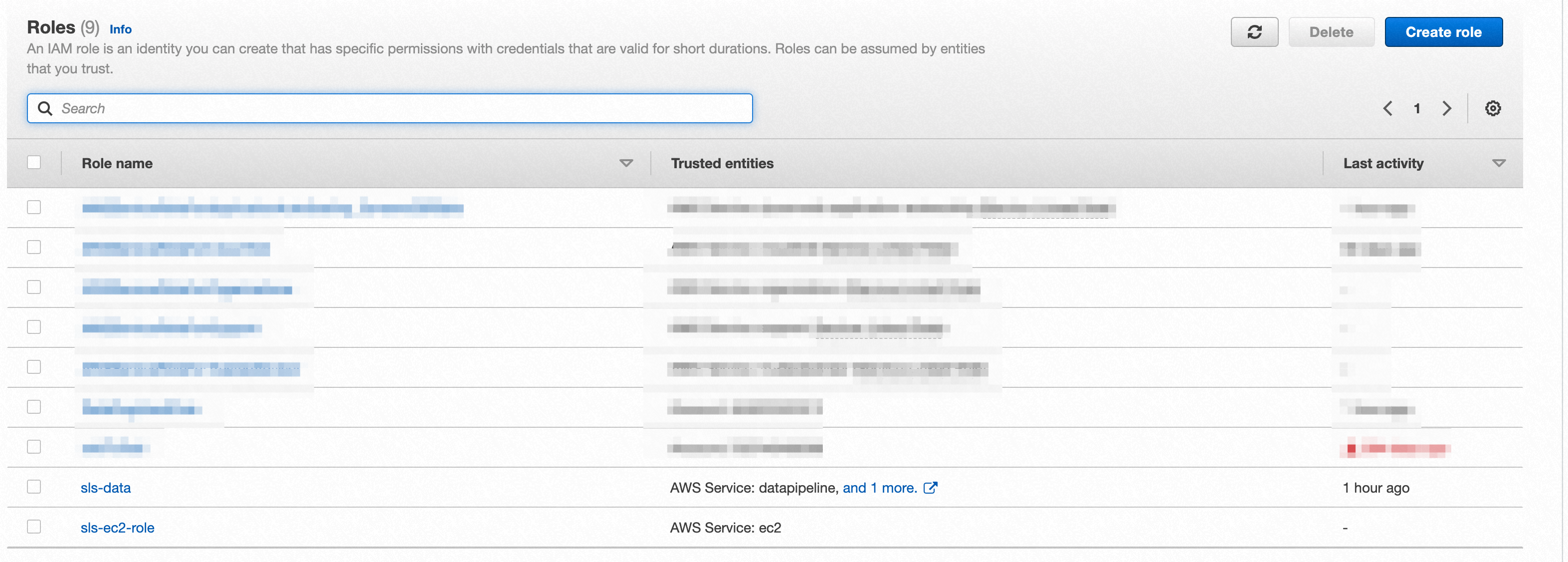
- 在EC2控制台上,选中EC2实例,在Actions->Security->Modify IAM role中选择sls-ec2-role这个角色。
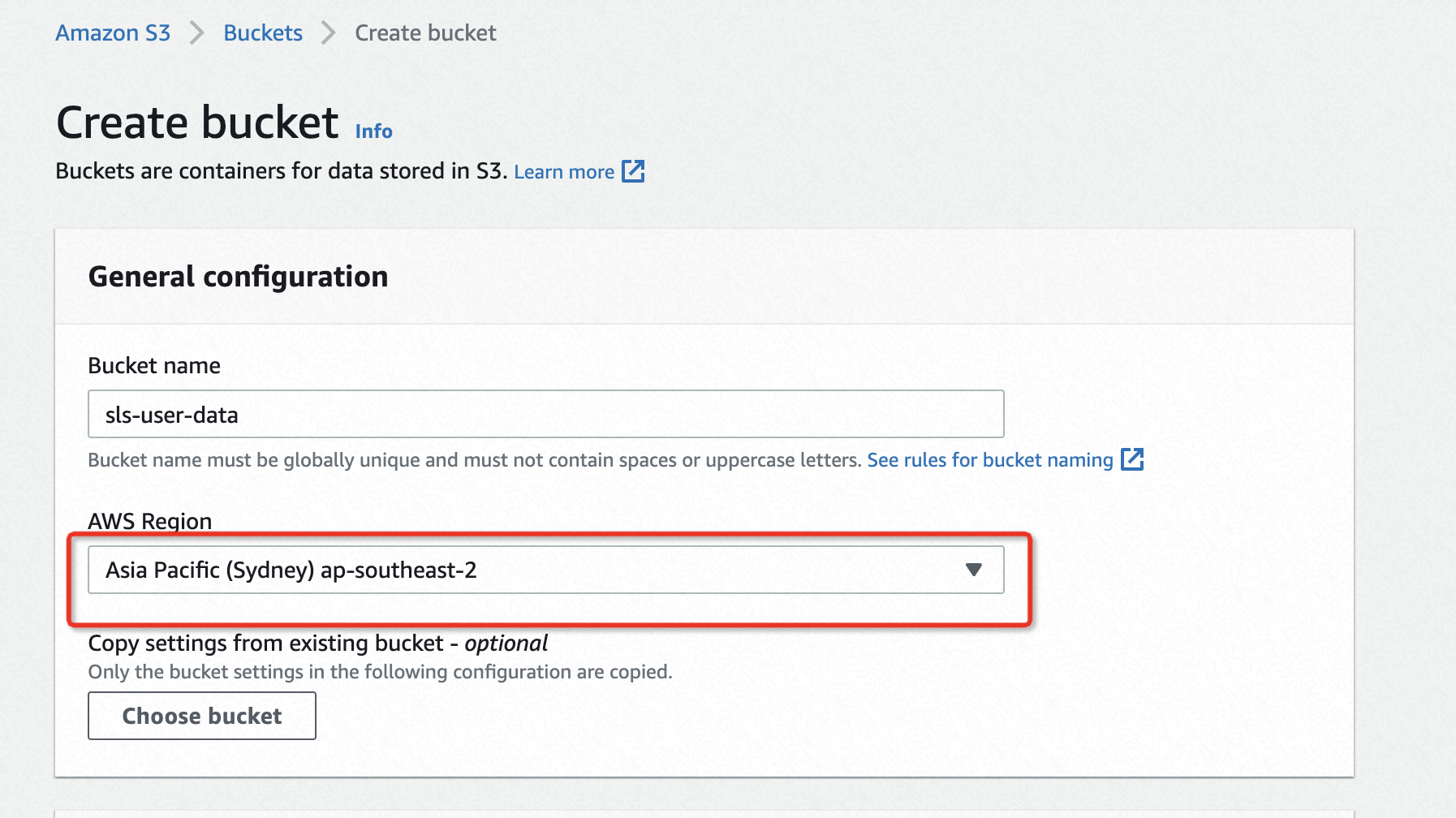
创建一个S3 Bucket
选择跟DynamoDB相同的Region,取消勾选Block all public access,其余保持默认。
