💨HDFS基本介绍
🎈概念
HDFS ( Hadoop Distributed File System):指适合运行在通用硬件上的 分布式文件系统。 它是一个文件系统,用于存储文件,通过统一的命名空间——目录树来定位文件 它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色;

🎈Hadoop技术体系
应用层:Hadoop Map Reduce 、Spark调度层:Hadoop YARN存储层:Hadoop HDFS
🎈文件系统和存储
🚩Windows单机文件系统🚩Linux单机文件系统🚩分布式文件系统:大容量,高可靠,低成本分布式存储系统:🚩对象存储🚩文件系统🚩块存储🚩数据库
💨功能特性及优缺点
🎈分布式
受GFS启发,用Java实现的开源系统,没有实现完整的POSIX文件系统语义。
🎈容错
自动处理、规避多种错误场景,例如常见的网络错误、机器宕机等。
🎈高可用
一主多备模式实现元数据高可用,数据多副本实现用户数据的高可用
🎈高吞吐
Client直接从DataNode读取用户数据,服务端支持海量client并发读写
🎈可扩展
支持联邦集群模式,DataNode数量可达 10w级别
🎈廉价
只需要通用硬件,不需要定制高端的昂贵硬件设备
HDFS适用于大文件存储、流式数据访问,适合那些有着超大数据集(large data set)的应用程序;不适合大量小文件、随机写入、低延迟读取
数据访问。运行在HDFS之上的应用程序必须流式地访问它们的数据集,它不是运行在普通文件系统之上的普通程序。HDFS被设计成适合批量处理的,而不是用户交互式的。重点是在数据吞吐量,而不是数据访问的反应时间 。
简单一致性模型。大部分的HDFS程序对文件操作需要的是一次写多次读取的操作模式。一个文件一旦创建、写入、关闭之后就不需要修改了。这个假定简单化了数据一致的问题,并使高吞吐量的数据访问变得可能。一个Map-Reduce程序或者网络爬虫程序都可以完美地适合这个模型。
🎈优点:
1)适合存储非常大的文件2)适合流式数据读取,即适合“只写一次,读多次”的数据处理模式3)适合部署在廉价的机器上
🎈缺点:
1)不适合存储大量的小文件,因为受Namenode内存大小限制2)不适合实时数据读取,高吞吐量和实时性是相悖的,HDFS选择前者3)不适合需要经常修改数据的场景
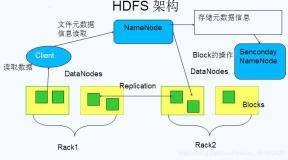
💨架构原理
🎈HDFS组件

🎈Client写流程
1)Client向NameNode请求写入新数据块2)NameNode返回副本目标DN列表(<dn08, dn01, dn06> )3)Client向DataNode写数据块4)dn08和dn01互传ACK ,dn01和dn06互传ACK5)dn08向dn01传Flush,dn01向dn06传Flush6)Client向NameNode发送complete请求
🎈Client读流程
1)Client向NameNode发送getBlockL ocations请求2)NameNode返回返回副本目标DN列表(<dn08, dn01, dn06> )3)Client向DataNode写数据块
写数据:客户端要向HDFS写数据,首先要跟namenode通信以确认可以写文件并获得接收文件block的datanode,然后,客户端按顺序将文件逐个block传递给相应datanode
读数据:客户端将要读取的文件路径发送给namenode,namenode获取文件的元信息(主要是block的存放位置信息)返回给客户端
💨元数据节点NameNode
🎈维护目录树
维护目录树的增删改查操作,保证所有修改都能持久化,以便机器掉电不会造成数据丢失或不一致。
🎈维护文件和数据块的关系
文件被切分成多个块,文件以数据块为单位进行多副本存放
🎈维护文件块存放节点信息
通过接收DataNode的心跳汇报信息,维护集群节点的拓扑结构和每个文件块所有副本所在的DataNode类表。
🎈分配新文件存放节点
Client创建新的文件时候,需要有NameNode来确定分配目标DataNode
💨数据结点DataNode
🎈数据块存取
DataNode需要高效实现对数据块在硬盘上的存取
🎈心跳汇报
把存放在本机的数据块列表发送给NameNode,以便NameNode能维护数据块的位置信息,同时让NameNode确定该节点处于正常存活状态
🎈副本复制
1)数据写入时Pipeline IO操作
2)机器故障时补全副本
💨关键设计
💨分布式存储系统基本概念
🎈容错能力
能够处理绝大部分异常场景,例如服务器宕机、网络异常、磁盘故障、网络超时等。
🎈致性模型
为了实现容错,数据必须多副本存放,一致性要解决的问题是如何保障这多个副本的内容都是一致的。
🎈可扩展性
分布式存储系统需要具备横向扩张scale-out的能力。
🎈节点体系
常见的有主从模式、对等模式等,不管哪种模式,高可用是必须的功能。
🎈数据放置
系统是由多个节点组成,数据是多个副本存放时,需要考虑数据存放的策略。
🎈单机存储引擎
在绝大部分存储系统中,数据都是需要落盘持久化,单机引擎需要解决的是根据系统特点,如何高效得存取硬盘数据。
💨NameNode目录树维护
🎈fsimage
1)文件系统目录树2)完整的存放在内存中3)定时存放到硬盘上4)修改是只会修改内存中的目录树
🎈EditLog
1)目录树的修改日志2)client更新目录树需要持久化EditL og后才能表示更新成功3)EditLog可存放在本地文件系统,也可存放在专用系统上4)NameNode HA方案个关键 点就是如何实现EditLog共享
💨NameNode数据放置
🎈数据块信息维护
1)目录树保存每个文件的块id2)NameNode维护了每个数据块所在的节点信息3)NameNode根据DataNode汇报的信息动态维护位置信息4)NameNode不会持久化数据块位置信息
🎈数据放置策略
1)新数据存放到哪写节点
2)数据均衡需要怎么合理搬迁数据
3)3个副本怎么合理放置
💨DataNode
🎈数据块的硬盘存放
1)文件在NameNode已分割成block2)DataNode以block为单位对数据进行存取
🎈启动扫盘
1)DataNode需要知道本机存放了哪些数据块2)启动时把本机硬盘上的数据块列表加载在内存中
💨HDFS写异常处理
🎈Lease Recovery
租约:Client要修改一个文件时, 需要通过NameNode.上锁,这个锁就是租约(L ease)。情景:文件写了一半,client自己挂掉了。可能产生的问题:副本不一致,Lease无法释放解决方法:Lease Recovery
🎈Pipeline Recovery
情景:文件写入过程中,DataNode侧出现异常挂掉了。
异常出现的时机:创建连接时,数据传输时,complete阶段
解决方法:Pipeline Recovery
💨Client读异常处理
情景:读取文件的过程,DataNode 侧出现异常挂掉了
解决方法:节点Failover
增强情景:节点半死不过,读取很慢
💨控制面建设
🎈可观测性设施
指标埋点数据采集访问日志数据分析
🎈运维体系建设
运维操作需要平台化NameNode操作复杂DataNode机器规模庞大组件控制面API