给上面创建的Bucket添加下面的访问策略,注意替换123456789为您的账户ID,以及角色名称和Bucket的ARN也需要替换为正确的名称。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "PublicReadGetObject",
"Effect": "Allow",
"Principal": {
"AWS": [
"arn:aws:iam::123456789:role/sls-data",
"arn:aws:iam::123456789:role/sls-ec2-role"
]
},
"Action": [
"s3:PutObject",
"s3:GetObject"
],
"Resource": [
"arn:aws:s3:::sls-user-data/*"
]
}
]
}
Data Pipeline使用
创建一个管道
进入AWS Data Pipeline的控制台,创建一个数据管道。参数的配置如下,source选择Export DynamoDB table to S3,输入表名,选择创建的S3的Bucket,注意下面的区域需要选择DynamoDB表所在的区域。本示例中调度类型选择的是管道激活,最后选择上面创建的两个角色即可完整任务的创建。
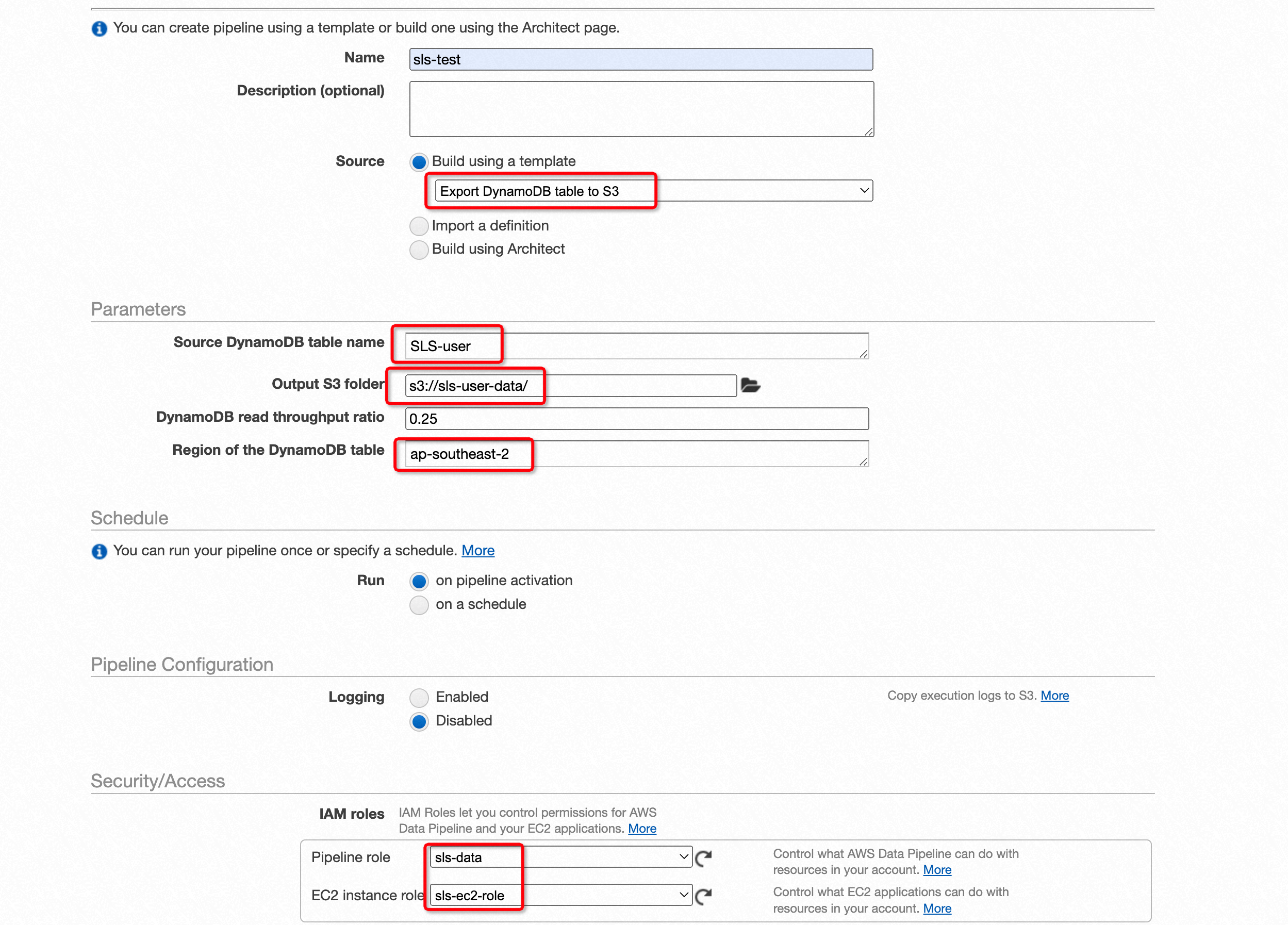
数据管道刚创建好后,管道的状态会变成WAITING_FOR_RUNNER,这是因为管道的任务需要初始化一些计算资源,等一段时间后管道状态就会变成HEALTHY,此时从DynamoDB向S3传输数据的任务开始执行。在管道的调度状态变成FINISHED以后,就表明数据传输已经完成。

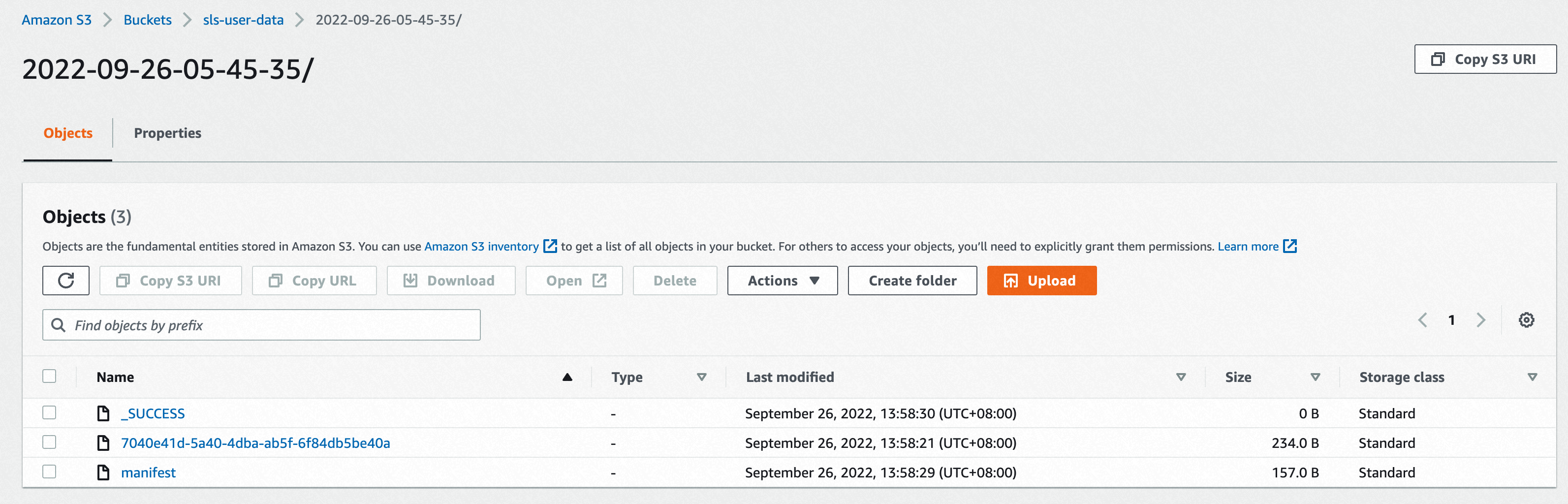
最终可以在S3的Bucket下看到传输过来的数据。
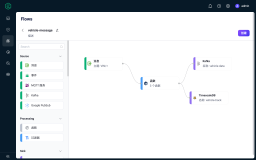
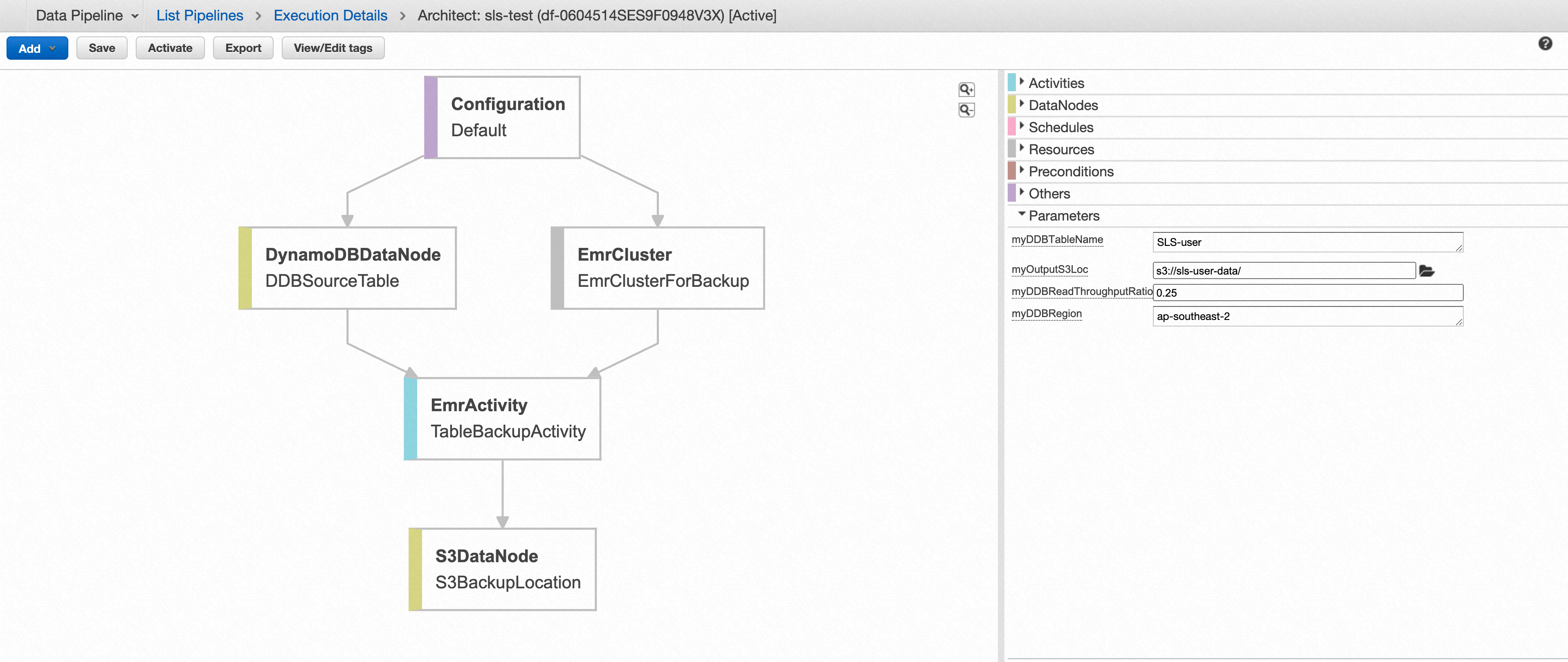
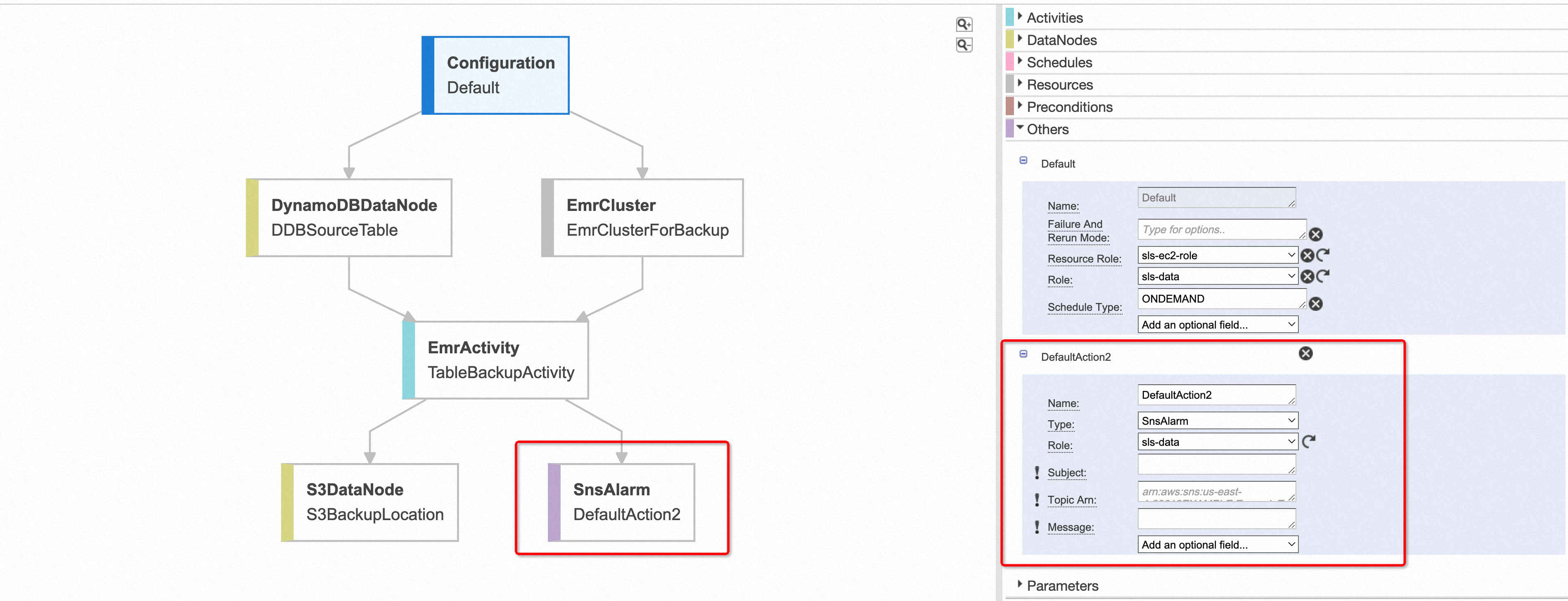
Data Pipeline的Architect页面
Data Pipeline的可视化架构页面是其操作方便很重要的原因之一。数据管道任务创建成功后,可以点击Edit Pipeline进入Architect页面查看整个管道数据流的流程图,数据源和数据目的地在该图中被视为数据节点,计算过程在该图中被视为活动节点。
在Architect页面主要有以下几个功能。
- 可以方便的地添加并配置数据节点或者活动节点。
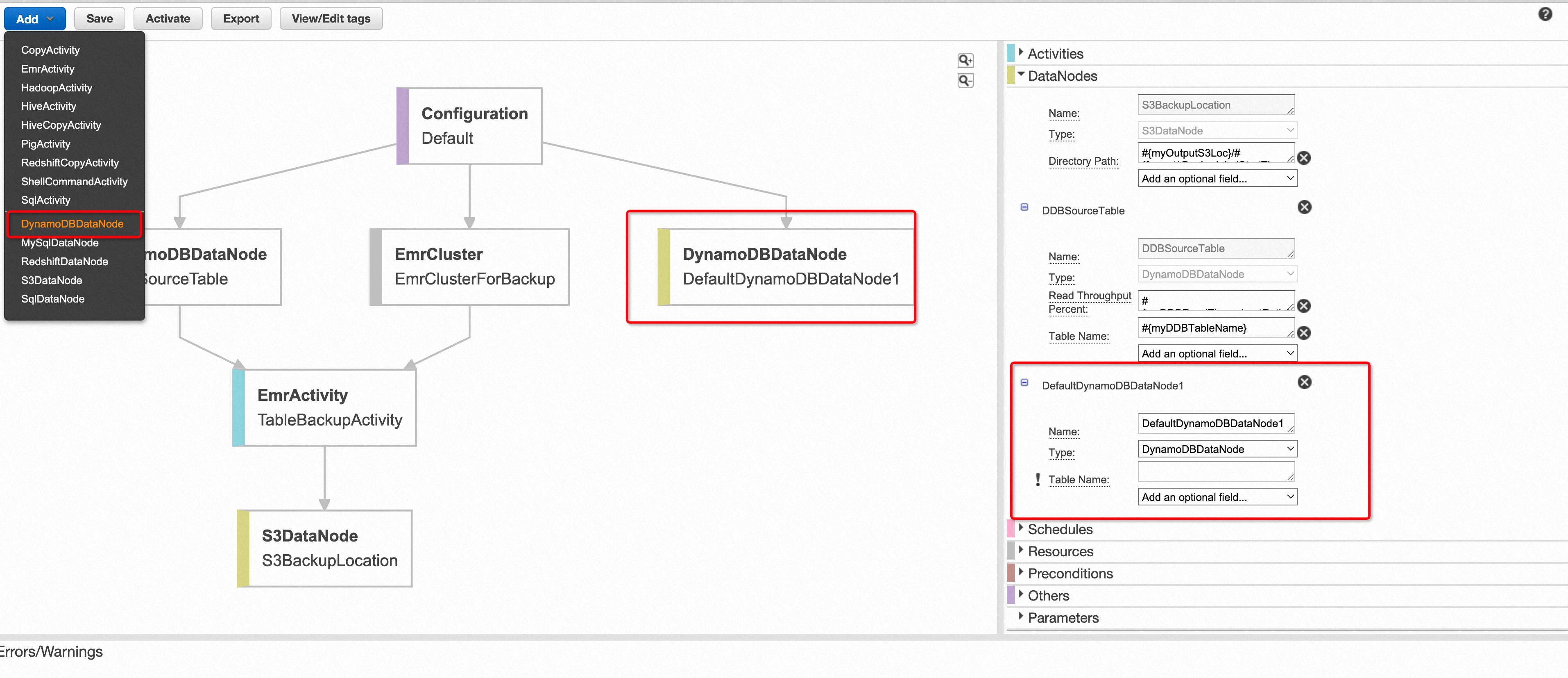
- 当因为某些配置导致管道任务出错的时候,可以很清晰地在该流程图中看到错误发生的节点以及错误原因。
- 可以为活动节点配置失败通知。
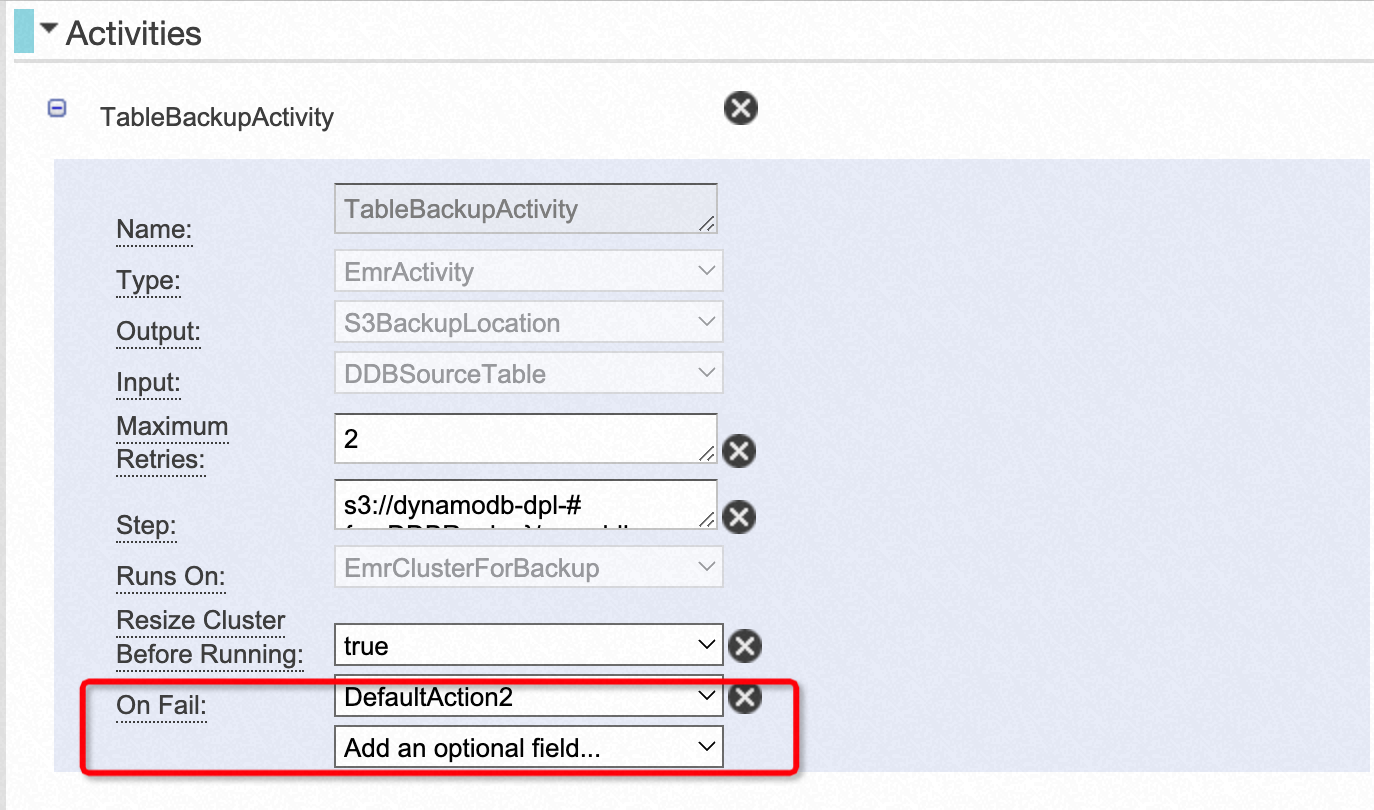
总结
AWS Data Pipeline本质是一项托管的ETL服务,用来帮助用户在不同的服务之间传输数据。其优势在于
- 操作简单,不会写代码的人也可以快速使用
- 服务灵活、拓展性高,在数据量大的情况下可以快速拓展多台机器来并行处理
- 稳定可靠,当管道任务出错时会自动重试,还可以通过SNS及时向用户发送错误信息